Популярные веб-архивы и их применение
Содержание:
- Индексация веб-страниц в интернете
- Как посмотреть историю посещения сайтов? Как очистить историю во всех браузерах?
- Как посмотреть историю в Яндекс браузере на Андроид
- Как восстановить страницу через Историю
- Что входит в историю
- Где хранится история Яндекс веб-обозревателя на компьютере
- Как посмотреть историю сайта
- Где хранятся сведения
- Как увидеть историю из файла в Яндекс браузере
- Проекты
- Как посмотреть сайт в прошлом
- Блокировка Архива Интернета
- Возможности использования веб-архивов
- Всемирный веб архив сайтов интернета
- Всемирный Веб архив сайтов интернета
- 5 способов открыть удаленную историю браузера
- Заключение
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Как посмотреть историю посещения сайтов? Как очистить историю во всех браузерах?
Доброго времени суток.
Оказывается еще далеко не все пользователи знают, что по умолчанию любой браузер запоминает историю посещенных вами страничек. И даже если прошло несколько недель, а может и месяцев, открыв журнал учета посещений браузера — можно найти заветную страничку (если конечно, вы не очищали историю посещений…).
Вообще, опция эта довольно полезна: можно найти ранее посещенный сайт (если забыли добавить его в избранное), или посмотреть чем интересуются другие пользователи, сидящие за данным ПК. В этой небольшой статье я хочу показать как можно посмотреть историю в популярных браузерах, а так же как ее быстро и легко очистить. И так…
Как посмотреть историю посещения сайтов в браузере…
Google Chrome
В Chrome в правом верхнем углу окна есть «кнопка со списком», при нажатии на которую открывается контекстное меню: в нем нужно выбрать пункт «История«. Кстати, поддерживаются и так называемые быстрые клавиши: Ctrl+H (см. рис. 1).
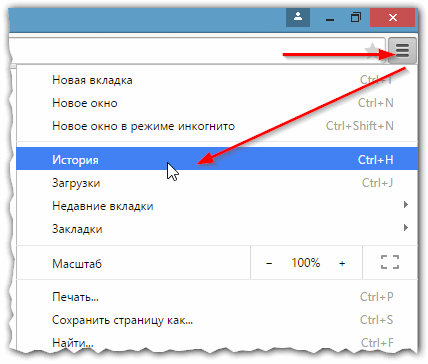
Рис. 1 Google Chrome
Сама история представляет из себя обычный список адресов интернет страничек, которые отсортированы в зависимости от даты посещения. Довольно легко найти сайты, которые посещал, например, вчера (см. рис. 2).

Рис. 2 История в Chrome
Firefox
Второй по популярности (после Chrome) браузер на начало 2020г. Чтобы зайти в журнал можно нажать быстрые кнопки (Ctrl+Shift+H), а можно открыть меню «Журнал» и из контекстного меню выбрать пункт «Показать весь журнал«.
Кстати, если у вас нет верхнего меню (файл, правка, вид, журнал…) — просто нажмите левую кнопку «ALT» на клавиатуре (см. рис. 3).
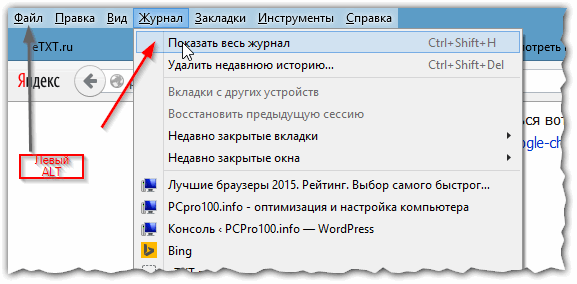
Рис. 3 открытие журнала в Firefox
Кстати, на мой взгляд в Firefox самая удобная библиотека посещения: можно выбирать ссылки хоть вчерашние, хоть за последние 7 дней, хоть за последний месяц. Очень удобно при поиске!
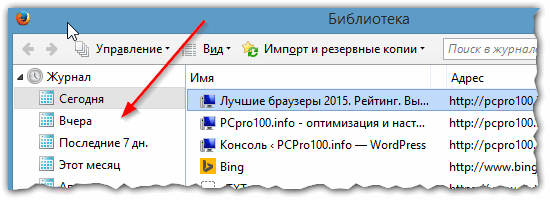
Рис. 4 Библиотека посещения в Firefox
Opera
В браузере Opera просмотреть историю очень просто: щелкаете по одноименному значку в левом верхнем углу и из контекстного меню выбираете пункт «История» (кстати, поддерживаются и быстрые клавиши Ctrl+H).

Рис. 5 Просмотр истории в Opera
Яндекс-браузер
Яндекс-браузер очень сильно напоминает Chrome, поэтому здесь практически все так же: щелкаете в правом верхнем углу экрана по значку «списка» и выбираете пункт «История/Менеджер истории» (или нажмите просто кнопки Ctrl+H, см. рис. 6).
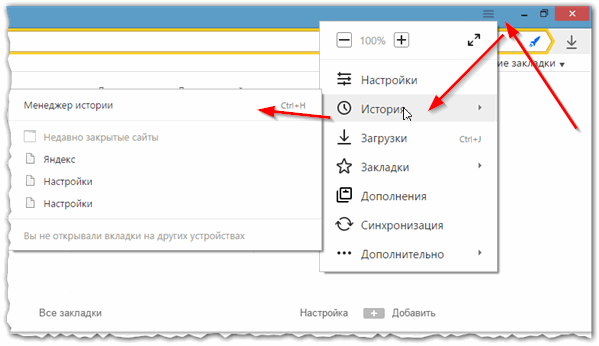
Рис. 6 просмотр истории посещения в Yandex-браузере
Internet Explorer
Ну и последний браузер, который не мог просто не включить в обзор. Чтобы посмотреть в нем историю — достаточно щелкнуть по значку «звездочка» на панели инструментов: далее должно появиться боковое меню в котором просто выбираете раздел «Журнал».
Кстати, на мой взгляд не совсем логично прятать историю посещения под «звездочку», которая у большинства пользователей ассоциируется с избранным…
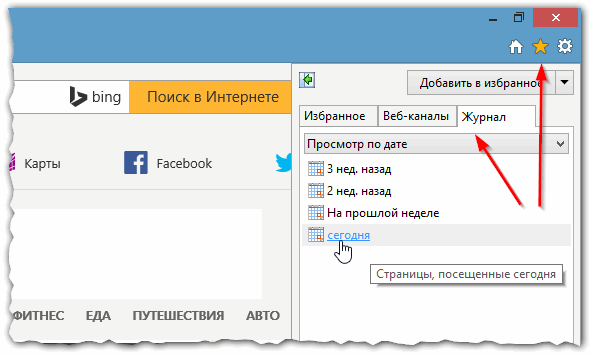
Рис. 7 Internet Explorer…
Как очистить историю во всех браузерах сразу
Можно, конечно, вручную все удалять из журнала, если вы не хотите, чтобы кто-то мог просмотреть вашу историю. А можно просто использовать специальные утилиты, которые за считанные секунды (иногда минуты) очистят всю историю во всех браузерах!
Пользоваться утилитой очень просто: запустили утилиту, нажали кнопку анализа, затем поставили галочки где нужно и нажали кнопку очистки (кстати, история браузера — это Internet History).
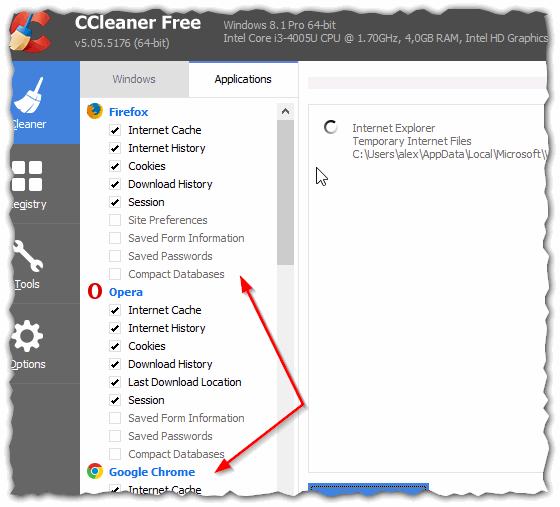
Рис. 8 CCleaner — чистка истории.
В данном обзоре не мог не упомянуть и еще одну утилиту, которая порой показывает еще лучшие результаты по очистке диска — Wise Disk Cleaner.
Пользоваться утилитой так же просто (к тому же она поддерживает русский язык) — сначала нужно нажать кнопку анализа, затем согласиться с теми пунктами по очистке, которая назначила программа, а затем нажать кнопку очистки.
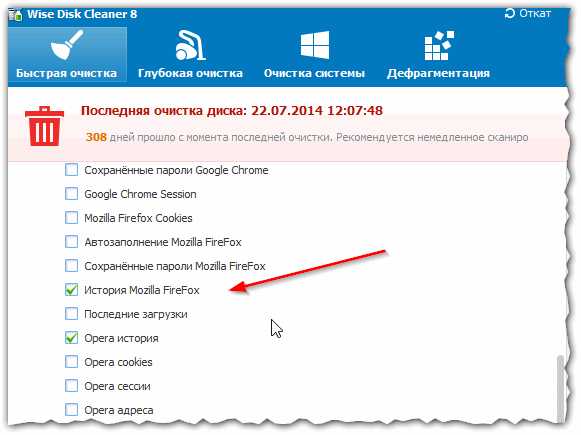
Рис. 9 Wise Disk Cleaner 8
На этом у меня все, всем удачи!
Как посмотреть историю в Яндекс браузере на Андроид
После прочтения предыдущего раздела мы уже можем открыть историю в Яндекс браузере на Андроид. Попав на нужную страницу, остаётся лишь исследовать раздел с историей. Отсюда можем не лишь увидеть историю в мобильном Яндекс браузере, но и перейти на любой сайт, просто коснувшись его названия из списка.
Есть ещё один хороший способ увидеть историю в Яндекс.Браузере на Андроид – воспользоваться расширением «Улучшенная история Chrome». Главный плюс способа – возможность сортировать историю по дням, в левой части страницы отображается календарь. С его помощью, можем настроить отображение истории за дни из вручную настроенной выборки. Выборочная сортировка действительно упрощает поиск по истории Яндекс веб-обозревателя на телефоне.
Как увидеть историю Yandex browser на телефоне через «Улучшенная история Chrome»:
- Переходим на официальную страницу расширения и жмём кнопку «Установить».
- Выдаём нужные дополнению права, нажимая на кнопку «Установить расширение».
-
Открываем любой сайт в мобильном Яндекс браузере (не обязательно из истории) и нажимаем на многоточие в правом нижнем углу.
- Выбираем элемент «Дополнения» и щёлкаем на лишь что установленный плагин.
- Открывается окно «Недавняя история» и выбираем «Просмотреть всю историю».
- Приближаем список и видим 2 главных элемента: календарь и список посещений. По умолчанию отображается перечень просмотренных веб-сайтов за сегодня. Выбираем дни, за которые хотим увидеть историю.
Это лучший на сегодняшний день способ открыть историю браузера Yandex на телефоне, так как в стандартной вкладке нет возможности поиска или сортировки. Если открывали ссылку давно, очень проблематично её найти стандартными средствами на смартфоне. Расширение упрощает процесс поиска.
Как восстановить страницу через Историю
Предыдущий способ подходит, если нужно срочно вернуть только что нечаянно закрытые страницы. А что делать, если надо восстановить старые вкладки?
Как раз для этого в браузере есть специальное место, где хранятся просмотренные на компьютере сайты. Называется оно История или Журнал. Там находятся все удаленные страницы не только из последнего сеанса, но и за предыдущие дни и даже недели.
Сайт может не сохраниться в Истории только по двум причинам: либо История была очищена, либо страницу открывали в режиме инкогнито.
Сейчас я покажу, как открывать сайты из Истории. Но так как у каждого браузера свои особенности, я написал для них отдельные инструкции. Щелкните по названию своей программы, чтобы быстро перейти к нужной информации.
Яндекс Браузер
Если через комбинацию клавиш не получилось вернуть закрытую вкладку в Яндексе, то на помощь придет История.
Чтобы зайти в Историю Яндекс браузера, нажмите сочетание клавиш Ctrl + H или щелкните мышкой по кнопке с тремя горизонтальными линиями.
В новой вкладке появится список всех страниц, которые раньше открывали на этом компьютере. Вверху будут недавно просмотренные сайты, а если опуститься ниже, покажутся страницы за предыдущие дни. Чтобы открыть нужный сайт, просто кликните по нему.
В ситуации, когда быстро найти вкладку не получается, воспользуйтесь поиском. Он находится в правом верхнем углу, над списком сайтов. Напечатайте туда ключевое слово и нажмите Enter.
На заметку: можно искать не только по целому слову, но и по части слова или по названию/адресу сайта.
Например, мне нужно найти сайт компьютерного обучения, который я когда-то отрывал. По слову «обучение» поиск ничего не выдал. Значит, нужно напечатать какое-то другое определяющее слово, например, компьютер или комп.
Google Chrome
Все вкладки, которые вы раньше открывали в Google Chrome, можно восстановить после закрытия. Они надежно хранятся в специальном отсеке под названием «История». Причем там находятся не только адреса, которые вы просматривали сегодня или вчера, но и неделю назад.
Зайти в Историю Хрома можно через сочетание клавиш Ctrl + H или через кнопку настроек – три вертикальные точки в правом верхнем углу программы.
В Истории показаны все сайты, которые открывали в Google Chrome за последнее время. Список отсортирован по дням, часам и минутам. Чтобы перейти на страницу, просто щелкните по ней мышкой.
Если найти нужный сайт не удается, то, чтобы восстановить вкладку, воспользуйтесь поиском.
Например, несколько дней назад я открывал инструкцию по входу в электронную почту. Но забыл, когда точно это было. В таком случае просто печатаю определяющее слово в строке «Искать в Истории». А еще лучше не целое слово, а его основную часть. В моем случае это «почт».
Кроме того, здесь можно искать и по адресу сайта. Достаточно напечатать лишь часть адреса и Гугл Хром покажет все совпадения.
Mozilla Firefox
В программе Мозила есть возможность вернуть последнюю вкладку даже после сбоя и перезагрузки компьютера. Для этого нажмите кнопку с тремя горизонтальными линиями в верхнем правом углу и выберите «Восстановить предыдущую сессию».
Другие ранее закрытые страницы можно вернуть через Журнал: → Библиотека → Журнал (пример 1, пример 2).
В окне появится список страниц, которые недавно открывали. Здесь же можно вернуть любую из них – достаточно просто по ней щелкнуть.
А чтобы посмотреть все недавно закрытые сайты, нажмите на «Показать весь журнал» внизу списка.
Откроется новое окно со списком адресов. С левой стороны можно выбрать дату. А вверху есть удобный поиск по журналу.
Opera и другие браузеры
Opera. Все страницы, которые вы раньше открывали в Опере, хранятся в Истории. Перейти в нее можно через кнопку Меню в верхнем левом углу программы.
Для поиска страницы используйте поле «Искать в истории» над списком сайтов. Напечатайте туда ключевое слово, и Опера покажет все страницы, в названии которых оно встречается.
Искать в Истории можно не только по названию статьи, но и по адресу сайта. Для этого наберите часть адреса, и программа покажет все подходящие варианты.
Internet Explorer. В Эксплорере для восстановления старых вкладок используйте Журнал. Находится он под кнопкой с изображением звездочки в правом верхнем углу.
В Журнале хранятся все сайты, которые вы раньше открывали в IE. Для удобства они рассортированы по дням. Но эту сортировку можно поменять, выбрав другой порядок из верхнего выпадающего списка (пример).
Safari. В браузере Сафари на Маке для отображения недавно закрытых сайтов щелкните правой клавишей мыши по кнопке, которая открывает новые вкладки. То есть по иконке со знаком плюс в верхнем правом углу программы.
Еще для возврата последних страниц можно использовать комбинацию клавиш Cmd + Shift + T или же Cmd + Z.
Что входит в историю
Для удобства пользователей в браузере накапливается история, которую потом можно просмотреть и впоследствии удалить. Он включает в себя следующие элементы:
- Журнал загрузок и посещений – это список ресурсов, которые посетил пользователь с момента последней очистки.
- Формы и журнал поиска. Сюда входит информация, которая была введена в поля для заполнения на сайтах (для форм), и информация, введенная в поисковые (поисковые) строки).
- Файлы cookie: информация о посещенных страницах, то есть о выполненных настройках, статусе доступа и т.д. Злоумышленник может получить доступ к истории браузера, получить эту информацию и использовать ее против пользователя. Вот почему мы рекомендуем вам удалить эту информацию. Рекомендуется удалить в обновленной версии браузера.
- Кэш – временные файлы (изображения, текст, видео и другие данные), загружаемые из Интернета. Они сохраняются для ускорения загрузки ранее посещенных страниц. Мы рекомендуем периодически очищать кеш.
- Активная сессия. Если кто-то вошел в ваш профиль, а затем очистил свою историю, вам нужно будет снова войти в систему.
- Настройки интернет-ресурса. Это включает кодировку текста, масштаб, разрешение.
- Информация об офлайн-сайтах. Если у вас есть разрешение, ресурс может сохранять файлы на ваш компьютер, чтобы вы могли использовать их позже, не подключаясь к сети.
Все эти данные можно просмотреть в истории посещений. Конфигурация может отличаться в зависимости от типа браузера.
Где хранится история Яндекс веб-обозревателя на компьютере
Не секрет, что вся информация, отображаемая в браузере, находится где-то на вашем жестком диске. Понимая это, мы можем узнать, где хранится история браузера Яндекса в виде файла. Забегая вперед, мы можем открыть этот файл с помощью сторонней утилиты и увидеть все его содержимое.
Где в Яндекс браузере хранится история просмотров? В файлах профиля вашего веб-браузера легко найти:
- Идем по пути C: Users ИМЯ ПК AppData Local Yandex YandexBrowser User Data.
- Откройте папку «По умолчанию» или «Профиль 1». Название зависит от наличия профилей и авторизации в Яндекс.
- Ищем файл под названием «История».
Как посмотреть историю сайта
Конечно, после выполнения модернизации сайта есть желание его сравнить с теми версиями сайта, которые были раньше. Но если не знаешь, возникает вопрос, как посмотреть историю сайта, где её посмотреть? На помощь может прийти сервис archive.org. На сервисе archive.org собрано более, чем пол триллиона сайтов. Причем, каждый сайт (блог) представлен там, в различный период времени.
Например, Вы открываете сайт и хотите посмотреть, как он выглядел в феврале 2013 года. Вы действительно его увидите таким, каким он был в тот период времени. Опубликованные на блоге статьи сможете открыть и прочитать их, даже если автор эти статьи уже удалил. Вы можете проверить историю сайта за каждый месяц, за каждый год. Представляете, какой объём информации хранит сервис archive.org!

Многие люди пишут на форумах — archive.org заблокирован, как зайти? Действительно, если просто зайти по адресу первого сайта, то сервис archive.org почему то работает не корректно.
Итак, открывается окно сервиса archive.org, далее в поле нужно ввести доменное имя своего сайта и нажать кнопку «Browse history». Теперь выбираем дату архивирования своего сайта из встроенного календаря, сначала выбираем год, далее месяц и день.
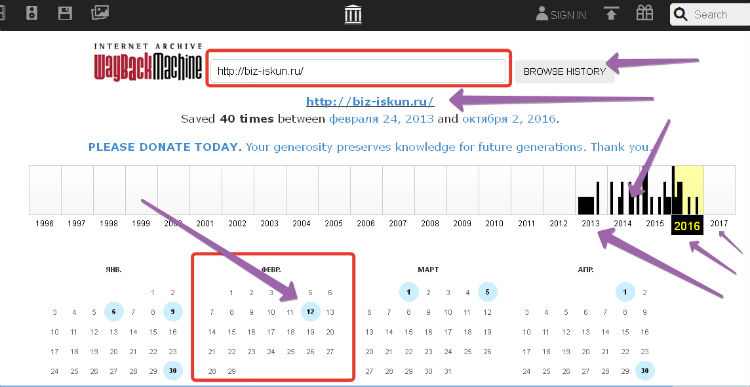
День нужно выбирать тот, который отмечен голубым кружочком – нажимаем на дату. Теперь можем посмотреть историю нашего ресурса. Мы можем посмотреть историю сайта своего или чужого. А сейчас можете посмотреть видео, как узнать историю ресурса с помощью сервиса archive.org:
Где хранятся сведения
Выше мы видели, как просматривать информацию о прошлых посещениях. Не менее важный вопрос – где на вашем компьютере хранится история браузера. Во всех случаях путь к папке данных начинается с C: UsersAdminAppDataLocal, а дальнейший путь индивидуален для разных браузеров:
- Opera – Программное обеспечение Opera Opera StableCache.
- IE – MicrosoftWindowsINetCache.
- Mozilla – FirefoxProfileszxcvb5678.defaultcache2entries.
- Google Chrome – GoogleChromeUser DataDefaultCache.
- Яндекс – ЯндексБраузер Пользовательские данныеDefaultCache.

Зная, где на вашем компьютере находится история браузера, вы можете удалить ее напрямую, не используя описанные выше методы. Все, что вам нужно, это перейти по ссылкам выше и выполнить очистку. Но при таком подходе сложнее выполнить точечное устранение в конкретную дату. Для решения такой проблемы лучше использовать методы, описанные выше: через меню, специальное сочетание клавиш или комбинацию клавиш.
Как увидеть историю из файла в Яндекс браузере
Сама история представляет собой обычную базу данных SQL3. Её может открыть любой обработчик баз данных. Есть и один недостаток, большинство подобных прог поставляются на английском языке и требуют установки локального сервера на Apache. Чтобы избежать перечисленных трудностей, можем воспользоваться хорошей утилитой DB Browser for SQLite.
Как ознакомиться с содержимым файла истории от Яндекс браузера:
- Скачиваем нужную прогу с сайта разработчика (в нижней части страницы есть кнопочки для загрузки 32-х и 64-х битных версий программы).
- Устанавливаем и открываем программу.
- Жмём на кнопку «Файл» в левом углу и выбираем «Открыть базу данных».
- В правом нижнем углу щёлкаем на «Файлы SQLite баз данных…» и меняем на «Все файлы (*)».
- Через «Проводник» находим файлик history (путь указан в прошлом разделе) и открываем его.
- Переходим во вкладку «Данные» в верхней области рабочего окна приложения.
- В строке «Table:» выбираем «urls».
Перед нами открывается таблица сайтов со всей данными из истории браузера. Тут указаны:
- url – ссылка на посещённую страницу;
- title – название просмотренной страницы;
- visit_count – количество входов на данную страницу;
- last_visit_time – время последнего входа на страницу. Есть одна проблемка – время представлено в UNIX-формате, его придётся переводить в понятную для человека дату. С этим поможет сайт cy-pr.com. Копируем время из столбца и вставляем на сайт, получаем время посещения с точностью до секунд.
Прочие столбцы таблицы не представляют особой ценности.
Проекты
Wayback Machine
Логотип Wayback Machine
Wayback Machine — веб-сервис Архива. Содержание веб-страниц время от времени фиксируется c помощью бота или при ручном указании посетителем сайта адреса страницы для фиксации. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует.
Легальность
На сервис не раз подавались судебные иски в связи с тем, что публикация контента может быть нелегальной. По этой причине сервис удаляет материалы из публичного доступа по требованию их правообладателей или, если доступ к страницам сайтов не разрешён в файле robots.txt владельцами этих сайтов.
Книга, изготовленная в течение 20 минут в рамках проекта Book-on-demand, на основе электронной книги из Архива
В 2002 году часть архивных копий веб-страниц, содержащих критику саентологии, была удалена из архива с пояснением, что это было сделано по «просьбе владельцев сайта». В дальнейшем выяснилось, что этого потребовали юристы Церкви саентологии, тогда как настоящие владельцы сайта не желали удаления своих материалов. Некоторые пользователи сочли это проявлением интернет-цензуры.
Сервис веб-архива может использоваться в качестве меры борьбы с блокировками доступа к сайтам: как и сервис кэшированных копий страниц от поисковых систем, Архив Интернета позволяет ознакомиться с более ранними копиями популярных страниц. Однако использование Архива и кэшей в таких целях требует специальных усилий от пользователя и позволяет получить доступ не ко всем сайтам.
Open Library
Книжный сканер Архива
Open Library — общественный проект по сканированию всех книг в мире, к которому приступила Internet Archive в октябре 2005 года. На февраль 2010 года библиотека содержит в открытом доступе 1 миллион 165 тысяч книг, в каталог библиотеки занесено больше 22 млн изданий. По данным на 2008 год, Архиву принадлежат 13 центров оцифровки в крупных библиотеках. По оценке Internet Archive на ноябрь 2008 года, коллекция составила более 0,5 петабайта, включая изображения и документы в формате PDF. Коллекция постоянно растёт, так как библиотека сканирует около 1000 книг в день.
Scan-on-demand — бесплатная оцифровка желаемых публикаций из фондов Бостонской общественной библиотеки, относится к проекту «Открытая библиотека».
Собрание фильмов, аудио, текстов и программного обеспечения, которые являются общественным достоянием или распространяются под лицензией Creative Commons.
Как посмотреть сайт в прошлом
Есть несколько сервисов, в которых можно посмотреть, как менялось визуальное оформление страниц сайта, его структуру страниц и контент, положение в поисковой выдаче и какие изменения вносились в регистрационные данные за время существования ресурса.
Сервис Веб-архив
При его использовании сначала заходим на сайт https://web.archive.org/ и после вводим адрес страницы.

График ниже показывает количество сохранений: первое было в 1998 году.

Дни, в которые были сохранения, отмечены кружком. При клике на время во всплывающем окне, открывается сохраненная версия. Показано ниже:

Как выгрузить сайт из ВебАрхива, расскажем дальше.
Сервис Whois History
Для его использования заходим на сайт http://whoishistory.ru/ и вводим данные в поиске по доменам и IP, либо по домену:

Сервис покажет информацию по данным Whois, где собраны сведения от всех регистраторов доменных имен. Посмотреть можно возраст домена, кто владелец, какие изменения вносились в регистрационные данные и т.д.

Блокировка Архива Интернета
В России
| Внешние изображения |
|---|
В октябре 2014 года Роскомнадзор заблокировал на территории РФ доступ к некоторым страницам Архива Интернета за видеоролик «Звон мечей» экстремистской группировки «Исламское государство Ирака и Леванта» (нынешнее название — «Исламское государство»). Ранее блокировались только ссылки на отдельные материалы в архиве, однако 24 октября 2014 года в реестр запрещённых сайтов временно был включён сам домен и его IP-адрес.
16 июня 2015 года на основании статьи 15.3 закона «Об информации, информационных технологиях и о защите информации» генпрокуратура РФ приняла решение о блокировке страницы «Одиночный джихад в России», содержащей, по её мнению, «призывы к массовым беспорядкам, осуществлению экстремистской деятельности, участию в массовых мероприятиях, проводимых с нарушением установленного порядка», в действительности на территории России был заблокирован доступ ко всему сайту, кроме .
С апреля 2016 года Роскомнадзор решил убрать сайт из блокировок, и он доступен в России.
По состоянию на 22 августа 2019 года в Мосгорсуде находятся на рассмотрении иски Ассоциации по защите авторских прав в интернете (АЗАПИ), в которых заявлено требование о блокировке интернет-портала archive.org на территории России в связи с нарушениями авторских прав.
В других странах СНГ
Архив Интернета был заблокирован на территории Казахстана в 2015 году (по состоянию на 26 июля 2021 года сайт остаётся недоступным для казахстанцев).
Также в 2017 году сообщалось о блокировках Архива Интернета в Киргизии.
archive.org также заблокирован на территории Таджикистана[источник не указан 192 дня].
В Индии
В Индии Архив был частично заблокирован судебным решением в августе 2017 года. Решение Madras High Court перечисляло 2,6 тыс. адресов в сети Интернет, которые способствовали пиратскому распространению ряда фильмов двух местных кинокомпаний. Представители проекта безуспешно пытались связаться с министерствами.
Возможности использования веб-архивов
Возможности сохраненной истории
Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива
Фиксация в веб-архиве за 2011–2016 годы
Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта
Уникальный контент из веб-архива
Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URLв строку поиска.
- На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата, это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.
Всемирный веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.

Главная страница сайта Archive.org
5 способов открыть удаленную историю браузера
Прежде чем перейти к изучению способов просмотра удаленных записей журнала браузера, рассмотрите условия, при которых это будет невозможно.
Когда восстановить журнал не получится
На компьютере или ноутбуке часто бывает сложно удалить историю браузера, чтобы впоследствии ее нельзя было восстановить хотя бы частично. Кроме того, каждый метод восстановления имеет свои условия, при которых он не подходит для чтения удаленных записей из реестра. Рассмотрим от самого простого к самому сложному:
История просмотров с использованием файлов cookie:
записи с сайтов, которые не используют этот тип файлов, сохраняться не будут.
при удалении реестра вы установили флажок рядом со словом «удалить cookie»;
Восстановить с помощью браузера на другом компьютере:
учетная запись была синхронизирована после очистки на обоих компьютерах.
С учетной записью Google (только в Google Chrome):
отключена возможность сохранять историю браузера;
очистил историю действий в аккаунте.
синхронизация отключена;
Использование программного обеспечения для восстановления данных с жесткого диска:
восстановление на SSD с технологиями TRIM после перезагрузки системы.
диск полностью отформатирован;
Поиск в кэше DNS:
кэш системного доменного имени был очищен (например, с помощью очистителей реестра).
Просмотр истории с помощью cooki e
Самый быстрый способ найти интересующий сайт – из журнала. Здесь и далее я покажу на примере Google Chrome. Чтобы использовать этот метод, следуйте инструкциям:
- Вызвать меню браузера и перейти в раздел «Настройки».
- Слегка прокрутите страницу, пока не дойдете до раздела «Конфиденциальность и безопасность».
- Затем выберите «Файлы cookie и другие данные сайта».
- В новом меню выберите Все файлы cookie и данные сайтов».
В этом разделе хранятся записи обо всех сайтах, данные которых зарегистрированы на вашем компьютере, и они отсортированы в алфавитном порядке, а не в хронологическом порядке. Чтобы найти здесь интересующую веб-страницу, вам необходимо знать хотя бы приблизительно ее адрес.
При помощи браузера на другом компьютере
Для использования этого метода необходимо выполнение 3 условий:
- оба браузера должны быть связаны с учетной записью;
- оба компьютера (например, ПК и ноутбук) нуждаются в доступе в Интернет;
- браузер должен поддерживать синхронизацию;
Чтобы просмотреть журнал на другом компьютере в Google Chrome, перейдите на вкладку журнала и выберите «Вкладки с других устройств» в меню слева.
Важно действовать быстро. Синхронизация между устройствами не мгновенная
Если вы удалили историю на одном компьютере, она некоторое время будет отображаться на другом.
История посещения сайтов на странице «Мои действия» в настройках аккаунта Гугл
В этом разделе хранятся записи обо всех действиях приложений, программ и устройств, связанных с учетной записью Google. Обратной стороной является то, что не все адреса посещаемых вами сайтов сохраняются, а это значит, что восстановить всю историю вашего браузера не получится. Однако есть шанс найти нужную веб-страницу.
Чтобы просмотреть элементы в разделе «Мои действия» со своего компьютера, перейдите в историю браузера Chrome, затем перейдите на myactivity.google.com в нижней части левого окна.
Недавно посещенные веб-сайты не будут отображаться сразу. Не спешите злиться, если вы не нашли нужную страницу, возможно, подождать стоит.
Заключение
Архивы страниц Глобальной сети могут хранить в себе неожиданные экземпляры, ушедшей в прошлое, эпохи развития HTML-дизайна. Разумеется, манипуляций с чистым кодом сегодня производится уже намного меньше. Для большинства необходимых действий были разработаны визуально понятные и удобные инструменты, которые избавляют вас от необходимости знать код и уметь его писать и редактировать. Тем не менее, плотно работая с различными сайтами, вы периодически будете сталкиваться с необходимостью ручной настройки, а значит ковыряться в исходном коде всё-таки придётся. Но для большинства пользователей и владельцев блогов по интересам, подобные умения могут оказаться абсолютно бесполезными.