Пошаговая инструкция по сбору семантического ядра
Содержание:
- Кластеризация и определение посадочных страниц
- Виды ключевых запросов
- Группировка семантического ядра для информационного сайта
- Группировка ключевых фраз
- Какими бывают поисковые запросы?
- Что такое семантическое ядро простыми словами
- Стоит ли заказывать СЯ у специалистов?
- Как группировать запросы
- Semrush
- Заключение
Кластеризация и определение посадочных страниц
Это разбиение, распределение запросов из очищенного семантического ядра по группам/кластерам на основании сходства сайтов конкурентов в выдаче поисковой системы. На сегодняшний день существует много инструментов по автоматической кластеризации, например:
- SE Ranking;
- Rush Analytics;
- Pixel Tools;
- Topvisor;
- Serpstat.
Все они приблизительно схожи по точности, потому что основаны на одних и тех же принципах. Различие только в дополнительных функциях:
- автоматическое определение посадочных страниц;
- сбор LSI-фраз;
- сбор синонимов, тематических фраз и тому подобного.
В Key Collector также можно воспользоваться инструментом автоматической кластеризации, но придётся потратить больше времени на ручную доработку.
Есть два метода автоматической кластеризации.
- Soft — все запросы кластера связаны хотя бы с одним общим (маркерным) запросом.
- Hard — каждый запрос связан со всеми запросами в своём кластере.
Универсальной методики не существует, для каждой тематики и требований необходимы свои параметры. При кластеризации также следует указывать параметр точности — обычно он в пределах значений от 3-х до 5-ти, чаще всего наилучший результат показывает = 4. Например, для нашей цели подошла soft-кластеризация с точностью 4.
Ключевые фразы в процессе кластеризации делятся на 2 основные группы.
- Коммерческие запросы — распределяются по кластерам и группам на основе сходства из поисковой выдачи.
- Информационные запросы — в дальнейшем пойдут для задач контент-маркетинга, чтобы привлекать дополнительный целевой трафик на сайт.
Несмотря на то что процесс кластеризации частично автоматизирован, за ним всегда необходимо дорабатывать вручную.
После завершения кластеризации идёт определение посадочной страницы под каждую группу запросов. Вы должны чётко представлять структуру сайта, чтобы правильно определить посадочную страницу под каждый кластер. Если на сайте нет подходящей страницы под найденный кластер, то её необходимо создать, чтобы привлечь на ресурс больше целевого трафика.
Для ускорения процесса на помощь приходят различные сервисы по определению релевантных страниц, однако, бо́льшую часть работы следует проводить в ручном режиме, чтобы ничего не упустить и лучше ориентироваться в структуре сайта.
Виды ключевых запросов
Условно ключевые запросы подразделяются на несколько групп, при этом запросы разного вида могут пересекаться.
По популярности
В разных по популярности тематиках показатели частотности будут отличаться.
- ВЧ (высокочастотные) – более 1000–5000 показов в месяц.
- СЧ (среднечастотные) – от 100–1000 показов в месяц.
- НЧ (низкочастотные) – 100–1000 показов в месяц.
- МНЧ (микронизкочастотные) – менее 100 показов в месяц.
Если ниша узкая, частотность понижается.
При создании нового ресурса лучше ориентироваться на низко- и микронизкочастотные ключевые фразы. По статистике, от 60 до 80% пользователей приходят на сайт именно по ним. Поэтому желательно собрать максимум ключей – в СЯ лучше включить все запросы, даже те, частотность которых ниже 10. Еще один важный момент: использование широкого диапазона НЧ и МНЧ может помочь в ТОП запросы средне- и высокочастотные.
По геозависимости
- Геозависимые – результат выдачи зависит от региона, где находится пользователь. Например: доставка суши, заказать такси, записаться на маникюр, где отремонтировать стиральную машину.
- Геонезависимые – запрос не привязан к региону. Например: как утеплить окна, когда лучше сажать чеснок, как избавиться от тараканов, преимущества удаленной работы.
По сезону
- Сезонные – те, которые наиболее актуальны в определенный сезон или перед каким-то мероприятием, событием. Примеры: летняя распродажа в италии 2020, как высадить рассаду в теплицу, когда пасха в 2020, как украсить квартиру на новый год. Некоторые специалисты в отдельную группу выделяют событийные запросы – такие, частотность которых возрастает в период проведения спортивных, культурных мероприятий, политических и других событий. Например: собор парижской богоматери пожар, грета тунберг в оон, состав сборной англии по футболу 2019.
- Несезонные – их частотность на протяжении года меняется незначительно. Например: как приготовить плов, как настроить вордпресс, почему нужно знать иностранные языки. По таким запросам сезонных всплесков практически не бывает.
Группировка семантического ядра для информационного сайта
При группировке семантического ядра я руководствуюсь здравой логикой, сравнивая её с выдачей.
Для информационных сайтов я не вижу смысла прибегать к кластеризации и четко следовать её требованиям. Поисковая система постоянно обучается и совершенствуется. Сегодня она показывает, что запросы “черный хлеб” и “ржаной хлеб” это разные продукты, а завтра покажет правильно, что это одно и тоже.
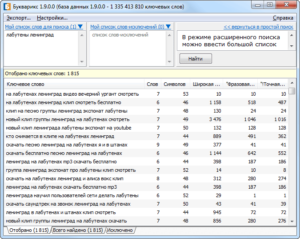
Итак, в KeyCollector у нас есть чистенький список запросов и мы собрали по нему данные из поисковой выдачи. Чтобы облегчить работу, группируем ядро средствами KeyCollector.
Заходим в анализ групп, ставим по поисковой выдаче Яндекс, сила 2. Обновляем группировку и экспортируем результаты в Excel.Таким способом у нас получилась группировка исходя из данных поисковой системы Яндекс. Но, как я писал уже выше, что надо следовать преимущественно логике и свои предположения проверять в поисковой системе, поэтому в некоторых группах могут быть запросы, которые вообще никак к ней не относятся. Их надо все пересмотреть и доработать.
Чтобы легче было дорабатывать, лучше всего оставить несколько столбцов только с нужными данными. Обычно я оставляю: базовую частотность, точную, KEI по полноте охвата, конкуренцию.
Покажу группировку на примере, чтобы было наглядно. Например, мы создаем сайт посвященный рецептам блинов. Мы увидели, что есть множество запросов связанные с молоком. Решаем, что будем делать отдельную рубрику “Рецепты блинов на молоке”. На примере этой рубрики и рассмотрим группировку.
Смотрим первую группу:Видим, что в группу “простого рецепта” попал общий запрос “тесто для блинов на молоке рецепт” – этим запросом человек не обязательно хочет найти простой рецепт. По логике, лучше всего этот запрос перенести в общую группу, которая будет вести на категорию со всеми рецептами блинов на молоке.
Но так же следует и глянуть выдачу в яндексе, что там вообще находится. Смотрим и видим, что действительно в выдаче по этому запросу есть пара страниц, которые ведут не на один рецепт, а на множество. Так же видим, что в выдаче большинство страниц ведут на один рецепт, при этом на рецепты тонких блинов. Но это же тупо, человек не обязательно хочет тонкие блины. Если бы он хотел тонкие блины, то он ввёл это в запрос. А у нас общий запрос, мы должны показать ему общую страницу, а он уже на ней должен определиться какие блины он хочет на молоке – с простым рецептом или тонкие блины или в дырочку или еще какие-то. В общем я мыслю так.
Переносим лишний запрос в другую группу, а точнее создаем выше новую “Рубрика рецепты блинов на молоке” отмечаем её другим цветом, потому что это рубрика, а в неё уже будут входить рецепты в нашем случае “простой рецепт блинов на молоке”. Тем самым у нас создается структура внутри семантики.
Все данные по группе суммируем. Бюджет можно выводить средним числом, так как это взаимодополняемые запросы, вы все их продвигаете на одной странице, а не по отдельности.
KEI1 (полнота охвата) выводим по уже известной нам формуле:
/*100
Получается вот такая красота:Данные по «рубрике рецепты блинов на молоке» еще не суммируем, потому что скорее всего туда добавятся еще запросы. Но и не исключено, что в “простой рецепт блинов на молоке” тоже еще добавятся запросы.
К тому же тут еще и затесался запрос с “тонкие блины”. Его тоже отдельно, он будет страницей к рубрике “рецепт блинов на молоке и воде”
И таким вот способом перерабатываем все ядро, в итоге получается вот так:Красным шрифтом помечены дополнительные фразы, которые имеют приставки фото, видео. Для нас это не совсем актуальные фразы. Эти фразы конкурируют с сервисами поисковых систем и трафику по ним очень мало. Но эти фразы подходят по нашему смыслу, поэтому мы их добавляем в группу.
Каждая группа помечена своим цветом. Цвет является структурой сайта, то есть уровнем вложенности страницы.
Например, если бы у нас был запрос “простой рецепт блинов на скисшем молоке”. То он бы уже шёл, как подгруппа к группе “блины на скисшем молоке” и естественно был бы выделен другим цветом. Выглядело бы это вот так:Думаю, идея с цветом понятна. Вот так создается семантика и удобная, понятная структура сайта, где все логично и имеет свой уровень вложенности.
Новые или измененные рубрики добавляем в нашу структуру в xmind.
В общем, чтобы нормально разгруппировать ядро необходимо мыслить логически, вставать на место посетителя, отвечать на вопрос – что он хочет увидеть, введя этот запрос? А также смотреть выдачу по этому запросу и принимать решение, как поступить наилучшим образом.
Группировка ключевых фраз
После сбора семантики ее следует сгруппировать. Популярная ранее группировка 1 группа = 1 ключ, так называемая SKAD (Single Keyword AdGroup), давно стала неактуальной.
Во-первых, это связано со статусом «Мало показов»: по запросам в Google и группам запросов в Яндексе, получившим статус «Мало показов», реклама перестает показываться. Во-вторых, помещать в разные группы ключи, для которых будет написано одно и то же объявление нецелесообразно.
При группировке можно придерживаться двух принципов:
-
Группировать настолько мелко, насколько можно «отрелевантить» тексты. По ключевым фразам «телевизор lg каталог» и «телевизор lg цена» вы можете написать разные заголовки, поэтому их стоит разнести в разные группы. А вот для ключа «телевизор lg» и «телевизор элджи» вы, скорее всего, напишете одинаковые заголовки, поэтому их логичнее оставить в одной группе.
-
Не выделять в отдельные группы низкочастотные ключи. Если вы собирали семантику, например, до частотности 10, то ключевое слово с такой частотой не стоит помещать в отдельную группу. Скорее всего, она получит статус «Мало показов». Официальной минимальной частотности для группы нет, но мы обычно не выделяем слова с количеством показов меньше 50.
Так как семантика получается очень объемная, то делать группировку руками трудозатратно и неэффективно. Один из способов, который мы используем: сначала для каждого ключевого слова пишем максимально релевантный заголовок и текст объявления, а потом ключевые слова, для которых креативы получились одинаковыми, объединяем в одну группу.
Если семантика не многотысячная, то можно использовать и другой способ, который удобен для небольших аккаунтов:
На скриншоте ниже незаконченная группировка. Пример дан, чтобы понять, какие слова можно использовать для фильтрации и сам принцип работы.
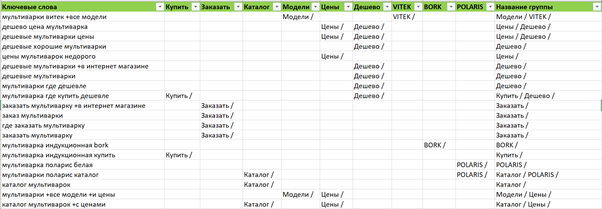
Для каждой группы в дальнейшем нужно написать релевантные заголовки и тексты, но это уже совсем другая история.
Какими бывают поисковые запросы?
Остановимся на основных классификациях запросов, без которых не обойтись при составлении семантики.
Самая главная характеристика — это конкретность формулировки запроса, то есть запрос общий (нечёткий) или чёткий. Сравните: «купить смартфон xiaomi» и «москва аренда». Первый запрос обозначает желание пользователя приобрести смартфон определённого бренда, а во втором не ясно, что нужно арендовать: квартиру, офис, гараж или что-то другое.
Второй важный фактор — геозависимость. Поисковая система старается сразу понять, насколько удовлетворение запроса пользователя зависит от его локации. Сравним: «аренда велосипеда на сутки» и «заказать чехол из китая»
В первом случае поисковой системе важно показать региональные бизнесы. Во втором случае локация не так важна
Третий фактор — тип запроса. Запросы бывают информационными («как собрать семантическое ядро»), транзакционными («заказать seo-продвижение»), навигационными («сайт про seo и маркетинг seoforge») и брендовыми («поисковая оптимизация от seoforge»)
Важность типа запросов сложно переоценить: не стоит ждать высокой конверсии от информационных запросов и большого поискового объёма от брендовых, только если вы не Кока-Кола или Адидас.
Четвёртый фактор — частотность запроса, то есть как часто пользователи ищут что-то по этому запросу. Запросы бывают высоко-, средне- и низкочастотными. В каждой нише степень частотности определяется общим спросом. Получается, что в сфере покупки чехлов для телефона запрос будет низкочастотным, если его ищут меньше 1 000 раз в месяц, а в сфере продажи станков 1 000 показов — это уже высокая частотность. Всё относительно в этом мире, но если брать общую температуру по больнице, то получается следующее:
- <1 000 — низкочастотные,
- 1 000–10 000 — среднечастотные,
- >10 000 — высокочастотные.
Пятый фактор — структура запроса, — сугубо технический, но на нём важно остановиться. У запроса всегда есть тело, а также может быть спецификатор и хвост
Тело — это общий термин или понятие (смартфон, велосипед, квартира). Спецификатор определяет потребность (купить, заказать, как выбрать), а хвост передаёт детали (в Москве, недорого, скидки).
Если упростить, то получается у запроса «купить телефон недорого» слово «телефон» является телом запроса, «купить» спецификатором, а «недорого» — хвостом.
N.B. 4 и 5 фактор зависят друг от друга, так как частотность тесно связана с длиной запроса и его конверсией. Получается, что общий запрос, состоящий только из тела, будет частотным, но менее конверсионным, чем хвостовой запрос. Из этого следует, что хвостовые запросы в среднем более конверсионные. Повышенная конверсионность связана с уже сформированной потребностью человека и пониманием, как удовлетворить свои желания.
Пример: «купить айфон» и «купить iphone xr 128 gb». Первый запрос хоть и указывает на потребность в покупке, но и показывает общую неопределённость пользователя. А если человек ищет запрос наподобие второго, от покупки его отделяет всего один шаг.
Шестой фактор — сезонность поискового спроса. Автором статьи замечено, что спрос на новогодние туры начинается уже в сентябре, а отдых на майские праздники бронируют в феврале. Если вы точно знаете про сезонность в своём бизнесе, то будьте уверены, что она будет проявляться и в частотности запросов.
Возникает важный вопрос: классификация интересная, но что мне с ней делать? Об этом подробнее поговорим ниже.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Стоит ли заказывать СЯ у специалистов?
По большому счету специалисты по составлению семантического ядра сделают вам только шаги 1 – 3 из нашей схемы. Иногда, за большую дополнительную плату, сделают и шаги 4-5 – (сбор хвостов и проверку конкурентности запросов).
После этого они выдадут вам несколько тысяч ключевых запросов, с которыми вам дальше надо будет работать.
И вопрос тут в том, собираетесь ли вы писать статьи самостоятельно, или наймете для этого копирайтеров. Если вы хотите делать упор на качество, а не на количество – то надо писать самим. Но тогда вам будет недостаточно просто получить список ключей. Вам надо будет выбрать те темы, в которых вы разбираетесь достаточно хорошо, чтобы написать качественную статью.
И вот тут встает вопрос – а зачем тогда собственно нужны специалисты по СЯ? Согласитесь, распарсить базовый ключ и собрать точные частотности (шаги #1-3) – это совсем не сложно. У вас уйдет на это буквально полчаса времени.
Самое сложное – это именно выбрать ВЧ запросы, у которых низкая конкуренция. А теперь еще, как выясняется, надо ВЧ-НК, на которые вы можете написать хорошую статью. Вот именно это займет у вас 99% времени работы над семантическим ядром. И этого вам не сделает ни один специалист. Ну и стОит ли тратиться на заказ таких услуг?
Когда услуги специалистов по СЯ полезны
Другое дело, если вы изначально планируете привлекать копирайтеров. Тогда вам необязательно разбираться в теме запроса. Копирайтеры ваши тоже не будут в ней разбираться. Они просто возьмут несколько статей по этой теме, и скомпилируют из них “свой” текст.
Такие статьи будут пустыми, убогими, почти бесполезными. Но их будет много. Самостоятельно вы сможете писать максимум 2-3 качественные статьи в неделю. А армия копирайтеров обеспечит вам 2-3 говнотекста в день. При этом они будут оптимизированы под запросы, а значит будут привлекать какой-то трафик.
В этом случае – да, спокойно нанимайте специалистов по СЯ. Пусть они вам еще и ТЗ для копирайтеров составят заодно. Но сами понимаете, это тоже будет стоить отдельных денег.
Как группировать запросы
Чтобы понять, как распределять ключевые слова по отдельным страницам, нужно сгруппировать запросы. Для этого надо создать семантические кластеры.
Чаще всего, ключевые слова из кластеров первого и второго уровней определяются еще на этапе мозгового штурма. Для этого просто нужно хорошо разбираться в своем продукте или ориентироваться на структуру сайтов-конкурентов. Семантика остальных подуровней определяется на этапе детального составления семантического ядра и его кластеризации
Еще одно важное условие — каждая группа запросов последнего уровня должна соответствовать одной потребности пользователя. Например, покупка конкретного вида детского белья
Используем Словоёб с уже известной нам функцией быстрого фильтра. С его помощью можно легко отсортировать фразы по категориям для дальнейшего внедрения на посадочных страницах.
1. Введите в поле быстрого фильтра базовое ключевое слово, которое может станет названием для категории/подкатегории/посадочной страницы (например, бренд детского постельного белья «Непоседа») и нажмите Enter.
2. Выделите нужные фразы и скопируйте их.
3. Удалите отмеченные строки правой кнопкой мыши.
4. Создайте в правом меню новую группу (например, с названием «Непоседы»).
5. Для добавления только что выбранных фраз в эту группу, перейдите во вкладку «Данные» — «Добавить фразы».
6. Вернитесь к прежнему списку нажатием клавиши Enter в поле поиска быстрого фильтра.
7. Повторите эту процедуру с другими запросами. Ключевые фразы автоматически выстроятся в алфавитном порядке, благодаря чему можно легко удалить лишние слова или выделить похожие фразы в отдельную группу.
Группировка вручную требует много времени (особенно в том случае, если семантика достаточно широкая). Для автоматизации этого процесса можно использовать платные Key Collector, Rush-Analytics, Just-Magic, или бесплатный скрипт Devaka.ru. Часто приходится объединять некоторые группы запросов. Например, такие:
Согласитесь, создавать две отдельные категории под фразы «красивое белье» и «стильное белье» неразумно 🙂 Для понимания важности фраз для каждой категории/посадочной страницы, скопируйте их в Планировщик ключевых слов Google в раздел «Получение статистики запросов и трендов»:
Так вы проверяете популярность (частотность) поискового запроса. В целом все поисковые запросы делятся на:
- ВЧ-запросы (высокочастотные).
- СЧ-запросы (среднечастотные).
- НЧ-запросы (низкочастотные).
- Микро НЧ-запросы.
При этом нет точных цифр, по которым можно с уверенностью сказать, что запрос принадлежит к определенной группе. Все зависит от тематики сайта. В одних тематиках фраза с частотностью 1000 запросов в месяц может быть низкочастотной (фильмы, музыка), в других — 200 запросов уже может быть признаком высокочастотной фразы (финансовая тематика). Соотношение этих групп: Наиболее высокочастотные запросы впоследствии вписывайте в метатеги. А под низкочастотные оптимизируйте страницы сайта. Как правило, они очень низкоконкурентны, и достаточно провести качественную работу с текстами, чтобы вывести соответствующие страницы в ТОП.
Читайте, как привлечь целевой трафик на сайт с помощью формирования максимально широкого семантического ядра.
После всех этих манипуляций вы получите подробную структуру сайта, состоящую из ключевых фраз для:
Semrush
Бесплатная версия сервиса предоставляет по 10 фраз в широком и фразовом соответствии, с частотами и под нужный регион.
Также сервис предлагает посмотреть поисковые фразы по заданному ключевому слову в других регионах, это позволяет расширить спектр поисковых фраз.
Недостатки:
- в бесплатной версии нельзя увидеть больше 10 фраз;
- цена платной версии 100$;
- нельзя загружать ключевые фразы списком.
Достоинства:
- охватывает все страны мира, удобно собирать запросы и частотность под западный регион;
- по каждому запросу показывает топ сайтов в выдаче, на которые можно ориентироваться для сбора базовых списков поисковых запросов.
Заключение
Как видите, собрать семантическое ядро можно всего за 5 шагов. Конечно, в этой инструкции представлен базовый вариант, который поможет вам познать азы и сделать самую простую семантику. Для более серьезных проектов понадобится соответствующий подход. Например, при кластеризации ключевиков вам придется делить их не только на ВЧ и НЧ, или ВК и НК, но и на коммерческие и некоммерческие. Или даже на группы с учетом региональности.
Все это будет непременно занимать время, но если вы самостоятельно будете работать над семантикой, собирать ее и видеть, как вообще обстоят дела на рынке поисковых систем, то по прошествии времени к вам постепенно будет приходить и понимание. Вы будете находить все новые инструменты для различных процессов, сможете делать сбор семантики и ее группировку чисто на одном дыхании. Конечно же, при условии, что вам это будет интересно.
Если вы сами не хотите разбираться со всем этим, то всегда можно заказать сбор семантического ядра у фрилансера или какой-нибудь студии. В интернете полно различных контор, которые готовы спарсить все данные и просто предоставить вам Excel-файлик. Цена может быть разной. Но я уверен, что если захотеть, то можно найти хорошего специалиста.Кстати говоря, если вам что-то непонятно из этой статьи и вы никак не можете разобраться со сбором семантического ядра, то должен уведомить, что на курсе Василия Блинова “Как создать блог” этот вопрос также будет обсуждаться. Возможно вам стоит пройти обучение и получить все необходимые знания.
До встречи в следующем обзоре.