Кто такой devops-инженер?
Содержание:
- Чем занимается DevOps специалист
- Зарплата и востребованность
- Какую пользу приносит DevOps инженер
- SRE
- Описание работы и навыки
- Целевые показатели: SLA, SLI, SLO
- Инструменты автоматизации DevOps
- DevOps and site reliability engineering (SRE)
- Знания, умения и личные качества
- Анализ и сравнение
- Управление конфигурацией
- Организация
- Что такое DevOps?
- Недостатки профессии DevOps-инженер
- Где работать и куда двигаться в карьере?
- Как стать инженером DevOps: требования и навыки
- Журналирование и мониторинг
- Как понять, движусь ли я к DevOps ?
Чем занимается DevOps специалист
Как мы уже поняли, DevOps занимается автоматизацией рабочих процессов. То есть он следит за тем, чтобы все задачи выполнялись в срок, и чтобы эти задачи были максимально оптимизированными. DevOps мониторит каждый этап, от написания кода до тестирования и последующего выпуска продукта. Более того, он также осуществляет и последующую поддержку релиза.
Разумеется, все это делается не вручную, а с помощью специального софта, который облегчает весь рутинный процесс. Если где-то что-то «отвалилось», то DevOps инженеру приходит уведомление об этом, и он принимает решения по устранению этой проблемы.
У многих может возникнуть вопрос, а разве обычных админов и разработчиков недостаточно для такого контроля и оптимизации рабочих процессов? На самом деле нет, поскольку решение этих задач будет отнимать время от основной работы разработчиков и админов. Поэтому для этих целей нужен отдельный специалист в лице DevOps-инженера.
Проще говоря, DevOps-инженер является связующим звеном между членами команды и координирует их работу. В задачи этого специалиста включены обязанности из разных сфер: администрирование, разработка, тестирование и менеджмент. И можно с уверенностью сказать, что DevOps является неким универсальным бойцом, который понимает каждый этап работы.
Если проводить аналогию, то DevOps можно сравнить с Fullstack дизайнером, который может и дизайн нарисовать и разработать его.
Зарплата и востребованность
Профессия DevOps инженера является одной из наиболее востребованных и перспективных в сфере ИТ. Так, по данным Global Market Insights, Inc., рынок операций DevOps в период с 2020 по 2026 год вырастет на 22%, и составит 17 млрд. долларов.
Институт DevOps также назвал наиболее востребованные роли в рамках профессии:
- DevOps-инженер — 39%
- Инженер-программист — 29%
- Консультант DevOps — 22%
- Инженер-испытатель — 18%
- Архитектор автоматизации — 17%
- Инженер инфраструктуры — 16%
- Инженер CI / CD — 16%
В России на момент написания этой статьи было открыто почти 5 тыс. вакансий для специалистов DevOps только на сервисе HH.ru.
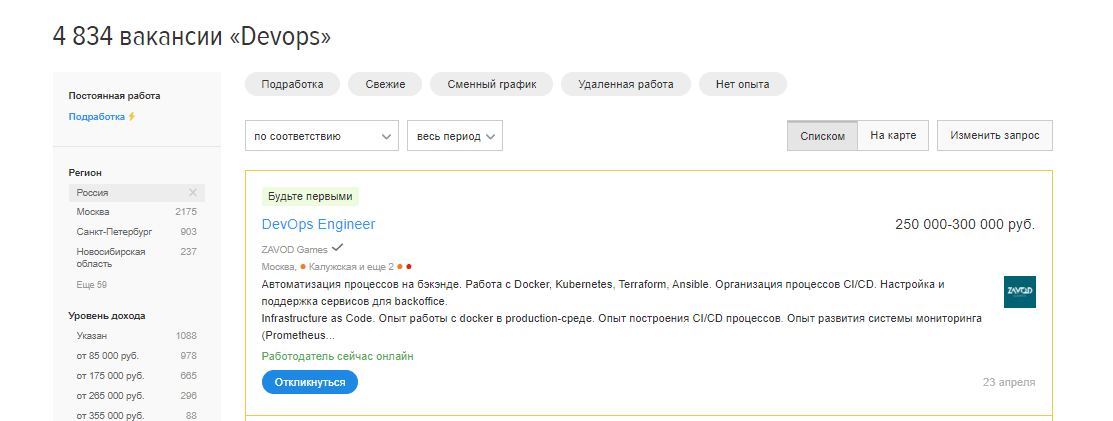
При этом, тот же сервис выдает всего 5800 резюме по специальности, что говорит о достаточно низкой конкуренции за рабочее место и неперегруженном рынке труда. Большая часть рабочих мест традиционно сосредоточена в Москве – здесь более 2 тыс. актуальных вакансий.

А теперь о самом интересном – сколько зарабатывает DevOps-специалист? По статистике Хабра, во втором полугодии 2020-го года медианная зарплата Девопса составила 150 тыс. рублей в месяц, специалисты начального уровня зарабатывали около 70 тыс. рублей, а топовые зарплаты достигали 250 тыс. рублей.

На западном рынке труда ситуация с зарплатами Девопсов еще более привлекательная. Так, Glassdoor сообщает о том, что средняя зарплата в США достигает 100 тыс. долларов в год, или более 8 тыс. долларов в месяц.
Какую пользу приносит DevOps инженер
Программист не может взвалить себе на плечи всю работу, особенно по тестированию кода. Поэтому, если QA найдет ошибки, то разработчик, сможет узнать о них только после окончания тестового периода.
Потом программу придётся вернуть на исправление, а потом опять тестировать ее, то есть начинать все сначала и такой цикл может длиться очень долго, задерживая выход программного обеспечения. Но если в работе над проектом участвует DevOps-инженер, то такого сценария можно избежать, ведь специалист с самого начала следит за тестированием и сразу говорит разработчику о допущенных ошибках.
Они в короткие сроки исправляются и сразу же можно проводит еще один тест. Если все проходит хорошо QА может продолжать работу. Благодаря слаженной работе мы получаем быстрый выход продукта и вместе с этим высокое качество программного обеспечения.
Самое главное, чего должен добиться DevOps – это правильное, а главное продуктивное взаимодействие между разработчиком, тестировщиком и сисадмином. При хорошей связи между разными частями одной команды, мы получим быструю работу, и минимальное количество ошибок на каждом этапе проекта.
SRE
Цель инженера по SRE — сделать так, чтобы сервис работал с такой надежностью, которая указана в соглашении о уровне оказания услуг (SLA). Стабильность работы зависит и от инфраструктуры, и от качества кода, поэтому SRE занимается и тем, и другим. Как правило, инженерами по SRE становятся опытные системные администраторы или разработчики. Разработчики даже чаще.
Специальность SRE относительно новая, поэтому вакансий немного. Но и немногочисленные открытые объявления показывают, что ожидания от SRE очень высоки. Этот специалист должен знать все, что знает системный администратор уровня Senior, плюс уметь разрабатывать на одном из языков программирования, желательно не скриптовых.
Пример требований:
- уверенные знания ОС Linux продвинутого уровня работы в консоли;
- опыт разработки на C/C++ или Go;
- понимание работы TCP/IP и HTTP;
- понимание устройства ОС (процессы, память, синхронизация);
- опыт настройки различных инструментов для мониторинга и конфигурирования серверов (Zabbix, Puppet, Ansible или подобные);
- опыт работы с Docker;
- опыт использования облачных сервисов Amazon: EC2, VPC, S3, Route53;
- опыт настройки сетей (инструменты: Nginx, HAProxy, bind, git, iptables, stunnel, OpenVPN);
- опыт настройки виртуальных машин: kvm, xen.
Пример задач:
- оптимизация имеющейся архитектуры и сервисов;
- уменьшение нагрузки на сопровождение и обслуживание сервисов за счет автоматизации;
- изучение имеющихся сервисов и поддержание актуальных знаний по ним;
- активный и проактивный поиск возможных проблем и их устранение;
- обеспечивать заданный уровень SLA & SLO;
- участвовать в инцидент-менеджменте;
- писать postmortem и разрабатывать мероприятия для повышения стабильности сервисов;
- создавать, актуализировать DRP (Disaster Recovery Plan), BCP(Disaster Recovery Plan) и проводить регулярные учения по отказам с последующим анализом результатов;
- участвовать в проработке архитектуры сервисов и изменений их конфигураций;
- оптимизация имеющихся систем observability.
Марсель, CТO в Slurm.io:
SRE-инженер должен быть хорошим программистом, при этом также хорошо должен знать инфраструктуру и DevOps-инструменты. По сути SRE вбирает в себя компетенции DevOps, и это логично, ведь SRE — это реализация того, как видит DevOps компания Google.
Сергей, СТO в Southbridge:
Я считаю, что у нас это скорее хайп, так как SRE и DevOps-инженер часто имеют одни и те же обязанности. На мой взгляд, SRE — это DevOps с бэкграундом разработки. Тут имеется в виду, что такой инженер может не просто написать скрипт на Go, а разобраться в коде и даже подсказать разработчикам, что с инфраструктурной точки зрения работает плохо и что надо улучшить.
Инженеры по SRE нужны еще в меньшем количестве компаний, чем DevOps-инженеры, и это крупнейшие организации.
Зарплаты SRE часто вообще не указывают, а если указывают, то фигурируют суммы в $2000, $2500, $4000.
Описание работы и навыки
Работа данных специалистов весьма разнообразна, а потому, для ее успешного выполнения, они должны обладать рядом навыков:
- Практический опыт в сетевой безопасности, базах данных, облачных системах
- Глубокие знания различных языков сценариев, системного и серверного администрирования, а также массового развертывания системы.
- Администрирование операционных систем, языков программирования, развертывания облачных платформ и сетевых протоколов.
- Подготовка релизов, конфигурации J2EE, создания инструментов для инженерной организации с целью оптимизации производительности.
Успешные девопы должны обладать не только превосходными техническими возможностями, но и отличными методами разработки стратегии. Им нравится сотрудничать с другими, и они обладают навыками общения выше среднего. Они также любопытны, умны, мотивированы. Помимо этих общих навыков, работодатели ищут кандидатов, которые обладают следующими навыками:
- Изучение и сбор новых технологий и связанных с ними инструментов для внедрения в компанию, с целью развития среды гибкой разработки.
- Обеспечение прямой поддержки сервера во время различных операций, таких как развертывание и общее производство
- Сотрудничество с разработчиками
- Создание настраиваемых кодов, таких как JavaScript, Java, HTML, CSS и C, которые являются безопасными для защиты от проблем кибербезопасности.
- Разработка, внедрение и тестирование согласованных инфраструктур.
- Автоматизация развертывания приложений Linux, конфигурации системы и настроек безопасности
- Справедливое определение приоритетов запросов от операционных разработчиков и продуктовых команд, демонстрируя при этом чувство сопереживания
- Профессиональные инструменты: они должны использовать несколько жизненно важных инструментов каждый день.
Целевые показатели: SLA, SLI, SLO
Одно из главных противоречий между отделом эксплуатации и разработки происходит из разного отношения к надёжности системы. Если для отдела эксплуатации надёжность — это всё, то для разработчиков её ценность не так очевидна.
SRE подход предполагает, что все в компании приходят к общему пониманию. Для этого определяют, что такое надёжность (стабильность, доступность и т. д.) системы, договариваются о показателях и вырабатывают стандарты действий в случае проблем.
Показатели доступности вырабатываются вместе с продакт-оунером и закрепляются в соглашении о целевом уровне обслуживания — Service-Level Objective (SLO). Оно становится гарантом, что в будущем разногласий не возникнет.
Специалисты по SRE рекомендуют указывать настолько низкий показатель доступности, насколько это возможно. «Чем надёжнее система, тем дороже она стоит. Поэтому определите самый низкий уровень надёжности, который может сойти вам с рук, и укажите его в качестве SLO», сказано в рекомендациях Google. Сойти с рук — значит, что пользователи не заметят разницы или заметят, но это не повлияет на их удовлетворенность сервисом.
Чтобы понимание было ясным, соглашение должно содержать конкретные числовые показатели — Service Level Indicator (SLI). Это может быть время ответа, количество ошибок в процентном соотношении, пропускная способность, корректность ответа — что угодно в зависимости от продукта.
SLO и SLI — это внутренние документы, нужные для взаимодействия команды. Обязанности компании перед клиентами закрепляются в в Service Level Agreement (SLA). Это соглашение описывает работоспособность всего сервиса и штрафы за превышение времени простоя или другие нарушения.
Примеры SLA: сервис доступен 99,95% времени в течение года; 99 критических тикетов техподдержки будет закрыто в течение трёх часов за квартал; 85% запросов получат ответы в течение 1,5 секунд каждый месяц.
Инструменты автоматизации DevOps
Крайне важно автоматизировать и настроить все процессы тестирования, чтобы сделать процесс быстрее и эффективнее. Этот процесс известен как автоматизация DevOps
Трудности, с которыми сталкивается команда DevOps, поддерживающая огромную IТ-инфраструктуру, можно кратко разделить на шесть категорий.
- Автоматизация инфраструктуры
- Управление конфигурацией
- Автоматизация развертывания
- Управление производительностью
- Управление логами
- Мониторинг
Давайте рассмотрим несколько инструментов в каждой из этих категорий и то, как они решают задачи.
Автоматизация инфраструктуры
Amazon Web Services (AWS): поскольку это облачный сервис, вам не нужно физически присутствовать в дата-центре. Кроме того, эти процессы легко масштабируются по требованию. Отсутствуют предварительные затраты на оборудование. Есть возможность автоматического выделения большего количества серверов на основе трафика.
Управление конфигурацией
Chef: Это полезный инструмент DevOps для того, чтобы сделать процессы быстрее, масштабнее и согласованнее. Его можно использовать для облегчения сложных задач и управления конфигурацией. Команде DevOps не нужно вносить изменения на десятках тысячах серверов. Достаточно внести изменения один раз, и они автоматически отобразятся на других серверах.
Автоматизация развертывания
Jenkins: Этот инструмент облегчает непрерывную интеграцию и тестирование. Jenkins помогает легче интегрировать изменения проекта благодаря быстрому обнаружению проблем после развертывания.
Управление логами
Splunk: Этот инструмент решает такие проблемы, как объединение, хранение и анализ всех логов в одном месте.
Управление производительностью
App Dynamic: Это инструмент мониторит производительность в режиме реального времени. Данные, собранные с помощью App Dynamic, помогают разработчикам проводить отладку при возникновении проблем.
Мониторинг
Nagios: Nagios — один из инструментов, который помогает командам DevOps находить и исправлять проблемы.
Больше информации про инструменты DevOps можно найти в этой статье.
DevOps and site reliability engineering (SRE)
Site reliability engineering (SRE) uses software engineering techniques to automate IT operations tasks — e.g. production system management, change management, incident response, even emergency response — that might otherwise be performed manually by systems administrators. SRE seeks to transform the classical system administrator into an engineer.
The ultimate goal of SRE is similar to the goal of DevOps, but more specific: SRE aims to balance an organization’s desire for rapid application development with its need to meet performance and availability levels specified in service level agreements (SLAs) with customers and end-users.
Site reliability engineers achieve this balance by determining an acceptable level of operational risk caused by applications — called an ‘error budget’ — and by automating operations to meet that level.
On a cross-functional DevOps team, SRE can serve as a bridge between development and operations, providing the metrics and automation the team needs to push code changes and new features through the DevOps pipeline as quickly as possible, without ‘breaking’ the terms of the organizations SLAs.
Знания, умения и личные качества
DevOps-инженера можно назвать многопрофильным специалистом со знаниями из различных сфер IT-деятельности: программирования, мониторинга, работы с базами данных, операционными системами и системами сборки, оркестрации и конфигурации, облачной инфраструктуры.
Специалист обязательно должен знать несколько языков программирования. В первую очередь это необходимо для автоматизации. Пригодятся языки Python, Bash, Ruby, Go, PowerShell. Достаточно знать основы синтаксиса, скрипты для автоматизации, понимать объектно-ориентированное программирование.
Разбираться в операционных системах надо, чтобы определять сервер для установки приложения, среду для запуска, инструменты для работы, возможные ошибки, которые могут возникнуть. Нужно понимать общие принципы работы на любой операционной системе, но чаще используют Windows или Linux.
Хороший DevOps-инженер должен уметь разбираться и работать с облачными провайдерами. Они автоматизируют многие процессы и экономят время, силы и деньги, что будет полезно не только для специалиста, но и для клиента.
И вот еще тот минимум, что надо знать:
- системы оркестрации, такие как Docker и Kubernetes;
- системы конфигураций Chef, Ansible, Puppet;
- системы сборки GitLab, Jenkins;
- языки разметки JSON и YAML;
- базы данных;
- сервисы мониторинга и оповещений;
- сервисы логирования;
- настройки кибербезопасности;
- процессы CI/CD;
- английский язык;
- периодическая таблица DevOps.
Список того, что нужно знать и уметь DevOps-специалисту можно продолжать долго. Но только практикуясь станет понятно, что именно изучать и как.
Для DevOps-инженера важны и личные качества:
- системное мышление;
- внимательность;
- хорошая память;
- коммуникабельность;
- ответственность;
- работоспособность;
- исполнительность;
- быстрая обучаемость.
Это только основные требования. Конкретные условия зависят от работодателей.
Анализ и сравнение
Ключевые метрики
- Частота развертываний. Как часто происходит развертывание новой версии приложения на продуктовое окружение (плановых изменений, исключая хотфиксы и реакцию на инциденты)?
- Срок поставки. Сколько в среднем времени проходит между коммитом изменения (написанием функциональности в виде кода) и развертыванием изменения на продуктовом окружении?
- Время восстановления. Сколько в среднем времени занимает восстановление приложения на продуктовом окружении после инцидента, деградации сервиса или обнаружения ошибки, влияющей на пользователей приложения?
- Неуспешные изменения. Какой процент развертываний на продуктовом окружении приводит к деградации приложения или инцидентам и требует устранения последствий (откат изменений, разработку хотфикса или патча)?
Сколько вешать в граммах?
- Распределяем респондентов по n-мерному пространству, где координата каждого респондента — их ответы на вопросы.
- Каждого респондента объявляем маленьким кластером.
- Объединяем два наиболее приближенных друг к другу кластера в один кластер побольше.
- Находим следующую пару кластеров и объединяем их в кластер побольше.
Как пользоваться
- Калькулятор DORA
- Калькулятор Экспресс 42* (в разработке)
- Своя разработка (можно составить свой внутренний калькулятор).
- Команда внутри нашей организации соответствует нашим стандартам?
- Если нет, то можем ли мы ей помочь — ускорить ее в рамках той экспертизы, которая есть в нашей компании?
- Если да, то можем ли сделать еще лучше?
- Какие у нас команды есть;
- Поделить команды на профили;
- Увидеть: О, эти команды у нас underperforming (немножко не вытягивают), а эти — классные: они деплоят каждый день, без ошибок, lead time у них меньше часа.
калькулятор DORA
Сравнение
- В 1,5-2 раза чаще выпускали новые продукты,
- В 2 раза чаще повышали надежность и/или производительность инфраструктуры приложений.
Управление конфигурацией
Puppet
Puppet – это инструмент управления конфигурацией с открытым исходным кодом, используемый для настройки, развертывания и управления многочисленными серверами.
Этот инструмент поддерживает концепцию инфраструктуры как кода и написан на Ruby DSL.
Он также поддерживает динамическое масштабирование машин по мере необходимости.
Chef
Chef – это инструмент управления конфигурацией с открытым исходным кодом, разработанный Opscode с использованием Ruby для управления инфраструктурой на виртуальных или физических машинах.
Он также помогает в управлении сложной инфраструктурой на виртуальных, физических и облачных машинах.
Ansible
Ansible – это инструмент для управления ИТ-конфигурацией с открытым исходным кодом, обеспечения программного обеспечения, оркестровки и развертывания приложений.
Это простой, но мощный инструмент для автоматизации простых и сложных многоуровневых ИТ-приложений.
SaltStack
SaltStack – это программное обеспечение с открытым исходным кодом, написанное на python и использующее push-модель для выполнения команд по протоколу SSH.
Он предлагает поддержку как горизонтального, так и вертикального масштабирования.
Он поддерживает шаблоны YAML для записи любых скриптов.
Terraform
Terraform – это инструмент с открытым исходным кодом для безопасного и эффективного построения, изменения, развертывания и управления версиями инфраструктуры.
Он используется для управления существующими и популярными поставщиками услуг, а также для создания собственных решений.
Он помогает определить инфраструктуру в конфигах / коде и позволит пользователю легко перестраивать / изменять и отслеживать изменения в инфраструктуре.
Vagrant
Vagrant – один из популярных инструментов для создания и управления виртуальными машинами (ВМ).
Он имеет простой в использовании и настраиваемый рабочий процесс, ориентированный на автоматизацию.
Это помогает сократить время настройки среды разработки, увеличивает производственный паритет.
Организация
Проблема «колодцев»
между командами нет обмена информациейСледствие корпоративной системы управления.«колодцы» не позволяют делать «очевидные» вещи— Мы хотели просто CI запустить, а получилось, что менеджменту это не надо.CI Continuous Delivery process
В вашей компании так же?
Пользуются ли команды общими инструментами, вносят ли вклад в изменения этих общих инструментов?
Насколько часто команды переформируются — одни специалисты из одной команды переходят в другую команду?Можно ли создать комитет по изменению и что-то изменить? Насколько важно для менеджеров получать личные достижения без учета достижений компании?
Что такое DevOps?
DevOps — это набор практик на стыке системного администрирования (Ops — Operations) и разработки (Dev — Development).
До внедрения DevOps при создании приложения целью группы разработки было написание кода, а группы инфраструктуры — поддержка всех серверов в работоспособном состоянии.
Если возникала проблема, инженер инфраструктуры мог сказать: «С сервером все в порядке, проблема с кодом, дальше разбираться я не буду, проблема не моя», — а разработчик говорил: «На моем компьютере этот код работает, проблема с сервером, дальше разбираться я не буду, это не моя зона ответственности».
Сисадмин, DevOps-инженер, тестировщик, программист и специалист поддержки взаимодействуют. Источник
С приходом DevOps-инженера вся команда фокусируется на единой цели — создании качественного продукта.
Без DevOps-культуры в компании может практиковаться ручное тестирование, ручное управление инфраструктурой, могут возникать конфликты в частях кода, написанных разными разработчиками. В итоге бизнес получит низкое качество продукта, низкую скорость вывода продукта на рынок, демотивированных сотрудников, вынужденных большую часть времени тратить на рутинные задачи и сложности при масштабировании.
Недостатки профессии DevOps-инженер
DevOps-инженер – человек, отвечающий за «сборку» всего проекта, от начальной до конечной стадии. И хорошая зарплата – всего лишь награда за неустанный труд в режиме «нон-стоп», огромное умственное напряжение, которое, рано или поздно, отрицательно сказывается на работе нервной системы, и другие моральные издержки профессии.
Специалист DevOps, как сотрудник МЧС, должен быть готов к немедленному реагированию на различные сбои в системе. Это автоматически означает, что у DevOps-инженера отсутствует понятие о личном времени и личном пространстве. Ведь мировая сеть должна работать бесперебойно, в любой точке мира, и пользователи к этому уже привыкли.
Люди, работающие в сфере IT-технологий, кажутся замкнутыми и лишенными эмоций. Для тех, кто понимает, такое поведение объясняется высокой, даже запредельной концентрацией внимания на работе. Это ограничивает круг общения увлеченных профессионалов. А поскольку технологиями больше увлекается мужская половина человечества, то и устраивать личную жизнь DevOps-инженеру сложнее, потому что он постоянно занят работой в мужском коллективе.
Где работать и куда двигаться в карьере?
Место работы: компании, которые занимаются создание ПО или управляют серверами. Эта должность распространена в крупных ИТ-компаниях.
Распространенные работодатели:
- специализированные компании по разработке программного обеспечения;
- веб-сайты и любая организация, которая управляет веб-сайтами;
- технологический консалтинг;
- телекоммуникационные компании и вещатели;
- ритейл;
- организации государственного сектора.
Какие основные этапы развития карьеры? Сначала хотим отметить, что должность DevOps-инженера обычно не является стартовой в карьере. Чаще всего в нее приходят люди с опытом в разработке или системном администрировании, реже – тестировщики. И эта профессия уже сама по себе является достаточно престижной.
Новичку в Девопсе предстоит пройти путь от джуниора до синьора. Вот базовые требования к каждому уровню:
| Junior | Должен знать GIT и основы администрирования Linux, писать простые скрипты для автоматизации, уметь «дебажить», понимать, что такое оркестрация и контейнеризация, выполнять мониторинг при помощи готовых средств. |
| Middle | Глубокое понимание производительности систем, Python/Ruby/Go, уверенная работа с DSL (Puppet), хорошие познания балансировки и сетей, продвинутая автоматизация и мониторинг. |
| Senior | Еще более углубленное развитие перечисленных ранее навыков, возможность внедрять сложные тесты, работать с архитектурой. |
3 самых распространенных варианта развития карьеры:
- Рост по вертикали. После прохождения основных уровней, можно возглавить Девопс отдел, стать архитектором или техническим директором. Для этого нужно прокачивать свои навыки в управлении и формировать глобальное видение процессов разработки.
- Рост по горизонтали. Использовать улучшение своих компетенций и расширение освоенного стека технологий для повышения стоимости своих услуг, наработки крутого портфолио, а как результат – работы с более крупными и серьезными компаниями.
- Переход в разработку. Это уже не всегда можно назвать продвижение по карьерной лестнице, но отдельных специалистов увлекает именно техническая работа и они становятся полноценными разработчиками.
Как стать инженером DevOps: требования и навыки
В реалиях сегодняшнего ИТ-рынка большинство DevOps приходят в профессию после технического обслуживания, развивая свои навыки в области разработки продуктов. Это связано с тем, что изначально 70-90% задач такого специалиста были связаны с обслуживанием инфраструктуры: систем, баз данных, серверов, сетей и только 10-30% требовали понимания разработки или автоматизации. В последние годы наметилась тенденция к повышению требований к соискателю: компании хотят видеть не только опыт поддержки, но и практические навыки программирования – это позволяет будущему сотруднику быстрее принимать решения и устранять ошибки в процессе реализации проекта.
Помимо опыта работы с решениями для разработки и администрирования, также необходимы знания об инструментах автоматизации процессов. С их помощью появляется возможность избавиться от большей части ручной работы, сокращая время работы над изделием.
Наконец, не менее важным для DevOps является понимание инструментов контейнеризации.
Относительно новым, но уже обязательным требованием можно считать базовое понимание работы в облаке и системах виртуализации.
Основные Hard и Soft skills соискателя на должность DevOps-инженера
| Хорошие навыки | Трансверсальные навыки |
| Знание основ администрирования операционных систем Linux. | Коммуникабельность и умение легко объяснить принцип работы сложных систем. |
| Понимание того, как работают системы баз данных, такие как SQL и NoSQL. | Вовлеченность. |
| Опыт работы с такими инструментами, как Git, Terraform, Kubernetes, Prometheus, Ansible и Docker. | Стрессоустойчивость. |
| Знание языков программирования, таких как Bash, Python, Golang и других. | Инициатива. |
| Знание английского языка на техническом уровне. | Презентационные навыки. |
Журналирование и мониторинг
Журналирование и мониторинг — очень важные аспекты инфраструктуры.
Большинство приложений, развернутых в инфраструктуре, будут создавать журналы. Основываясь на дизайне архитектуры, журналы будут передаваться и храниться в отдельном слое инфраструктуры.
Каждая компания будет иметь отдельный уровень инфраструктуры под журналирование. Обычно используются такие стеки, как Splunk, ELK и Graylog. Кроме того, существует несколько SaaS-компаний, таких как Loggly, которые предоставляют инфраструктуру для централизованного хранилища журналов.
Разработчики, системные администраторы и команда безопасности используют системные журналы для мониторинга, диагностики неполадок, аудита приложений и инфраструктуры.
В каждой организации критически важные приложения будут контролироваться круглосуточно и без выходных. Будут панели мониторинга. Как правило, такие дашборды создаются из источников журналов или метрик, отдаваемых приложением.
Как инженер DevOps, вы должны иметь доступ к журналам и уметь устранять неполадки во всех средах (Dev, QA, Stage, Prod)
Понимание регулярных выражений очень важно для построения запросов в любом инструменте централизованного хранилища журналов
Как понять, движусь ли я к DevOps ?
Через вопросы
Вы можете самостоятельно понять, движетесь ли вы к DevOps-культуре, ответив на следующие вопросы:
- Есть ли у вас стратегия по созданию цифрового продукта?
- Пользуются ли команды общими инструментами, вносят ли вклад в изменения этих общих инструментов?
- Насколько часто команды переформируются — одни специалисты из одной команды переходят в другую команду?
- Можно ли создать комитет по изменению и что-то изменить?
- Есть ли у вас в команде/компании общий инфраструктурный репозиторий?
- Контролируете ли вы технический долг в инфраструктуре?
- Используете ли вы практики разработки в инфраструктурном репозитории?
- Нарезана ли ваша инфраструктура на слои? Можно свериться, например, со схемой Base-service-APP. Насколько сложно внести изменение?
- Время от описания фичи до выкатки в продакшен в 95 % случаев меньше недели?
- Повышается ли качество артефакта на каждом этапе пайплайна?
- Используете ли вы различные стратегии деплоя?
- Ваш мониторинг и логирование — это средство разработки для вас? Ваши разработчики, и вы в том числе, когда пишут код, думают о том, как его замониторить?
- Узнаете ли вы о проблемах от клиентов? Понимаете ли вы клиента лучше из мониторинга и логирования? Понимаете ли вы систему лучше из мониторинга и логирования?
- Меняете ли вы систему просто потому, что увидели, что тренд в системе растет и понимаете, что еще 3 недели и все загнется?
Эти вопросы надо постоянно себе задавать. Если что-то можно вынести на сторонние сервисы — нужно выносить, если сторонний сервис начинает блокировать ваше движение, то надо строить систему внутри себя.