Синтез речи из текста с помощью яндекс speechkit
Содержание:
- Если вам позвонили из Yandex. Эти загадочные токены
- Вопросы
- Философия, Лицензия и Мотивация
- Acapela
- Нестабильность срабатывания гейт слоя
- Практические опыты с Red Hat JBoss Middleware RED HAT JBOSS FUSE. Часть №1
- Анализ затрат
- Подготовимся. Настройка профиля CLI
- Внешний вид
- Строим графы средствами 1С (без GraphViz)
- Получение команд от станции
- Использование компонента
- Программы для озвучки текста
- Для чего это нужно
- Installation
- Регистрация в «Облаке»
- Как настроить правильную техподдержку (helpdesk, service desk на коленке)
- Русский
- Как подключаться к сервисам Яндекса
Если вам позвонили из Yandex. Эти загадочные токены
Возможно, распознавать и синтезировать речь вам так понравится, что однажды вам позвонит милая девушка из Yandex и поинтересуется, все ли вам понятно в работе сервиса.
Продолжайте изучать документацию, и тогда вы узнаете, например, что iam_token живет не более 12 часов.
Чтобы быть вежливым, как наш дворецкий, и не перегружать сервера на Yandex, мы не будем генерировать iam_token чаще (при желании теперь стало можно генерить токен при каждом запросе). Заведите себе блокнотик и карандашик для записи даты генерации. Шутка.
Ведь у нас есть Python. Создадим функцию генерации. Снова используем requests:
Вызовем функцию и положим результат в переменную:
Карандишик и блокнотик не пострадали, а у вас появилась полезная переменная xpires_iam_token.
Специально для вас по мотивам этого материала я написала маленький кусочек проекта виртуального дворецкого Butler. Звуковые эффекты входят в комплект 🙂
Вопросы
-
Почему вы используете консольные команды, а не REST-запросы по API?
-
В первых версиях этой обработки я использовал запросы напрямую из 1С. Но поскольку при распознавании коротких аудиозаписей мне приходилось запускать базу 1С в несколько потоков, четыре базы 1С, запущенные на одном компьютере, существенно съедали память. Из-за этого и перешли на Curl.
-
Разве у вас файловая база? В клиент-серверной базе можно пользоваться фоновыми заданиями, сделать REST-запрос на сервере. Такая возможность есть очень давно. У меня тоже используется подобное решение, правда для других целей – стартует несколько фоновых потоков, каждый из которых что-то выполняет. В вашем случае это дало бы очень сильный выигрыш.
-
Как вы решаете случаи, когда одно слово отправлено в разных кусках – будет ли оно распознано?
-
У нас есть исходная расшифровка и есть расшифровка менеджера, который приводит исходную расшифровку в более читаемый текстовый вид, потому что все равно исходное распознавание получается не стопроцентное – аналоговая АТС вносит свои коррективы. Например, при проверке онлайн-распознавания на сайте Яндекса, слова, сказанные в микрофон с ноутбука, распознаются лучше, чем загруженные из файла телефонного разговора, записанного через обычный аналоговый аппарат АТС. Соответственно, менеджеру приходится исправлять за Яндексом ошибки. Так эта проблема и решается.
-
Сколько времени заняла реализация проекта и какое количество суммарно сотрудников менеджеров телефонных звонков у такая статическая информация о понять масштабы?
-
Я на слайде приводил статистику – с 2017 года было обработано 118 тысяч звонков. У нас работает где-то 45 менеджеров, в месяц они наговаривают 5 гигабайт этих телефонных разговоров. Такое количество звуковой информации можно спокойно распознать в четырех потоках. Яндекс предоставляет 20 потоков, соответственно, еще есть куда расти.
-
Когда вы конвертируете wav-файлы в OggOpus, вы не пробовали играться, на каком битрейте уже распознавание хуже?
-
Я пробовал менять частоту дискретизации. Соответственно, сейчас он по умолчанию там на 11000 0,25 герц я пробовал увеличить в два раза до 22000. Размер файла увеличился в два раза, стоимость распознавания увеличилась, но качество не очень увеличилась. Скажу по опыту, что легче поставить хорошие телефонные аппараты, убрать фоновое звучание музыки – сделать тихий кабинет. Тогда все распознается идеально. Допустим, когда распознается автоответчик, что-то наговаривает, то когда Яндекс пытается это преобразовать в текст все идеально получается. Когда менеджер комкает слова либо быстро говорит – соответственно, возможны проблемы. То есть легче поменять оборудование и просить менеджеров следить за четким произнесением ключевых слов. Например, еси нужно, чтобы зафиксировалась слово «Заказ», то они должны четко сказать «Заказ», тогда это слово точно отделится пробелами от всех остальных слов и можно будет делать по нему поиск.
-
Что делать с переадресацией звонков на мобильный, звонки с мобильных, в WhatsApp и так далее? Или у вас все только через корпоративную АТС и других вариантов нет?
-
Если в компании используется мобильная телефония, то лучше перейти на цифровые АТС, например, на MANGO. Нашими силами это не решить – если звонок ушел с АТС, SPRecord его не запишет, и он не будет расшифрован.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Saint Petersburg.Online. Больше статей можно прочитать здесь.
Философия, Лицензия и Мотивация
Как авторы моделей, мы считаем следующие правила использования моделей справедливыми:
- Голоса из внешних источников приведены исключительно в целях демонстрации и будут удалены;
- Любые из описанных выше моделей нельзя использовать в коммерческих продуктах;
- Репозиторий опубликован под лицензией GNU A-GPL 3.0. Де-юре это не запрещает коммерческое использование, но по факту мы еще не встречали коммерческие решения с полностью открытым кодом, чего требует эта лицензия;
- Если вы ставите своей целью некоммерческое использование наших моделей во благо общества — мы будем рады помочь вам с интеграцией моделей в ваше решение;
- Если вы планируете использование наших моделей в личных целях (по фану или для озвучки каких-то текстов), то делитесь результатами своих экспериментов в репозитории;
- Если вы планируете использование наших моделей в некоммерческих продуктах для людей с нарушениями речи или зрения — обращайтесь, мы поможем с интеграцией, чем умеем;
Делая этот проект мы ставили своей целью ценой многочисленных компромиссов показать, что современный TTS, удовлетворяющий описанным выше критериям, возможен. И для этого не нужно быть заложником закрытых экосистем корпораций.
Acapela
Для некоторых языков доступно до 18 различных тембров, что делает этот речевой синтезатор уникальным. Такое разнообразие будет полезным, если хочется, чтоб набранный текст прозвучал эмоционально или был произнесен нужным актером. К сожалению, для русского языка доступен только один голос, поэтому многообразие тембров будет полезно лишь для тех, кто изучает иностранный.
Основной функционал программы полностью бесплатен, но для того, чтобы скачать пакет разработчика, позволяющего загружать и работать с озвученными текстами, придется заплатить немалую сумму в 1500 евро. Этот вариант будет полезен только для продвинутых пользователей, разрабатывающих аудио-дорожки в коммерческих целях.
Ограничение на длину вводимого текста у Acapela составляет 300 символов. Это в два раза больше, чем у ISpeech, но намного меньше, чем у Google Translate. Веб-служба работает бесперебойно, а каждый текст озвучивается как будто реальным человеком — в этом преимущество Acapela от утилит, где искусственные голоса напоминают о холодных механических роботах.
Нестабильность срабатывания гейт слоя
Напомним, что гейт слой отвечает за остановку генерации, и если он не сработает, то декодер будет продолжать генерировать фреймы, пока не достигнет лимита по шагам декодинга. Это выливается в продолжительное мычание в конце предложения, что забавно, но мешает презентовать свой синтез заказчикам.
Эта проблема решается несколькими небольшими уловками:
- Символ EOS вводится для каждого предложения, даже если у него в конце уже проставлен знак препинания из набора ;
- В конце каждой аудиозаписи добавляется небольшой участок тишины;
- При расчёте функции потерь для гейт слоя нужно увеличить вес его положительных выходов, чтобы они играли бОльшую роль.
Все вышеперечисленные ухищрения присутствуют в нашем репозитории движка, который мы выложили в открытый доступ (об этом ниже).
Практические опыты с Red Hat JBoss Middleware RED HAT JBOSS FUSE. Часть №1
Задачи интеграции на солидном предприятии могут быть неочевидно сложны и многообразны. Нередко выполняется скрупулезная оценка рисков до начала разработки «на берегу». Рассмотрите эксперименты с бесплатными аналогами дорогостоящих эквивалентов систем интеграции на основе сервисной шины предприятия ESB. Они проводились на актуальной версии Centos Linux. Большим плюсом Fuse являются разнообразие решаемых задач, широкие возможности смены или доработки стратегии, технологий интеграции уже в процессе внедрения. (В скачанных дистрибутивах заготовки настроек для запуска этого ПО на Windows имеются.). В данной публикации Вы узнаете как установить и запустить сервисную шину RED HAT JBOSS FUSE.
Анализ затрат
Итак, переходим к важному важному – сколько же все это стоит. Распознавание длинных аудио в 15 раз стоит одну копейку за один такт
Единица тарификации – это 15 секунд
Распознавание длинных аудио в 15 раз стоит одну копейку за один такт. Единица тарификации – это 15 секунд.
Короткие аудио распознаются дороже – 15 копеек за один такт.
Затраты в месяц – на графике показаны реальные затраты в марте 2020 года – всего за месяц уходит в районе 2 200 – 2 500 (это около шестидесяти трех часов).
В день это занимает там 250 рублей – кружка дорогого кофе.
На что в Яндексе больше всего уходит денег? На слайде я привел расшифровку по сервисам:
-
сразу видно, что самое дорогое – это именно распознавание аудиозаписей, оно съедает максимальный бюджет;
-
хранение на Yandex Object Storage стоит копейки. Это связано с тем, что файл на нем хранится несколько минут – мы отправляем файл на Yandex Object Storage, распознаем его и сразу удаляем.
Соответственно, весь бюджет съедает распознавание аудиозаписи.
Подготовимся. Настройка профиля CLI
Активация аккаунта на облаке
Для использования сервиса YSK у вас должна быть почта на Yandex. Если у вас её нет, то самое время завести.
Будьте готовы к тому, что вам потребуется еще подтвердить свой номер мобильного телефона. Без этого, увы, сервисы будут недоступны.
Почта есть. Теперь самое время перейти на cloud.yandex.ru. Перейдя в консоль надо активировать пробный период пользования сервисом. Для этого надо привязать платежную карту. Как только вы это сделаете вам будет доступен грант на 60 дней.
В облака – через командную строку
Для понимания, как работает распознавание и синтез, мы потренируемся в командной строке. Например, в iTerm.
Для отправки запросов на API через командную строку установим утилиту cURL. Перед установкой проверьте, возможно, она у вас уже есть ($ curl —version):
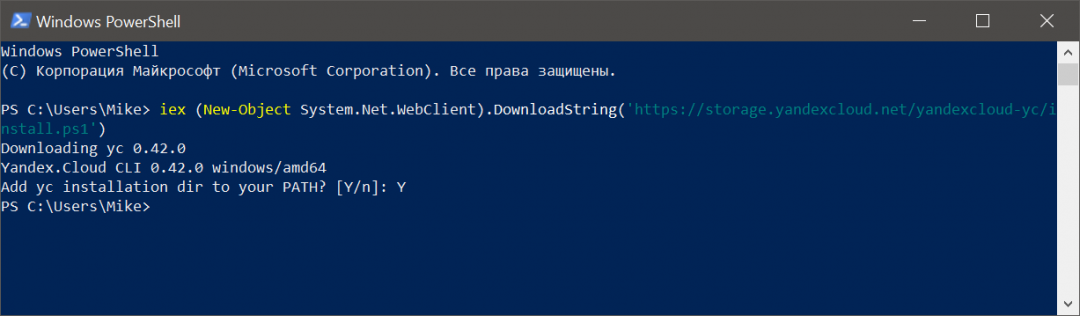
Теперь настроим Интерфейс Яндекс.Облака для командной строки (CLI). Запустим скрипт:
Перезапустите командную оболочку. В переменную окружения PATH добавится путь к исполняемому файлу – install.sh.
Теперь нам нужно, чтобы в CLI заработало автодополнение команд в bash:
Если у вас еще нет менеджера пакетов Homebrew, установите его. Он вам не раз пригодится, обещаю.
Затем ставим пакет bash-completion:
и посмотрим, что изменилось в файле ~/.bash_profile:
Примечание: ~/.bash_profile используется для пользовательских настроек, в частности – для определения переменных окружения.
Видим, что в конце bash_profile добавились новые строчки:
Выше новых строк вставьте эту:
Набираем команду:
и получаем приветственное сообщение:
Вам предложат выбрать облако (скорее всего у вас оно единственное):
Далее по желанию выберете Compute zone. Пока пользователь один – этим можно пренебречь.
Посмотрим, как выглядят настройки профиля CLI:
Мы в шаге от старта. Осталось добыть второй ключ (в настройках профиля он не будет отображаться):
Полетели!
Внешний вид
Красивые иконки Яндекс устройств можно установить через HACS.
Красивый медиа плеер можно установить через HACS.
Внимание: правильно указывайте название вашего TTS сервиса. По умолчанию он. Если вы его не изменили на по инструкции про
Тут на конце не нужно указывать
Если вы его не изменили на по инструкции про . Тут на конце не нужно указывать.
Пример как настроить карточку Яндекс Мини:
entity: media_player.yandex_station_mini
shortcuts:
attribute: sound_mode
buttons:
- icon: 'mdi:voice'
id: Произнеси текст
type: sound_mode
- icon: 'mdi:google-assistant'
id: Выполни команду
type: sound_mode
- icon: 'mdi:playlist-star'
id: включи мою любимую музыку вперемешку
type: command
- icon: 'mdi:playlist-music'
id: включи плейлист дня
type: command
- icon: 'mdi:heart'
id: лайк
type: command
- icon: 'mdi:heart-off'
id: снять лайк
type: command
columns: 6
tts:
platform: yandex_station
type: 'custom:mini-media-player'
Пример как настроить карточку Яндекс Станции:
entity: media_player.yandex_station artwork: full-cover sound_mode: icon hide: sound_mode: false runtime: false tts: platform: yandex_station type: 'custom:mini-media-player'
Строим графы средствами 1С (без GraphViz)
Множество статей на Инфостарте описывают, как работать с компонентой GraphViz, чтобы построить ориентированный граф. Но практически нет материалов, как работать с такими графами средствами 1С. Сегодня я расскажу, как красиво строить графы с минимальным пересечением.
Нам этот метод пригодился для отрисовки алгоритмов в БИТ.Финансе, т.к. типовой механизм не устраивал. Еще это может быть полезно для визуализации различных зависимостей: расчета себестоимости, графы аффилированности компаний и т.д.
Надеюсь, эта статья поможет сделать мир 1С красивее и гармоничней:)
Итак, поехали…
Получение команд от станции
Только для продвинутых пользователей
Для работы функционала должна быть настроена интеграция Home Assistant с умным домом Яндекса!
- Настройте список фраз, на которые ваши станции должны реагировать и ответы на них. Если не хотите ответ — просто поставьте точку как в примере. При первом запуске копонент создаёт служебный медиа-плеер .
- Синхронизируйте ваши устройства в мобильном приложении Яндекса, чтоб этот плеер появился и там. Не нужно его переименовывать и перемещать в комнаты.
- Перезапустите Home Assistant. В мобильном приложении Яндекса должны появиться ваши сценарии.
В ответ на эти фразы в Home Assistan будет генерироваться событие типа с произнесённым текстом. Теперь можете писать свои автоматизации на YAML или Node-RED.
yandex_station:
username: myuser
password: mypass
intents:
Покажи сообщение: ага
Какая температура в комнате: .
Какая влажность в комнате: .
automation:
- trigger:
platform: event
event_type: yandex_intent
event_data:
text: Покажи сообщение
action:
service: persistent_notification.create
data:
title: Сообщение со станции
message: Шеф, станция чего-то хочет
Использование компонента
Начиная с версии Oktell 2.12, в служебных и IVR сценариях появился компонент «Синтез речи». Компонент озвучивает заданную фразу (синтезирует речь) с помощью сервиса Yandex SpeechKit. Позволяет сразу воспроизвести файл в линию, либо сгенерировать файл для последующего использования. В компоненте можно включить кэш, тем самым сохраняя все сгенерированные файлы в папку \Oktell\Server\LocalStorage\SynthesisCache. Так как каждый запрос к сервису Яндекс платный, то включенный кэш позволяет сэкономить ваши средства.
Для использования системы синтеза речи Yandex SpeechKit выполните следующие действия:
Шаг 1. Получить авторизационные данные на использование сервиса Yandex SpeechKit.
Шаг 2. Перейдите в Администрирование / Общие настройки / Распознавание речи Yandex SpeechKit Cloud. Введите полученные значения OAuth-токен и Идентификатор каталога в соответствующие поля
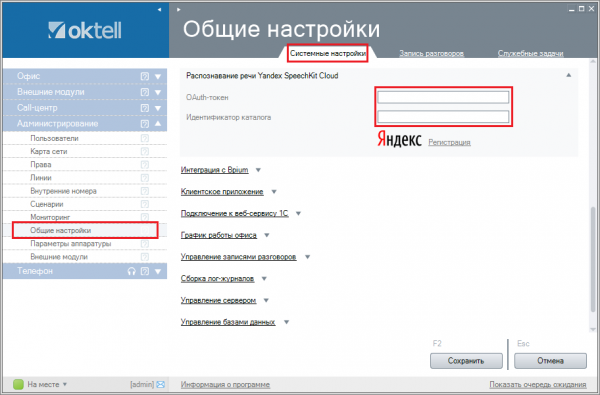
Нажмите «Сохранить«. Теперь вы можете использовать синтез речи в сценариях.
Шаг 3. Рассмотрим пример использования синтеза речи в IVR сценарии.
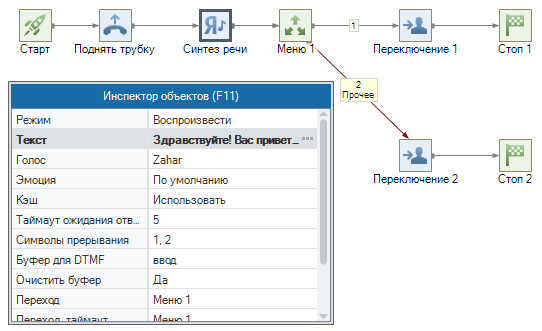
Компонент «Синтез речи«. Озвучивает приветствие абоненту и сохраняет выбор абонента в переменную.
- Режим — Воспроизвести. В этом режиме компонент сразу воспроизводит сгенерированный файл в текущую линию.
- Текст — строка «Здравствуйте! Вас приветствует компания Телефонные Системы! Для соединения с менеджерами нажмите 1. Для соединения с сотрудниками технической поддержки нажмите 2.«. Введенный текст будет передан на сервера Yandex для озвучивания.
- Голос — Zahar. Настройка отвечает за синтезируемый голос: Zahar — мужской голос, Jane -женский. Возможно указание другого значения, если оно поддерживается сервисом Yandex SpeechKit.
- Эмоция — По умолчанию. Настройка отвечает за используемую окраску голоса. Возможные варианты: good, neutral, evil, mixed.
- Кэш — Использовать. Если использовать кэш, то система попытается найти файл с озвученным текстом среди сгенерированных ранее (находятся в папке \Oktell\Server\LocalStorage\SynthesisCache). Рекомендуется всегда включать в целях экономии средств.
- Таймаут ожидания ответа, с — 5. Максимальное время ожидания ответа от серверов Яндекс.
- Символы прерывания — строка «1, 2«. Если абонент нажмет на указанные символы прерывания, компонент сохранит их в буфер и перейдет к следующему блоку.
- Буфер для DTMF — переменная ввод (строковая). Переменная, в которую сохранится введенный символ прерывания.
- Очистить буфер — Да. Указывает на то, что буфер предварительно будет очищен.
Компонент «Меню«. Маршрутизирует абонента на выбранную группу операторов.
- Аргумент — переменная Ввод
- Значения —
- 1 — на компонент «Переключение 1»
- 2, прочее — на компонент «Переключение 2»
Настройка дальнейшей маршрутизации не рассматривается.
Программы для озвучки текста
Если вам нужно постоянно озвучивать большие объемы текста из электронных документов, то самый удобный вариант — установить специальные приложения, которые умеют работать с файлами разного формата.
Балаболка
Балаболка — бесплатная программа озвучки для Windows от российских разработчиков. Она поддерживает работу с любыми голосовыми движками, установленными в системе. В ее интерфейсе есть стандартные инструменты для управления воспроизведением: пауза, остановка, перемотка, изменение скорости и громкости.
«Балаболка» умеет читать вслух текст из буфера обмена, произносить набираемые на клавиатуре фразы, озвучивать содержимое редактора или загруженных в нее файлов в форматах AZW, AZW3, CHM, DjVu, DOC, DOCX, EML, EPUB, FB2, FB3, HTML, LIT, MOBI, ODP, ODS, ODT, PDB, PDF, PPT, PPTX, PRC, RTF, TCR, WPD, XLS, XLSX.
Результат обработки «Балаболка» сохраняет как аудиофайл в форматах WAV, MP3, MP4, OGG и WMA. У нее также есть возможность сохранения текста внутри файлов MP3 для дальнейшего отображения в виде субтитров в медиапроигрывателе.
Govorilka
Govorilka — ещё одна программа для озвучки с минималистичным интерфейсом. Поддерживает голосовые движки устаревшего стандарта SAPI 4, в том числе на иностранных языках.
По умолчанию Govorilka озвучивает текст голосом стандартного движка Microsoft. В ее составе есть инструменты управления, традиционные для программ такого типа: воспроизведение, пауза, остановка, изменение скорости, громкости и высоты голоса. Одновременно в ней можно открыть до 8 вкладок с разными фрагментами текста.
Несмотря на простоту и устаревший интерфейс, «Говорилка» всё еще актуальна. Она умеет распознавать текстовые документы в разных форматах объёмом до 2 Гб и сохранять результат обработки в MP3 и WAV.
eSpeak
eSpeak — бесплатная программа для озвучки текста, доступная на Windows, macOS, Linux и Android. Она использует голосовые движки, установленные в системе, а также добавляет к ним несколько своих.
Версия этого приложения для Windows имеет максимально простой интерфейс и управление. Текст, который нужно прочитать, достаточно вставить в поле посредине окна, а затем нажать “Speak”.
Максимальный размер текста здесь явно не определен, но приложение справляется с большими объёмами. Также у него есть возможность читать тексты из файлов с расширением TXT, другие форматы не поддерживаются.
Для управления скоростью чтения в eSpeak используется ползунок Rate. Если вы хотите сохранить прочитанный текст в аудиофайл, нажмите на кнопку «Save to .wav» и задайте имя записи.
В мобильной версии приложения для Android аналогичная функциональность, разве что нет возможности сохранить текст в аудио.
Acapela TTS
Acapela Group разрабатывает программы для всех популярных операционных систем: Windows, macOS, Linux. Android, iOS. Среди главных достоинств этого софта — поддержка большого количества языков и отличное качество голоса. Мощные движки хорошо обучены и имеют развёрнутую справочную базу, которая позволяет им говорить правильно и выразительно.
Однако все продукты Acapela коммерческие. Установить приложение на компьютер или телефон можно бесплатно, но без купленного голосового движка в них нет никакого смысла. Стоимость одного пакета — 3,99 евро. Прежде чем оплачивать покупку, вы можете прослушать демо голоса с произвольным текстом, чтобы определить, подходит ли вам такое звучание.
ICE Book Reader Professional
Если вы ищите программу, которая будет озвучивать целые книги, то попробуйте ICE Book Reader Professional. Это приложение поддерживает различные форматы текстовых документов: TXT, HTML, XML, RTF, DOC и DOCX, PALM (.PDB и .PRC), PSION/EPOC (.TCR), Microsoft Reader (.LIT), Microsoft HELP files (.CHM) и FictionBook файлы (все версии) (.FB2, .XML). А для чтения в нем используются голосовые движки стандарта SAPI 4 и 5.
Программа умеет превращать книги в MP3/WAV-файлы. Это значит, что вы можете из любого произведения, доступного в текстовом формате, сделать аудиокнигу.
Скорость преобразования текста в голос в этом приложении увеличивается за счёт одновременного использования нескольких модулей синтеза речи.
Для чего это нужно
Смысл такой: если нужно перевести аудиозапись в текст, можно это сделать очень быстро с помощью нейросетей. Яндекс в этом всяко преуспел, и мы теперь можем этим воспользоваться в своё удовольствие.
Если вы редактор или автор, вам нужно часто общаться с экспертами, чтобы получить необходимую информацию для своей работы. Можно всё конспектировать на ходу, а можно записать на диктофон и потом перевести в текст за 10 минут.
Если коллега вам оставил длинное голосовое сообщение, текст которого нужно разместить на сайте, то можно набрать всё руками или отдать эту задачу компьютеру.
Если вы студент и не хотите конспектировать лекции по гуманитарным наукам, запишите их на телефон, и нейронка переведёт их в текст. У вас будут самые полные лекции, и вся группа будет бегать за вами перед экзаменом.
В некоторых вебинарах или видео на YouTube есть классная информация, но каждый раз приходится их смотреть и перематывать, чтобы найти нужное. Выход простой: берём видео, вырезаем оттуда звук, отправляем в сервис распознавания и получаем готовый текст, с которым работать гораздо проще.
Installation
There are several ways to add SpeechKit to a project.
Installing with CocoaPods
$ gem install cocoapods
Podfile
To integrate SpeechKit into your project using CocoaPods, create a file in the project directory:
source 'https://github.com/CocoaPods/Specs.git' platform :ios, '8.0' target 'TargetName' do pod 'YandexSpeechKit', '~> 3.12.2' end
Then run the command:
$ pod install
Adding SpeechKit directly
You can add SpeechKit directly to a project as a static library, without using a dependency manager.
In the Xcode project settings, choose -> , then click -> and choose SpeechKit. Also add all the frameworks and libraries required by SpeechKit in the same section. For a complete list, see .
In -> , add the bundle with the resources, which is located in the directory.
In -> -> , set the path to the directory that contains SpeechKit.
Регистрация в «Облаке»
Для этого нам понадобится Яндекс-аккаунт: заведите новый, если его у вас нет, или войдите в него под своим логином.
Если аккаунт уже есть — переходим на страницу сервиса cloud.yandex.ru и нажимаем «Подключиться»:
На следующем шаге подтверждаем согласие с условиями, и мы у цели:
На главной странице «Облака» активируем пробный период, чтобы бесплатно использовать все возможности сервиса, в том числе и SpeechKit:
Единственное, что нам осталось из формальностей, — заполнить данные о себе и привязать банковскую карту. С неё спишут два рубля и сразу вернут их, чтобы убедиться, что карта активна. Она нужна для того, чтобы пользоваться сервисами после окончания пробного периода. Если вам это будет не нужно — просто удалите карту, когда закончите проект.
Когда подключите карту — нажмите «Активировать».
Когда всё будет готово, вы попадёте на главную страницу сервиса, где увидите что-то подобное:
Вместо статуса Active вы увидите статус «Пробный период» и баланс в 3000 ₽ без кредитного лимита.
Как настроить правильную техподдержку (helpdesk, service desk на коленке)
Эта статья будет полезна для компаний, которые оказывают техническую поддержку своим пользователям — внешним или внутренним клиентам
В статье я расскажу, как оказываем поддержку мы, как выстроили этот бизнес-процесс, что контролируем и на что обращаем внимание в работе
Вы можете использовать наш опыт при построении собственной системы поддержки или обратиться к нам за помощью за построением такой системы, будем рады помочь. В статье формируется основной набор правил, которые мы сформировали при настройке системы для себя, а так же небольшие примеры того, как мы эти правила применяем.
Русский
Список поддерживаемых фонем при использовании русского языка (). Подробнее о русской фонологии.
| IPA | X-SAMPA | Описание | Примеры |
|---|---|---|---|
| Согласные | |||
| b | b | твердая «б» (voiced bilabial plosive) | рыба |
| bʲ | b’ | мягкая «б» (palatalized voiced bilabial plosive) | бюро |
| d | d | твердая «д» (voiced alveolar plosive) | дом |
| dʲ | d’ | мягкая «д» (palatalized voiced alveolar plosive) | дядя |
| f | f | твердая «ф» (voiceless labiodental fricative) | форт |
| fʲ | f’ | мягкая «ф» (palatalized voiceless labiodental fricative) | финал |
| g | g | твердая «г» (voiced velar plosive) | гол |
| ɡʲ | g’ | мягкая «г» (palatalized voiced velar plosive) | герой |
| j | j | звук «й» (palatal approximant) | я , дизайн |
| k | k | твердая «к» (voiceless velar plosive) | кот , ку |
| kʲ | k’ | мягкая «к» (palatalized voiceless velar plosive) | кино , кю |
| l | l | твердая «л» (alveolar lateral approximant) | луч |
| lʲ | l’ | мягкая «л» (palatalized alveolar lateral approximant) | лес |
| m | m | твердая «м» (bilabial nasal) | мама |
| mʲ | m’ | мягкая «м» (palatalized bilabial nasal) | меч |
| n | n | твердая «н» (alveolar nasal) | нос |
| nʲ | n’ | мягкая «н» (palatalized alveolar nasal) | няня |
| p | p | твердая «п» (voiceless bilabial plosive) | папа |
| pʲ | p’ | мягкая «п» (palatalized voiceless bilabial plosive) | пена |
| r | r | твердая «р» (alveolar trill) | рок |
| rʲ | r’ | мягкая «р» (palatalized alveolar trill) | рис |
| s | s | твердая «с» (voiceless alveolar fricative) | суд |
| sʲ | s’ | мягкая «с» (palatalized voiceless alveolar fricative) | сено , русь |
| ɕ: | s: | шипящая «щ» (long voiceless alveolo-palatal fricative) | щит |
| ʂ | s` | шипящая «ш» (voiceless retroflex fricative) | шест |
| t | t | твердая «т» (voiceless alveolar plosive) | танк |
| tʲ | t’ | мягкая «т» (palatalized voiceless alveolar plosive) | тётя |
| t͡s | ts | звонкая «ц» (voiceless alveolar affricate) | царь |
| t͡ɕ | ts\ | глухая «ч» (voiceless alveolo-palatal affricate) | чуть |
| v | v | твердая «в» (voiced labiodental fricative) | вон |
| vʲ | v’ | мягкая «в» (palatalized voiced labiodental fricative) | весы |
| x | x | твердая «х» (voiceless velar fricative) | хор |
| xʲ | x’ | мягкая «х» (palatalized voiceless velar fricative) | химия |
| z | z | твердая «з» (voiced alveolar fricative) | зуб |
| zʲ | z’ | мягкая «з» (palatalized voiced alveolar fricative) | зима |
| ʑ: | z: | буквосочетания «зж» и «жж» (long voiced alveolo-palatal fricative) | езжу , вожжи |
| ʐ | z` | короткая «ж» (voiced retroflex fricative) | жена |
| Гласные | |||
| ə | @ | Шва — безударные «а», «о» или «э» (mid central vowel) | корова , молоко |
| a | a | ударная «а» или «я» (open front unrounded vowel) | там , мяч , яма |
| ɐ | 6 | безударная «а» (near-open central vowel | каравай , голова |
| e | e | ударная «е» (close-mid front unrounded vowel) | печь |
| ɛ | E | ударная «э» (open-mid front unrounded vowel) | это |
| i | i | ударная «и» (close front unrounded vowel) | лист |
| ɪ | I | «е» или «и» после палатализованной согласной в безударном слоге (near-close front unrounded vowel) | дерево |
| ɨ̞ | I\ | «е» или «и» после непалатализованной согласной в безударном слоге (near-close central unrounded vowe) | жена |
| ɨ | 1 | ударная «ы» (close central unrounded vowel) | рыло |
| o | o | ударная «о» (close-mid back rounded vowel) | кот |
| u | u | ударная «у» или «ю» (close back rounded vowel) | муж , вьюга |
| ʊ | U | безударная «у» или «ю» (near-close back rounded vowel) | сухой , мужчина |
Как подключаться к сервисам Яндекса
В Яндекс.Облаке очень много сервисов, я в своей работе использовал только два:
-
Yandex Object Storage – для хранения звуковых файлов;
-
Yandex SpeechKit – для преобразования звука в текст.
Вначале, в 2017 году, Yandex Object Storage был не нужен, мы использовали Yandex SpeechKit напрямую – отправляешь wav-файл, ждешь в режиме онлайн и получаешь в текстовом виде расшифровку.
Переходим к Яндекс.Облаку.
Чтобы работать с Облаком, нужно установить тоже командный интерфейс Curl, нужно зарегистрироваться и пройти авторизацию.
Сейчас я более подробно расскажу про каждый из пунктов.
Вначале ставим Curl – это кроссплатформенная служебная программа командной строки.
Ничего сложного тут нет – просто заходим по гиперссылке https://cloud.yandex.ru/docs/cli/quickstart, скачиваем и устанавливаем.
Это нам дает возможность прямо из 1С в командной строке вызывать системные функции для работы с Яндекс.Облаком.
Далее мы:
-
Регистрируемся, получаем имя пользователя и пароль
-
В 2017 году этого было достаточно, чтобы начать работать. Сейчас, чтобы начать распознавать аудио-звонки, нам нужно создать платежный аккаунт и закинуть туда определенную сумму денег – бесплатного распознавания уже нету.
-
Далее мы создаем сервисный аккаунт, это связано с безопасностью – с каталогами Яндекс.Облака нельзя работать под общим аккаунтом, там для каждого объекта создается свой сервисный аккаунт и ему назначаются нужные права конкретно на эти объекты. В принципе, это правильно, но это немного усложнило работу.
Когда мы зарегистрировались, получаем OAuth-токен.
Как было показано предыдущих слайдах, мы установили Curl, и с его помощью запускаем команду yc init, которая привязывает профиль CLI на данном компьютере к Облаку.
В этой команде мы задаем, куда привязать профиль:
-
к какому облаку;
-
к какому каталогу;
-
и в какой зоне доступности будут происходить наши вычисления – у Яндекса на данный момент есть три зоны доступности (Владимирская, Рязанская и Московская область), где происходит расшифровка звонков.
После того как мы получили OAuth-токен, мы в принципе можем начать работать.
На данном слайде показано, для чего нужно создавать сервисный аккаунт – сервисному аккаунту мы назначаем права на использование ресурсов и каталогов.
У Яндекса есть ограничение – с одного компьютера можно запускать не более 20 потоков.
Поскольку я укладывался во все лимиты Яндекс.Облака, у меня было:
-
одно облако;
-
один каталог;
-
и два ресурса – расшифровка звонков и хранение в Yandex Object Storage.
Если если вам нужна более масштабная расшифровка звонков, то необходимо поднимать, допустим, две виртуальных машины и на них на Яндексе регистрировать два облака – это позволит масштабироваться.
Итак, мы зарегистрировались, получили OAuth-токен, теперь нужно получить IAM-токен.
IAM-токен имеет ограниченное время жизни – не более 12 часов. Соответственно, 2 раза в сутки он меняется. Поэтому если он нужен при работе, допустим, в 1С, его можно получить программно вызовом команды
yc iam create-token > » + IAMtoken