Полное руководство: команда grep в linux
Содержание:
- 1.1, общая форма команды find
- 2. Примеры использования команды Grep
- Поиск рекурсивно
- 1.3, найди и xargs
- 2. Команда grep
- A practical example of grep: Matching phone numbers
- Основные команды grep
- find примеры использования
- msggrep, mboxgrep
- Using regular expressions
- Examples
- Character classes and bracket expressions
- Основное регулярное выражение
- ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
1.1, общая форма команды find
Общая форма команды find, приведенная в документе man:
на самом делеЭти параметры обычно не используются (по крайней мере, в моей повседневной работе, я не использовал их), общая форма приведенной выше команды поиска может быть упрощена до:
| команда | Описание |
|---|---|
| path | Путь к каталогу, который ищется командой find. Например, используйте. Для представления текущего каталога и / для представления корневого каталога системы. |
| expression | Выражение можно разделить на |
| -options | Укажите общие параметры команды find, подробно описанные в следующем разделе. |
| Команда find выводит сопоставленные файлы на стандартный вывод | |
| -exec | Команда find выполняет команду оболочки, заданную этим параметром для соответствующего файла. Соответствующая команда имеет вид,нотас участиемПространство между |
| -ok | Он имеет тот же эффект, что и -exec, за исключением того, что команда оболочки, заданная этим параметром, выполняется в более безопасном режиме.Перед выполнением каждой команды будет выдано приглашение, позволяющее пользователю определить, выполнять ли ее. |
пример 1:Удалить файлы с нулевым размером файла
(Вы также можете сделать это: rm -i Или найдите ./ -size 0 | xargs rm -f &)
Пример 2:Чтобы вывести список соответствующих файлов с помощью команды ls -l, вы можете поместить команду ls -l в опцию -exec команды find:
Пример 3:В каталоге / logs найдите файлы, время изменения которых составляет до 5 дней, и удалите их:
Пример 4:Найдите в текущем каталоге все файлы, имена которых заканчиваются на .conf и время изменения которых превышает 5 дней, и удалите их, но перед удалением выведите подсказку.
Некоторые люди также описывают структуру команды find следующим образом:
2. Примеры использования команды Grep
Теперь мы увидим, как использовать команду Grep в Linux.
Как использовать Grep в общем
Чтобы понять, как работает Grep, мы посмотрим в каталоге / etc / passwd все результаты, связанные с нашим пользователем:
grep solvetic / etc / passwd
В качестве дополнительного момента помните, что можно сказать, что grep игнорирует прописные и строчные буквы в результатах, для этого мы выполним следующее:
grep -i "resoltic" / etc / passwd
Grep идеально подходит для поиска определенных терминов в известных файлах, например, мы выполним следующий поиск:
grep Solvetic Solvetic.txt
Этот же термин можно искать в разных файлах одновременно, для этого мы будем использовать следующую строку:
grep Solvetic Solvetic.txt Solvetic1.txt
Более сокращенный способ сделать это — выполнить следующее:
grep solvetic *. *
Как использовать grep для перенаправления результатов в файл в Linux
Это полезно в тех случаях, когда мы должны выполнить административные задачи над файлами позже, поэтому можно перенаправить вывод команды grep в определенный файл, например, мы сделаем следующее:
grep Solvetic Solvetic.txt> Solvetic2.txt
Как использовать grep для поиска в каталогах
Благодаря параметру -r мы сможем найти значение в доступных подкаталогах, выполним следующее:
grep -r Solvetic / домашний / решающий
Как использовать grep для отображения номера строки
Для задач аудита или расширенной поддержки идеально отображать номер строки, в которой находится указанный шаблон поиска, для этого мы можем использовать параметр -n следующим образом. Там мы находим номер строки, где находится каждое значение.
grep -n Solvetic Solvetic.txt
Как использовать grep для выделения результатов
Поскольку мы знаем, что текст во многих случаях может сбить с толку, по этой причине решение состоит в том, чтобы выделить критерии поиска, которые фокусируют наше представление непосредственно на этой строке, для этого мы будем использовать параметр цвета, например:
grep -color Solvetic Solvetic.txt
Как использовать grep для отображения строк, начинающихся или заканчивающихся указанным шаблоном
Мы можем захотеть визуализировать только результаты строк, которые начинаются или заканчиваются критериями поиска, для этого, если мы хотим найти строки, которые начинаются, мы будем использовать следующую строку:
grep ^ Solvetic Solvetic.txt
Теперь, чтобы отобразить строки, которые заканчиваются, мы будем использовать следующее:
grep Solvetic $ Solvetic.txt
Как использовать grep для печати всех строк, не видя совпадающих
Если мы хотим увидеть все строки, кроме тех, где задано желаемое значение, мы должны использовать параметр -v следующим образом:
grep -v Solvetic Solvetic.txt
Как использовать grep с другими командами
Grep, как и многие команды Linux, можно использовать одновременно с другими командами для получения более четких результатов, например, если мы хотим развернуть процессы HTTP, мы будем использовать grep рядом с ps следующим образом:
ps -ef | grep http
Как использовать grep, чтобы посчитать, сколько слов повторяется в файле
Если мы хотим узнать, сколько раз шаблон повторяется в данном файле, мы будем использовать параметр -c:
grep -c Solvetic Solvetic.txt
Как использовать grep для обратного поиска
Хотя это звучит странно, это не что иное, как отображение в результате слов, которые мы не указываем, это достигается с помощью параметра -v:
grep -v Solvetic Solvetic2.txt
Как использовать grep для просмотра сведений об оборудовании
Ранее мы видели, что мы можем комбинировать grep с другими командами для отображения результата, ну, если мы хотим получить конкретные сведения об оборудовании, мы можем использовать cat с grep следующим образом:
cat / proc / cpuinfo | grep -i 'Модель'
Во всем мире мы узнали, как использовать команду grep для доступа к гораздо более конкретным результатам поиска в Linux.
Поиск рекурсивно
Вы можете использовать ключ -r с grep для рекурсивного поиска по всем файлам в каталоге и его подкаталогах по указанному шаблону.
$ grep -r pattern /directory/to/search
Если вы не укажете каталог, grep будет просто искать ваш текущий рабочий каталог. На приведенном ниже снимке экрана grep обнаружил два файла, соответствующих нашему шаблону, и возвращает их имена файлов и каталог, в котором они находятся.

Найти вкладку
Как мы упоминали ранее в объяснении того, как искать строку, вы можете заключить текст в кавычки, если он содержит пробелы. Тот же метод будет работать для вкладок, но мы сейчас объясним, как поместить вкладку в вашу команду grep.
Поставьте пробел или несколько пробелов внутри кавычек, чтобы grep искал этот символ.
$ grep " " sample.txt
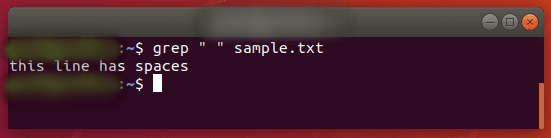
Существует несколько различных способов поиска вкладки с помощью grep, но большинство методов являются экспериментальными или могут быть несовместимыми в разных дистрибутивах.
Самый простой способ — просто найти сам символ табуляции, который вы можете создать, нажав Ctrl + V на клавиатуре, после чего нажмите Tab.
Обычно нажатие клавиши tab в окне терминала говорит терминалу, что вы хотите автоматически завершить команду, но предварительное нажатие комбинации ctrl + v приведет к тому, что символ табуляции будет записан так, как вы обычно ожидаете в текстовом редакторе. ,
$ grep " " sample.txt

1.3, найди и xargs
При использовании параметра -exec команды find для обработки сопоставленных файлов команда find передает все сопоставленные файлы в exec для выполнения. Однако некоторые системы имеют ограничения по длине команд, которые могут быть переданы в exec, так что ошибка переполнения произойдет после того, как команда find выполняется в течение нескольких минут. Обычно это сообщение об ошибке «слишком длинный столбец параметров» или «переполнение столбцов параметров». Здесь полезна команда xargs, особенно когда она используется с командой find.
Команда find передает сопоставленные файлы команде xargs, а команда xargs одновременно получает только часть файлов, а не все, в отличие от параметра -exec. Таким образом, он может обработать первую часть файла, затем следующий пакет и т. Д.
В некоторых системах использование параметра -exec инициирует соответствующий процесс для обработки каждого сопоставленного файла вместо одновременного выполнения всех сопоставленных файлов в качестве параметров, поэтому в некоторых случаях будет слишком много процессов. Проблема снижения производительности, поэтому эффективность не высокая;
С помощью команды xargs существует только один процесс. Кроме того, при использовании команды xargs, получать ли все параметры сразу или в пакетном режиме, и количество параметров, полученных каждый раз, будет определяться в соответствии с параметрами команды и соответствующими настраиваемыми параметрами в ядре системы.
Давайте посмотрим, как команда xargs используется с командой find, и приведем несколько примеров.
Команда find используется в сочетании с exec и xargs, чтобы позволить пользователям выполнять почти все команды для соответствующих файлов.
2. Команда grep
grep (глобальный поиск по регулярному выражению (RE) и распечатка строки) — это мощный инструмент для поиска текста, который может искать текст с помощью регулярных выражений и распечатывать соответствующие строки ,
A practical example of grep: Matching phone numbers
This tool can be intimidating to newbies and experienced Linux users alike. Unfortunately, even a relatively simple pattern like a phone number can result in a «scary» looking regex string.
I want to reassure you that there is no need to panic when you see expressions like this. Once you become familiar with the basics of regex, it can open up a new world of possibilities for your computing.
I’ve created a file called and written down 4 common variations of the same phone number. I am going to use grep to recognize the number pattern regardless of the format.
I’ve also added one line that will not conform to the expression to use as a control. The final line is not a standard phone number pattern, and will not be returned by the grep expression.
Contents of files are:
To «grep» the phone numbers, I am going to write my regex using meta-characters to isolate the relevant data and ignore what I don’t need.
The complete command is going to look like this:
Looks a little intense, right? Let’s break it down into chunks to get a better idea of what is happening.
Understanding regex, one segment at a time
First let’s separate the section of the RegEx that looks for the «area code» in the phone number.
A similar pattern is partially repeated to get the rest of the digits, as well. It’s important to note that the area code is sometimes encapsulated in parentheses, so you need to account for that with the expression here.
The logic of the entire area code section is encapsulated in an escaped set of round braces. You can see that my code starts with and ends with .
When you use the square brackets , you’re letting grep know that you’re looking for a number between 0 and 9. Similarly, you could use to match letters of the alphabet.
The number in the curly brackets , means that the item in the square braces is matched exactly three times.
Still confused? Don’t get stressed out. You’re going to look at this example in several ways so that you feel confident moving forward.
Let’s try looking at the logic of the area code section in pseudo-code. I’ve isolated each segment of the expression.
Pseudo-code of the Area Code RegEx
- \(
- (3-Digit Number)
- |
- 3-Digit Number
- \)
Hopefully, seeing it like this makes the regex more straightforward. In plain language you are looking for 3-digit numbers. Each digit could be 0-9, and there may or may not be parenthesis around the area code.
Then, there’s this weird bit at the end of our first section.
\?
What does it mean? The symbol means «match zero or one of the preceding character». Here, that’s referring to what is in our square brackets .
In other words, there may or may not be a hyphen that follows the digits.
Area Code
Now, let’s re-build the same block with the actual code. Then, I’ll add the other parts of the expression.
- \(
- (\{3\})
- |
- \{3\}
- \)
- \?
Prefix
To complete the phone number pattern, you can just re-purpose some of your existing code.
You don’t have to be concerned about the parenthesis surrounding the prefix, but you still may or may not have a between the prefix and the line digits of the phone number.
Line Numbers
The last section of the phone number does not require us to look for any other characters, but you need to update the expression to reflect the extra digit.
That’s it. Now let’s make sure that the expression is contained in quotes to minimize unexpected behaviors.
Here’s the complete expression again

You can see that the results are highlighted in color. This may not be the default behavior on your Linux distribution.
10 Practical Grep Command Examples for Developers
The grep command is used to find patterns in files. This tutorial shows some of the most common grep command examples that would be specifically beneficial for software developers.
Linux HandbookSylvain Leroux

Bonus Tip
If you’d like your results to be highlighted, you could add to your command. You could also add this to your shell profile as an alias so that every time you type it runs as a .
I hope you have a better understand of the grep command now. I showed just one example to explain the things. If interested, you may check out this article for more practical examples of the grep command.
Основные команды grep
Вывести все упоминания слова
Предположим вы запустили
CentOS Linux
и хотите посмотреть все установленные пакеты в названии которых есть слово
kernel
yum list installed | grep kernel
abrt-addon-kerneloops.x86_64 2.1.11-60.el7.centos @base
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
И наоборот, можно посмотреть все строки где нет слова kernel
: нужно добавить опцию -v
yum list installed | grep -v kernel
Если вам нужно найти что-то в файле, можно вместо | воспользоваться выражением
grep ‘\bkernel\b’ huge_file
Где huge_file это имя файла в текущей директории в котором мы ищем отдельные слова kernel.
То есть слова akernel или kernelz найдены не будут
Вывести всё, что начинается со слова
Если нам теперь не нужны пакеты, в которых слово
kernel
в середине, а только те, которые начинаются с
kernel добавим перед словом знак ^
yum list installed | grep ^kernel
kernel.x86_64 3.10.0-1160.el7 @anaconda
kernel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates
kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates
kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
grep -E ‘ion$’ huge_file
compensation
generation
Допустим вы знаете только начало и конец слова
grep -E ‘^to..le$’ huge_file
topbicycle
Несколько символов подряд
Найти слова с пятью гласными подряд
grep -E ‘{5}’ /usr/share/dict/words
cadiueio
Chaouia
cooeeing
euouae
Guauaenok
miaoued
miaouing
Pauiie
queueing
find примеры использования
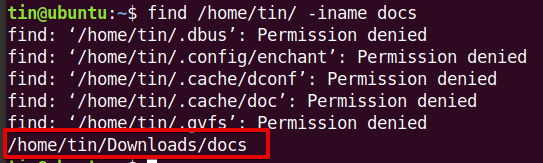
Ищем все файлы, начиная с текущей директории, название которых начинается на sonikelf:
Найти все файлы, начиная с корневой директории, название которых начинается на sonikelf:
Поиск в директориях /usr/local/man и /opt/local/man файлов, название которых начинается на sonikelf
Ищем все файлы, начиная с текущей директории, название которых начинается на sonikelf или qu
Обратите внимание, что по умолчанию все аргументы соединены с помощью логического и (опция ‘-a’). Если необходимо объединить несколько аргументов логическим или — используйте ключ ‘-o’:
Ищем графические файлы, начиная с текущего каталога (см.на кавычки):
Вывести список файлов (см. на / ) во всей файловой системе, чей размер больше 100 Мб:
Ищем файлы в указанных каталогах:
msggrep, mboxgrep
Это совсем уже узко специализированная штуковина, чтобы парсить каталоги локализации. Идет в комплекте с пакетом gettext. Программа не из разряда пользовательских, но если очень нужно, можно запустить с командной строки.
Следующий экспонат — парсер почтовых ящиков mboxgrep. Проект так и не взлетел, его разработка прекращена. По идее он должен был находить паттерны в письмах и обрабатывать вывод так как будто это отдельные файлы. Однако, для начала он эти паттерны должен уметь находить.
А он не находит.
Что странно, системные вызовы все время одни и те же, вне зависимости от поиска.
Любопытно было бы узнать, завелась ли данная программа успешно у кого-нибудь?
Ну ладно, мы увлеклись, а греп семейство еще не инвентаризировано полностью.
Using regular expressions
Grep’s functionality is further extended by using regular expressions, allowing you more flexibility in your searches. Several exist, and we will go over some of the most commons ones in the examples below:
brackets are used to match any of a set of characters.
$ grep "Class " Students.txt
This command will return any lines that say ‘Class 1’, ‘Class2’, or ‘Class 3’.
brackets with a hyphen can be used to specify a range of characters, either numerical or alphabetical.
$ grep "Class " Students.txt
We get the same output as before, but the command is much easier to type, especially if we had a bigger range of numbers or letters.
^caret is used to search for a pattern that only occurs at the beginning of a line.
$ grep "^Class" Students.txt
brackets with caret are used to exclude characters from a search pattern.
$ grep "Class " Students.txt
$ dollar sign is used to search for a pattern that only occurs at the end of a line.
$ grep "1$" Students.txt
. dot is used to match any one character, so it’s a wildcard but only for a single character.
$ grep "A….a" Students.txt
Examples
Tip
If you haven’t already seen our section, we suggest reviewing that section first.
grep chope /etc/passwd
Search /etc/passwd for user chope.
grep "May 31 03" /etc/httpd/logs/error_log
Search the Apache error_log file for any error entries that happened on May 31st at 3 A.M. By adding quotes around the string, this allows you to place spaces in the grep search.
grep -r "computerhope" /www/
Recursively search the directory /www/, and all subdirectories, for any lines of any files which contain the string «computerhope«.
grep -w "hope" myfile.txt
Search the file myfile.txt for lines containing the word «hope«. Only lines containing the distinct word «hope» are matched. Lines where «hope» is part of a word (e.g., «hopes») are not be matched.
grep -cw "hope" myfile.txt
Same as previous command, but displays a count of how many lines were matched, rather than the matching lines themselves.
grep -cvw "hope" myfile.txt
Inverse of previous command: displays a count of the lines in myfile.txt which do not contain the word «hope».
grep -l "hope" /www/*
Display the file names (but not the matching lines themselves) of any files in /www/ (but not its subdirectories) whose contents include the string «hope«.
Character classes and bracket expressions
A bracket expression is a list of characters enclosed by and . It matches any single character in that list; if the first character of the list is the caret ^ then it matches any character not in the list. For example, the regular expression matches any single digit.
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale’s collating sequence and character set. For example, in the default C locale, is equivalent to . Many locales sort characters in dictionary order, and in these locales is often not equivalent to ; it might be equivalent to , for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.
Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are , , , , , , , , , , and . For example, ] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as . (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most metacharacters lose their special meaning inside bracket expressions. To include a literal place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal —, place it last.
Основное регулярное выражение
GNU Grep имеет два набора функций регулярных выражений, Basic и Extended. По умолчанию интерпретирует шаблон как основное регулярное выражение.
При использовании в основном режиме регулярных выражений все остальные символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу. Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (символ каретки), чтобы сопоставить выражение в начале строки. В следующем примере строка ^kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
grep «^kangaroo» file.txt
Используйте символ $ (доллар), чтобы соответствовать выражению в конце строки. В следующем примере строка kangaroo$ будет соответствовать только в том случае, если она встречается в самом конце строки.
grep «kangaroo$» file.txt
Используйте . (точка) символ для соответствия любому отдельному символу. Например, чтобы сопоставить все, что начинается с kan затем имеет два символа и заканчивается строкой roo, вы можете использовать следующий шаблон:
grep «kan..roo» file.txt
использование (скобки) для соответствия любому отдельному символу, заключенному в скобки. Например, найдите строки, которые содержат accept или « accent, вы можете использовать следующий шаблон:
grep «accet» file.txt
использование (скобки) для соответствия любому отдельному символу, заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a, такой как coca, cobalt и т. Д., Но не будет совпадать со строками, содержащими cola,
grep «coa» file.txt
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
С теорией покончено, теперь перейдем к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
ПОИСК ТЕКСТА В ФАЙЛАХ
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
ВЫВЕСТИ НЕСКОЛЬКО СТРОК
Например, мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк, ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после нее.
Выведет целевую строку и 4 строчки до нее
Выведет по две строки с верху и снизу от вхождения.
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ В GREP
Регулярные выражения grep — очень мощный инструмент в разы расширяющий возможности поиска текста в файлах grep. Для активации этого режима используйте опцию -e. Рассмотрим несколько примеров:
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
Поиск в конце строки, спецсимвол «$»:
Найдем все строки которые содержат цифры:
Вообще, регулярные выражения grep это очень обширная тема, в этой статье я лишь показал несколько примеров, чтобы дать вам понять что это. Как вы увидели, таким образом, поиск текста в файлах grep становиться еще гибче. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим их и пойдем дальше.
РЕКУРСИВНОЕ ИСПОЛЬЗОВАНИЕ GREP
Если вам нужно провести поиск текста grep в нескольких файлах, размещенных в одном каталоге или подкаталогах, например, в файлах конфигурации Apache — /etc/apache2/ — используйте рекурсивный поиск. Для включения рекурсивного поиска в grep есть опция -r. Следующая команда займется поиском текста в файлах Linux во всех подкаталогах /etc/apache2 на предмет вхождения строки mydomain.com:
В выводе вы получите:
Здесь перед найденной строкой указано имя файла в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
ПОИСК СЛОВ В GREP
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить grep искать по содержимому файлов в linux только те строки, которые выключают искомые слова с помощью опции -w:
ПОИСК ДВУХ СЛОВ
Можно искать по содержимому файла не одно слово, а целых несколько. Чтобы искать два разных слова используйте команду egrep:
КОЛИЧЕСТВО ВХОЖДЕНИЙ СТРОКИ
Утилита Grep может сообщить сколько раз определенная строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки в которой найдено вхождение, например:
Получим:
ИНВЕРТИРОВАННЫЙ ПОИСК В GREP
Команда grep linux может быть использована для поиска строк в файле Linux которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
ВЫВОД ИМЕНИ ФАЙЛА
Вы можете указать grep выводить только имя файла в котом было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary: