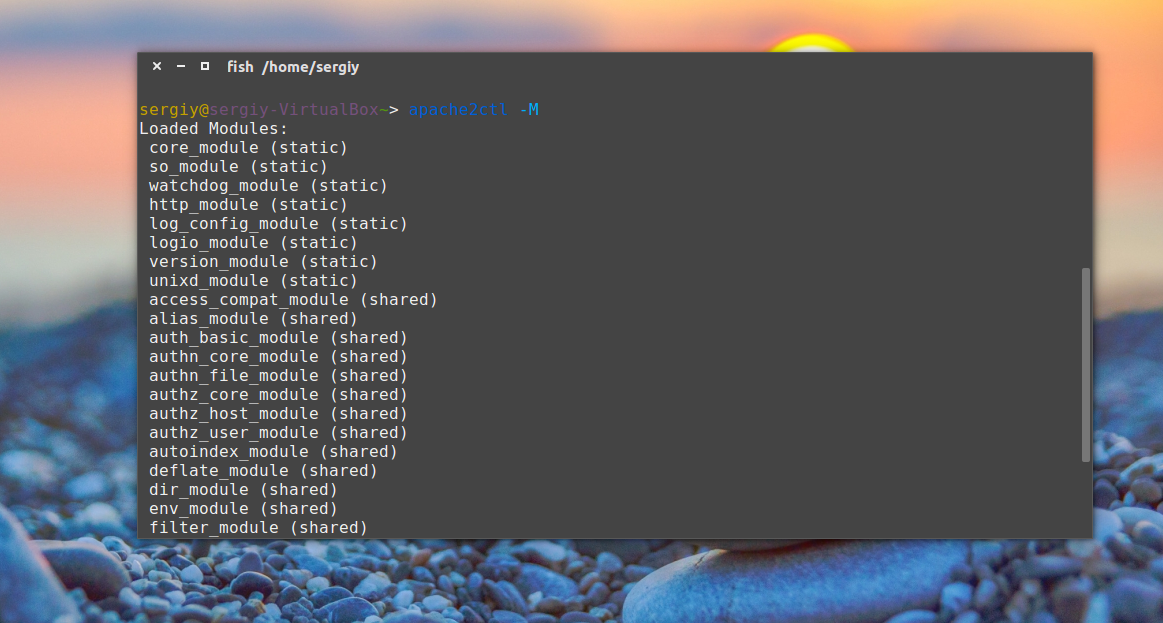
Http/1.1 и http/2: что это, чем отличаются, преимущества и как подключить протокол
Содержание:
Что такое HTTP/2 и зачем он нужен
Протокол HTTP/1.1 используется с 1999 года и со временем обрел одну существенную проблему. Современные сайты, в отличие от того, что было распространено в 1999-м году, используют множество различных элементов: скрипты на Javascript, стили на CSS, иногда еще и flash-анимацию. При передаче всего этого хозяйства между браузером и сервером создаются несколько соединений.
Протокол HTTP/2 существенно ускоряет открытие сайтов за счет следующих особенностей:
соединения: несколько запросов могут быть отправлены через одно TCP-соединение, и ответы могут быть получены в любом порядке. Отпадает необходимость держать несколько TCP-соединений;
приоритеты потоков: клиент может задавать серверу приоритеты — какого типа ресурсы для него более важны, чем другие;
сжатие заголовка: размер заголовка HTTP может быть сокращен;
push-отправка данных со стороны сервера: сервер может отправлять клиенту данные, которые тот еще не запрашивал, например, на основании данных о том, какую следующую страницу открывают пользователи.
Замеряем пульс российского диджитал-консалтинга
Какие консалтинговые услуги востребованы на российском рынке, и как они меняют бизнес-процессы? Представляете компанию-заказчика диджитал-услуг?
Примите участие в исследовании Convergent, Ruward и Cossa!
Разработка протокола HTTP/2 основывалась на другом протоколе SPDY, который был разработан Google, но компания Google уже объявила о том, что откажется от дальнейшей поддержки SPDY в пользу более многообещающего HTTP/2.
Коды состояния
В ответ на запрос от клиента, сервер отправляет ответ, который содержит, в том числе, и код состояния. Данный код несёт в себе особый смысл для того, чтобы клиент мог отчётливей понять, как интерпретировать ответ:
1xx: Информационные сообщения
Набор этих кодов был введён в HTTP/1.1. Сервер может отправить запрос вида: Expect: 100-continue, что означает, что клиент ещё отправляет оставшуюся часть запроса. Клиенты, работающие с HTTP/1.0 игнорируют данные заголовки.
2xx: Сообщения об успехе
Если клиент получил код из серии 2xx, то запрос ушёл успешно. Самый распространённый вариант — это 200 OK. При GET запросе, сервер отправляет ответ в теле сообщения. Также существуют и другие возможные ответы:
- 202 Accepted: запрос принят, но может не содержать ресурс в ответе. Это полезно для асинхронных запросов на стороне сервера. Сервер определяет, отправить ресурс или нет.
- 204 No Content: в теле ответа нет сообщения.
- 205 Reset Content: указание серверу о сбросе представления документа.
- 206 Partial Content: ответ содержит только часть контента. В дополнительных заголовках определяется общая длина контента и другая инфа.
3xx: Перенаправление
Своеобразное сообщение клиенту о необходимости совершить ещё одно действие. Самый распространённый вариант применения: перенаправить клиент на другой адрес.
- 301 Moved Permanently: ресурс теперь можно найти по другому URL адресу.
- 303 See Other: ресурс временно можно найти по другому URL адресу. Заголовок Location содержит временный URL.
- 304 Not Modified: сервер определяет, что ресурс не был изменён и клиенту нужно задействовать закэшированную версию ответа. Для проверки идентичности информации используется ETag (хэш Сущности — Enttity Tag);
4xx: Клиентские ошибки
Данный класс сообщений используется сервером, если он решил, что запрос был отправлен с ошибкой. Наиболее распространённый код: 404 Not Found. Это означает, что ресурс не найден на сервере. Другие возможные коды:
- 400 Bad Request: вопрос был сформирован неверно.
- 401 Unauthorized: для совершения запроса нужна аутентификация. Информация передаётся через заголовок Authorization.
- 403 Forbidden: сервер не открыл доступ к ресурсу.
- 405 Method Not Allowed: неверный HTTP метод был задействован для того, чтобы получить доступ к ресурсу.
- 409 Conflict: сервер не может до конца обработать запрос, т.к. пытается изменить более новую версию ресурса. Это часто происходит при PUT запросах.
5xx: Ошибки сервера
Ряд кодов, которые используются для определения ошибки сервера при обработке запроса. Самый распространённый: 500 Internal Server Error. Другие варианты:
- 501 Not Implemented: сервер не поддерживает запрашиваемую функциональность.
- 503 Service Unavailable: это может случиться, если на сервере произошла ошибка или он перегружен. Обычно в этом случае, сервер не отвечает, а время, данное на ответ, истекает.
3.6 Кодирование передачи (Transfer Codings).
Значения кодирования передачи используются для указания
преобразования кодирования, которое было или должно быть применено
к телу объекта (entity-body) в целях гарантирования «безопасной
передачи» по сети. Оно отличается от кодирования содержимого тем,
что кодирование передачи — это свойство сообщения, а не
первоначального объекта.
transfer-coding = "chunked" | transfer-extension
transfer-extension = token
Все значения кодирования передачи (transfer-coding) не
чувствительны к регистру. HTTP/1.1 использует значения кодирования
передачи (transfer-coding) в поле заголовка Transfer-Encoding
().
Кодирования передачи — это аналоги значений
Content-Transfer-Encoding MIME, которые были разработаны для
обеспечения безопасной передачи двоичных данных при использовании
7-битного обслуживания передачи. Однако безопасный транспорт
имеет другое предназначение для чисто 8-битного протокола передачи.
В HTTP единственая опасная характеристика тела сообщения вызвана
сложностью определения точной длины тела сообщения (),
или желанием шифровать данные при пользовании общедоступным
транспортом.
Кодирование по кускам (chunked encoding) изменяет тело сообщения
для передачи его последовательностью кусков, каждый из которых
имеет собственный индикатор размера, сопровождаемым опциональным
завершителем, содержащим поля заголовка объекта. Это позволяет
динамически создаваемому содержимому передаваться вместе с
информацией, необходимой получателю для проверки полноты получения
сообщения.
Chunked-Body = *chunk
"0" CRLF
footer
CRLF
chunk = chunk-size CRLF
chunk-data CRLF
hex-no-zero = <HEX за исключением "0">
chunk-size = hex-no-zero *HEX
chunk-ext = *( ";" chunk-ext-name )
chunk-ext-name = token
chunk-ext-val = token | quoted-string
chunk-data = chunk-size(OCTET)
footer = *entity-header
Кодирование по кускам (chunked encoding) оканчивается куском
нулевого размера, следующим за завершителем, оканчивающимся пустой
строкой. Цель завершителя состоит в эффективном методе обеспечения
информации об объекте, который сгенерирован динамически; приложения
НЕ ДОЛЖНЫ посылать в завершителе поля заголовка, которые явно не
предназначены для использования в завершителе, такие как
Content-MD5 или будущие расширения HTTP для цифровых подписей и
других возможностей.
Примерный процесс декодирования Chunked-Body представлен в
.
Все HTTP/1.1 приложения ДОЛЖНЫ быть в состоянии получать и
декодировать кодирование передачи «по кускам» («chunked» transfer
coding), и ДОЛЖНЫ игнорировать расширения кодирования передачи,
которые они не понимают. Серверу, который получил тело объекта со
значением кодирования передачи, которое он не понимает, СЛЕДУЕТ
возвратить ответ с кодом 501 (Не реализовано, Not Implemented) и
разорвать соединение. Сервер НЕ ДОЛЖЕН посылать поля кодирования
передачи (transfer-coding) HTTP/1.0 клиентам.
Краткий обзор протоколов HTTP/1.1 и HTTP/2
Чтобы лучше понимать контекст конкретных изменений, которые HTTP/2 внес в HTTP/1.1, давайте ознакомимся с историей разработки и основными принципами работы каждого из релизов протокола.
HTTP/1.1
Разработанный Тимоти Бернерсом-Ли (Timothy Berners-Lee) в 1989 году в качестве стандарта связи для Всемирной паутины, HTTP – это протокол верхнего (прикладного) уровня, который обеспечивает обмен информацией между клиентским компьютером и локальным или удаленным веб-сервером. В этом процессе клиент отправляет текстовый запрос на сервер, вызывая метод (GET или POST). В ответ сервер отправляет клиенту ресурс, например, HTML-страницу.
Предположим, вы посещаете веб-сайт по домену www.example.com. При переходе по этому URL-адресу веб-браузер на вашем компьютере отправляет HTTP-запрос в виде текстового сообщения:
Этот запрос использует метод GET, который запрашивает данные с хост-сервера, указанного после Host:. В ответ на этот запрос веб-сервер example.com возвращает клиенту HTML-страницу вместе с изображениями, таблицами стилей или другими ресурсами, запрашиваемыми в HTML
Обратите внимание, что при первом обращении к данным клиенту возвращаются не все ресурсы. Запросы и ответы будут передаваться между сервером и клиентом до тех пор, пока веб-браузер не получит все ресурсы, необходимые для отображения содержимого HTML-страницы на вашем экране
Этот обмен запросами и ответами можно объединить в единый прикладной уровень интернет-протоколов, расположенный над транспортным уровнем (обычно по протоколу TCP) и сетевым уровнем (по протоколу IP).
| Хост (браузер) | Цель (веб-сервер) | |
| ↓ | ↑ | |
| Прикладной уровень (HTTP) | Прикладной уровень (HTTP) | |
| ↓ | ↑ | |
| Транспортный уровень (TCP) | Транспортный уровень (TCP) | |
| ↓ | ↑ | |
| Сетевой уровень (IP) | Сетевой уровень (IP) | |
| ↓ | ↑ | |
| Канальный уровень | Канальный уровень | |
| ————→ Интернет ————→ |
Можно еще долго обсуждать более низкие уровни этого стека, но чтобы получить общее представление о HTTP/2, достаточно знать только эту модель абстрактного и то, где в ней находится HTTP.
HTTP/2
HTTP/2 появился как протокол SPDY, разработанный в основном в Google с целью снижения задержки загрузки веб-страниц такими методами, как сжатие, мультиплексирование и приоритизация. Этот протокол послужил шаблоном для HTTP/2, когда группа httpbis (это рабочая группа Hypertext Transfer Protocol) из IETF (Internet Engineering Task Force) объединила стандарт. Так в мае 2015 года случился релиз HTTP/2. С самого начала многие браузеры (включая Chrome, Opera, Internet Explorer и Safari) поддерживали эту попытку стандартизации. Частично благодаря этой поддержке с 2015 года наблюдается высокий уровень внедрения протокола, особенно среди новых сайтов.
С технической точки зрения, одной из наиболее важных особенностей, которые отличают HTTP/1.1 и HTTP/2, является двоичный уровень кадрирования, который можно рассматривать как часть прикладного уровня в стеке интернет-протоколов. В отличие от HTTP/1.1, в котором все запросы и ответы хранятся в простом текстовом формате, HTTP/2 использует двоичный уровень кадрирования для инкапсуляции всех сообщений в двоичном формате, при этом сохраняя семантику HTTP (методы, заголовки). API прикладного уровня по-прежнему создает сообщения в обычных форматах HTTP, но нижележащий уровень преобразовывает эти сообщения в двоичные. Благодаря этому веб-приложения, созданные до HTTP/2, могут продолжать работать как обычно при взаимодействии с новым протоколом.
Преобразование сообщений в двоичные позволяет HTTP/2 применять новые подходы к доставке данных, недоступные в HTTP/1.1.
В следующем разделе мы рассмотрим модель доставки HTTP/1.1, а также расскажем, какие новые модели стали возможны благодаря HTTP/2.
HTTP-сеанс [ править ]
HTTP-сеанс — это последовательность сетевых транзакций запрос – ответ. Клиент HTTP инициирует запрос, устанавливая соединение протокола управления передачей (TCP) с определенным портом на сервере (обычно порт 80, иногда порт 8080; см. Список номеров портов TCP и UDP ). HTTP-сервер, прослушивающий этот порт, ожидает сообщения запроса от клиента. После получения запроса сервер отправляет обратно строку состояния, например « HTTP / 1.1 200 OK », и собственное сообщение. Тело этого сообщения обычно является запрошенным ресурсом, хотя также может быть возвращено сообщение об ошибке или другая информация.
Постоянные соединения править
В HTTP / 0.9 и 1.0 соединение закрывается после одной пары запрос / ответ. В HTTP / 1.1 был введен механизм keep-alive, при котором соединение можно было повторно использовать для более чем одного запроса. Такие постоянные соединения заметно сокращают задержку запроса, поскольку клиенту не нужно повторно согласовывать соединение TCP 3-Way-Handshake после отправки первого запроса. Еще один положительный побочный эффект заключается в том, что в целом соединение со временем становится быстрее из-за механизма TCP.
Версия 1.1 протокола также улучшила оптимизацию полосы пропускания для HTTP / 1.0. Например, в HTTP / 1.1 введено кодирование передачи по частям, позволяющее передавать контент в постоянных соединениях в потоковом режиме, а не в буфере. Конвейерная обработка HTTP дополнительно сокращает время задержки, позволяя клиентам отправлять несколько запросов, прежде чем ждать каждого ответа. Еще одним дополнением к протоколу стало обслуживание байтов , когда сервер передает только часть ресурса, явно запрошенную клиентом.
Состояние сеанса HTTP править
HTTP — это протокол без сохранения состояния . Протокол без сохранения состояния не требует, чтобы HTTP-сервер сохранял информацию или статус о каждом пользователе в течение нескольких запросов. Однако некоторые веб-приложения реализуют состояния или сеансы на стороне сервера, используя, например, файлы cookie HTTP или скрытые переменные в веб-формах .
Сжатие
Распространенным методом оптимизации веб-приложений является использование алгоритмов сжатия для уменьшения размера HTTP-сообщений, которые передаются между клиентом и сервером. HTTP/1.1 и HTTP/2 используют эту стратегию, но в первом протоколе существуют проблемы с реализацией, которые запрещают сжатие всего сообщения. В следующем разделе мы обсудим, почему это происходит и как HTTP/2 может решить эту проблему.
HTTP/1.1
Такие программы, как gzip, давно используются для сжатия данных, отправляемых в сообщениях HTTP, особенно для уменьшения размера файлов CSS и JavaScript. Однако компонент заголовка сообщения всегда отправляется в виде простого текста. Несмотря на то, что каждый заголовок довольно мал, объем этих несжатых данных увеличивает нагрузку на соединение по мере того как клиент отправляет больше запросов. Особенно это касается сложных веб-приложений с тяжелым API, которые требуют много разных ресурсов и, следовательно, много разных запросов. Кроме того, использование файлов cookie иногда может значительно увеличить заголовки, что, в свою очередь, увеличивает потребность в сжатии.
Чтобы устранить это узкое место, HTTP/2 использует сжатие HPACK, которое позволяет уменьшить размер заголовков.
HTTP/2
Одна из функций, которая постоянно всплывает при обсуждении HTTP/2 – это двоичный уровень кадрирования, который предоставляет больший контроль над мелкими деталями. Это касается и сжатия заголовков. HTTP/2 может отделить заголовки от остальных данных, в результате чего получаются кадр заголовка и кадр данных. Программа сжатия HPACK (специальная для HTTP/2) может затем сжать этот кадр заголовка. Этот алгоритм может кодировать метаданные заголовка с помощью кодирования Хаффмана, тем самым значительно уменьшая его размер. Кроме того, HPACK может отслеживать ранее переданные поля метаданных и дополнительно сжимать их в соответствии с динамически измененным индексом между клиентом и сервером. Например, рассмотрим следующие два запроса:
Поля в этих запросах (method, scheme, host, accept и user-agent) имеют одинаковые значения; только поле path использует другое значение. В результате при отправке запроса 2 клиент может использовать HPACK для отправки индексированных значений, необходимых для восстановления общих полей и нового кодирования поля path. Кадры заголовка будут выглядеть следующим образом:
Используя HPACK и другие методы сжатия, HTTP/2 предоставляет еще одну функцию, которая позволяет уменьшить задержку между клиентом и сервером.
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
HTTP-заголовки
HTTP-сообщение состоит из начальной строки, за которой следуют набор заголовков, пустая строка и некоторые данные. Начальная строка задает действие, требуемое от сервера, тип возвращаемых данных или код состояния.
HTTP-заголовки можно подразделить на три крупные категории: заголовки, посылаемые в запросе, заголовки, посылаемые в ответе, и те, которые можно включать как в запросы, так и в ответы. Заголовки запросов указывают возможности клиента, например, типы документов, которые может обработать клиент, в то время как заголовки ответов предоставляют информацию о возвращенном документе.
Заголовки запросов
К числу наиболее важных HTTP-заголовков, которые можно включать в запросы, но нельзя включать в ответы, относятся:
- Заголовок Accept
-
Это список MIME-типов, принимаемых клиентом, в формате тип/подтип. Элементы списка должны разделяться запятыми:
Accept: text/html, image/gif, */*
Элемент */* указывает, что все типы будут приняты и обработаны клиентом. Если тип запрошенного файла не может быть обработан клиентом, возвращается ошибка HTTP 406 «Not acceptable» (недопустимо).
- Заголовок From
-
Указывает адрес электронной почты в Интернете учетной записи пользователя, под которой работает клиент, направивший запрос:
From: alexerohinzzz@gmail.com
- Заголовок Referer
-
Позволяет клиенту указать адрес (URI) ресурса, из которого получен запрашиваемый URI. Этот заголовок дает возможность серверу сгенерировать список обратных ссылок на ресурсы для будущего анализа, регистрации, оптимизированного кэширования и т.д. Он также позволяет прослеживать с целью последующего исправления устаревшие или введенные с ошибками ссылки:
Referer: http://www.professorweb.ru
- Заголовок User-Agent
-
Представляет собой строку, идентифицирующую приложение-клиент (обычно браузер) и платформу, на которой оно выполняется. Общий формат имеет вид: программа/версия библиотека/версий, но это не неизменный формат:
User-Agent: Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.56 Safari/537.17
Эта информация может использоваться в статистических целях, для отслеживания нарушений протокола и для автоматического распознавания клиента. Она позволяет приспособить ответ так, чтобы не нарушить ограниченные возможности конкретного клиента, например неспособность поддерживать HTML-таблицы.
Заголовки ответов
В ответы могут включаться следующие заголовки:
- Заголовок Content-Type
-
Используется для указания типа данных, отправляемых получателю или, в случае метода HEAD, тип данных, который был бы отправлен в ответ на запрос GET:
Content-Type: text/html
- Заголовок Expires
-
Представляет собой момент времени, после которого информация в документе становится недостоверной. Клиенты, использующие кэширование, в частности прокси-серверы, не должны хранить в кэше эту копию ресурса после заданного времени, если только состояние копии не было обновлено более поздним обращением к исходному серверу:
Expires: Fri, 19 Aug 2012 16:00:00 GMT
- Заголовок Location
-
Определяет точное расположение другого ресурса, к которому может быть перенаправлен клиент. Если это значение представляет собой полный URL, сервер возвращает клиенту «redirect» для непосредственного извлечения указанного объекта:
Location: http://www.samplesite.com
Если ссылка на другой файл относится к серверу, должен указываться частичный URL.
- Заголовок Server
-
Содержит информацию о программном обеспечении, используемом исходным сервером для обработки запроса:
Server: Microsoft-IIS/7.0
Общие заголовки
Несколько заголовков могут включаться как в запрос, так и в ответ, например:
- Заголовок Date
-
Используется для установки даты и времени создания сообщения:
Date: Tue, 16 Aug 2012 18:12:31 GMT
- Заголовок Connection
-
В НТТР/1.0 мы могли использовать в запросе заголовок Connection, указывая, что хотим сохранить соединение после отправки ответа. Теперь такое поведение принято по умолчанию, и в HTTP/1.1 можно использовать заголовок Connection, чтобы указать, что постоянное соединение не нужно:
Connection: close
Функциональность
Механизм и концепция HTTP включает в себя то, что файлы связаны с другими файлами через ряд ссылок. Этот выбор вызовет дополнительные запросы на передачу. Любое устройство веб-сервера на самом деле содержит программу, которая называется HTTP-демоном, которая предназначена для прогнозирования HTTP-запросов и обработки их по их получении. Типичный веб-браузер — это HTTP-клиент, который постоянно посылает запросы на серверные устройства. Пользователь вводит запросы в файл, проходя через веб-файл, который в данном случае обычно является URL-адресом, или нажимает на ссылку; браузер формирует HTTP-запрос, а затем отправляет его на IP-адрес, указанный через URL.
HTTP следует заданному циклу всякий раз, когда посылает запрос:
- Браузер запросит HTML-страницу. Затем сервер возвращает HTML-файл с хоста.1
- Браузер запросит таблицу стилей. Затем сервер возвращает файл CSS.
- Браузер запрашивает изображение в формате JPG. Сервер возвращает файл JPG.
- Браузер запросит код JavaScript (язык программирования). После этого сервер возвращает JS-файл.
- Браузер запрашивает различные формы данных. Сервер возвращает данные в виде XML или JSON файлов.
HTTP/1.0 — 1996
В отличие от HTTP/0.9, спроектированного только для HTML-ответов, HTTP/1.0 справляется и с другими форматами: изображения, видео, текст и другие типы контента. В него добавлены новые методы (такие, как POST и HEAD). Изменился формат запросов/ответов. К запросам и ответам добавились HTTP-заголовки. Добавлены коды состояний, чтобы различать разные ответы сервера. Введена поддержка кодировок. Добавлены составные типы данных (multi-part types), авторизация, кэширование, различные кодировки контента и ещё многое другое.
Вот так выглядели простые запрос и ответ по протоколу HTTP/1.0:
Помимо запроса клиент посылал персональную информацию, требуемый тип ответа и т.д. В HTTP/0.9 клиент не послал бы такую информацию, поскольку заголовков попросту не существовало.
Пример ответа на подобный запрос:
В начале ответа стоит HTTP/1.0 (HTTP и номер версии), затем код состояния — 200, затем — описание кода состояния.
В новой версии заголовки запросов и ответов были закодированы в ASCII (HTTP/0.9 весь был закодирован в ASCII), а вот тело ответа могло быть любого контентного типа — изображением, видео, HTML, обычным текстом и т. п. Теперь сервер мог послать любой тип контента клиенту, поэтому словосочетание «Hyper Text» в аббревиатуре HTTP стало искажением. HMTP, или Hypermedia Transfer Protocol, пожалуй, стало бы более уместным названием, но все к тому времени уже привыкли к HTTP.
Один из главных недостатков HTTP/1.0 — то, что вы не можете послать несколько запросов во время одного соединения. Если клиенту надо что-либо получить от сервера, ему нужно открыть новое TCP-соединение, и, как только запрос будет выполнен, это соединение закроется. Для каждого следующего запроса нужно создавать новое соединение.
Почему это плохо? Давайте предположим, что вы открываете страницу, содержащую 10 изображений, 5 файлов стилей и 5 JavaScript файлов. В общей сложности при запросе к этой странице вам нужно получить 20 ресурсов — а это значит, что серверу придётся создать 20 отдельных соединений. Такое число соединений значительно сказывается на производительности, поскольку каждое новое TCP-соединение требует «тройного рукопожатия», за которым следует медленный старт.
Тройное рукопожатие
«Тройное рукопожатие» — это обмен последовательностью пакетов между клиентом и сервером, позволяющий установить TCP-соединение для начала передачи данных.
- SYN — Клиент генерирует случайное число, например, x, и отправляет его на сервер.
- SYN ACK — Сервер подтверждает этот запрос, посылая обратно пакет ACK, состоящий из случайного числа, выбранного сервером (допустим, y), и числа x + 1, где x — число, пришедшее от клиента.
- ACK — клиент увеличивает число y, полученное от сервера и посылает y + 1 на сервер.
Примечание переводчика: SYN — синхронизация номеров последовательности, (англ. Synchronize sequence numbers). ACK — поле «Номер подтверждения» задействовано (англ. Acknowledgement field is significant).
Только после завершения тройного рукопожатия начинается передача данных между клиентом и сервером. Стоит заметить, что клиент может посылать данные сразу же после отправки последнего ACK-пакета, однако сервер всё равно ожидает ACK-пакет, чтобы выполнить запрос.
Тем не менее, некоторые реализации HTTP/1.0 старались преодолеть эту проблему, добавив новый заголовок Connection: keep-alive, который говорил бы серверу «Эй, дружище, не закрывай это соединение, оно нам ещё пригодится». Однако эта возможность не была широко распространена, поэтому проблема оставалась актуальна.
Помимо того, что HTTP — протокол без установления соединения, в нём также не предусмотрена поддержка состояний. Иными словами, сервер не хранит информации о клиенте, поэтому каждому запросу приходится включать в себя всю необходимую серверу информацию, без учёта прошлых запросов. И это только подливает масла в огонь: помимо огромного числа соединений, которые открывает клиент, он также посылает повторяющиеся данные, излишне перегружая сеть.