Изучаем управление базами данных: — 7 лучших бесплатных систем с открытым исходным кодом
Содержание:
- Объектный / табличный доступ к данным
- С чего начать создание базы знаний?
- Проверка на соединение с базой данных
- SQLite
- Диапазон значений в Excel
- Создание таблицы SQL
- Создание новой базы данных MySQL
- Классификация баз данных
- Модель работы с базой данных
- Зачем она нужна
- Нормализация базы данных
- Что может храниться в MySQL
- Как хранится информация в БД
- Типы движков баз данных MySQL
- Данные
- Как узнать имя сервера, имя пользователя и пароль для подключения к базе данных MySQL?
- Иерархические
- Типы баз данных
- Создание базы данных на T-SQL (CREATE DATABASE)
Объектный / табличный доступ к данным
Штатной возможностью «1С:Предприятия 8» является поддержка двух способов доступа к данным — объектного (для чтения и записи) и табличного (для чтения).
В объектной модели разработчик оперирует объектами встроенного языка. В этой модели обращения к объекту, например документу, происходят как к единому целому — он полностью загружается в память, вместе с вложенными таблицами, к которым можно обращаться средствами встроенного языка как к коллекциям записей и т.д.

При манипулировании данными в объектной модели обеспечивается сохранение целостности объектов, кэширование объектов, вызов соответствующих обработчиков событий и т.д.
В табличной модели все множество объектов того или иного класса представляется как совокупность связанных между собой таблиц, к которым можно обращаться при помощи запросов — как к отдельной таблице, так и к нескольким таблицам во взаимосвязи:

В этом случае разработчик получает доступ к данным сразу нескольких объектов, что очень удобно для анализа больших объемов данных, например, при создании отчетов. Однако в силу того, что данные, выбираемые таким способом, содержат не все, а лишь некоторые реквизиты анализируемых объектов, табличный способ доступа не позволяет изменять эти данные.
С чего начать создание базы знаний?
Начните с малого
В качестве минимального функционала вы можете создать небольшой раздел FAQ, в котором разместите ответы на часто задаваемые вопросы
Важно, чтобы эти вопросы были реальными, а не выдуманными. Чтобы сформировать их список, можно проанализировать запросы, с которыми чаще всего пользователи обращаются в поддержку
По мере роста продукта вы будете пополнять свой FAQ, который со временем станет полноценным разделом на вашем сайте.
Подберите инструмент
В самом начале вы можете обойтись простой статической страницей с FAQ. Но совсем скоро вам понадобится инструмент, через который можно будет быстро добавлять новые статьи и редактировать старые. Если вы располагаете ресурсами разработки, идеальным решением будет создание собственной админки, через которую вы будете работать с базой знаний. Если ваш сайт на WordPress, можно подключить один из бесплатных плагинов для базы знаний. Например, KnowledgeBase или EchoKnowledgeBase. Возможно, вы используете стороннюю helpdesk-систему — как правило, в них есть готовые модули для создания базы знаний.
Выделите команду для поддержки базы знаний
Особенность информационного контента состоит в том, что он достаточно быстро устаревает. Поэтому вам нужна команда, которая будет поддерживать базу знаний в актуальном состоянии. Для начала это может быть один человек. Но с развитием бизнеса будет увеличиваться и число статей на сайте, соответственно, с каждым годом все больше и больше статей нужно будет проверять и актуализировать. Одному здесь уже не справиться.
Привлекайте сотрудников к написанию статей
Кто лучше разбирается в особенностях сервисов, которые вы предоставляете, как не сотрудники компании? Мы в REG.RU подключаем продакт-менеджеров для уточнения концептуальных вопросов по нашим услугам. А также нам часто помогают сотрудники техподдержки. Они всегда на связи с клиентами и точно знают, какие вопросы у них возникают и как на них лучше ответить. У вас может быть договорённость с определённым кругом экспертов, которые охотно согласятся помочь с написанием инструкций.
Проверка на соединение с базой данных
При помощи языка программирования PHP можно осуществить проверку на правильное соединение с базой данных. Создайте файл php и внесите этот код:
<?php
$link = mysql_connect('localhost', '<имя_базы_данных>', '<пароль_базы_данных>');
if (!$link) {
die ('Ошибка соединения!' . mysql_error());
}
echo 'Успешное соедининение';
mysql_close($link);
?>
- <имя_базы_данных> — указать имя базы данных
- <пароль_базы_данных> — указать созданный пароль для базы данных
Загрузите этот php файл на сервер и далее перейдите на страницу этого файла. Если всё было сделано правильно, то увидите соответствующее уведомление!
SQLite
Провозгласившая себя самой распространенной СУБД в мире, SQLite зародилась в 2000 году и используется Apple, , Microsoft и . Каждый релиз тщательно тестируется. Разработчики SQLite предоставляют пользователям списки ошибок, а также хронологию изменений кода каждой версии.
Достоинства
- Нет отдельного серверного процесса;
- Формат файла – кросс-платформенный;
- Транзакции соответствуют требованиям ACID;
- Доступна профессиональная поддержка.
Недостатки
Не рекомендуется для:
- клиент-серверных приложений;
- крупномасштабных сайтов;
- больших наборов данных;
- программ с высокой степенью многопоточности.
Диапазон значений в Excel
Существует несколько видов диапазонов значений. Диапазон, с которым мы работаем, называется динамическим. Это означает, что все проименованные ячейки в базе данных могут изменять свои границы. Их изменение происходит в зависимости от количества значений в определенном диапазоне.
Чтобы получился динамический диапазон, необходимо использовать формулу СМЕЩ. Она, независимо от того, как были заданы аргументы, возвращает ссылку на исходные данные. В выпадающем списке, который получится в итоге, не должно встречаться пустых значений. С этим как раз превосходно справляется динамический диапазон. Он задается двумя координатами ячеек: верхней левой и правой нижней, словно по диагонали
Поэтому нужно обратить внимание на место, откуда начинается ваша таблица, а точнее, на координаты верхней левой ячейки. Пусть табличка начинается в месте А5
Это значение и будет верхней левой ячейкой диапазона. Теперь, когда первый искомый элемент найден, перейдем ко второму.
Нижнюю правую ячейку определяют такие аргументы, как ширина и высота. Значение последней пусть будет равно 1, а первую вычислит формула СЧЁТ3(Родители!$B$5:$I$5).
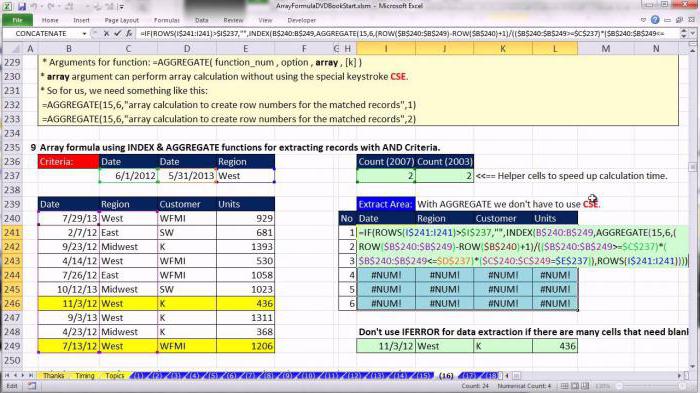
Итак, в поле диапазона записываем =СМЕЩ(Родители!$A$5;0;0;СЧЁТЗ(Родители!$A:$A)-1;1). Нажимаем клавишу ОК. Во всех последующих диапазонах букву A меняем на B, C и т. д.
Работа с базой данных в Excel почти завершена. Возвращаемся на первый лист и создаем раскрывающиеся списки на соответствующих ячейках. Для этого кликаем на пустой ячейке (например B3), расположенной под полем «ФИО родителей». Туда будет вводиться информация. В окне «Проверка вводимых значений» во вкладке под названием «Параметры» записываем в «Источник» =ФИО_родителя_выбор. В меню «Тип данных» указываем «Список».
Аналогично поступаем с остальными полями, меняя название источника на соответствующее данным ячейкам. Работа над выпадающими списками почти завершена. Затем выделяем третью ячейку и «протягиваем» ее через всю таблицу. База данных в Excel почти готова!
Создание таблицы SQL
Новые таблицы добавляются в существующую базу данных с помощью оператора CREATE TABLE SQL. За оператором CREATE TABLE следует имя создаваемой таблицы, а далее через запятые список имен и определений каждого столбца таблицы:
CREATE TABLE имя_таблицы ( определение имени_столбца, определение имени_таблицы …, PRIMARY KEY= (имя_столбца) ) ENGINE= тип_движка;
В определении столбца задается тип данных, может ли столбец быть NULL, AUTO_INCREMENT. Оператор CREATE TABLE также позволяет указать столбец (или группу столбцов) в качестве первичного ключа. Прежде чем будет создавать таблицу, нужно выбрать базу данных. Это делается с помощью оператора SQL USE:
USE MySampleDB;
Создадим таблицу, состоящую из трех столбцов: customer_id, customer_name и customer_address. Столбцы customer_id и customer_name не должны быть пустыми (то есть NOT NULL). customer_id содержит целочисленное значение, которое будет автоматически увеличиваться при добавлении новых строк. Остальные столбцы будут содержать строки длиной до 20 символов. Первичный ключ определяется как customer_id.
CREATE TABLE customer ( customer_id int NOT NULL AUTO_INCREMENT, customer_name char(20) NOT NULL, customer_address char(20) NULL, PRIMARY KEY (customer_id) ) ENGINE=InnoDB;
Создание новой базы данных MySQL
Новая база данных создается с помощью оператора SQL CREATE DATABASE, за которым следует имя создаваемой базы данных. Для этой цели также используется оператор CREATE SCHEMA. Например, для создания новой базы данных под названием MySampleDB в командной строке mysql нужно ввести следующий запрос:
CREATE DATABASE MySampleDB;
Если все прошло нормально, команда сгенерирует следующий вывод:
Query OK, 1 row affected (0.00 sec)
Если указанное имя базы данных конфликтует с существующей базой данных MySQL, будет выведено сообщение об ошибке:
ERROR 1007 (HY000): Can't create database 'MySampleDB'; database exists
В этой ситуации следует выбрать другое имя базы данных или использовать опцию IF NOT EXISTS. Она создает базу данных только в том случае, если она еще не существует:
CREATE DATABASE IF NOT EXISTS MySampleDB;
Классификация баз данных
Базы данных можно разделить по 4 признакам:
1. Применяемый язык программирования. Открытые базы опираются на один из универсальных языков. В замкнутых базах используются собственный язык программирования.
2. Выполняемые функции. Информационные базы данных предназначены для хранения и доступа к информации. Операционные позволяют проводить сложные обработки информации.
3. Сфера применения. Различают универсальные БД и специализированные, предназначенные для решения конкретных задач.
4. По «мощности» все БД делятся на корпоративные и настольные. Вторые имеют низкую стоимость, рассчитаны на единичного пользователя, имеют низкие требования к техническим средствам.
Корпоративные БД предназначены для работы в распределенной среде, поддерживают одновременную работу многих пользователей, предлагают широкие возможности по проектированию и администрированию базы.
5. По ориентации на целевую аудиторию. Существуют системы, заточенные на разработчиков и конечных пользователей. В первом случае СУБД должна обладать широкими возможностями отладки проектируемой базы данных, иметь возможность создавать не привязанное к СУБД приложение, в нее должны входить средства по созданию сложных и эффективных конечных продуктов.
БД для конечных пользователей должны быть просты, интуитивно понятны, должны иметь программную защиту от непреднамеренной порчи данных со стороны пользователя.
Модель работы с базой данных
Модель базы данных «1С:Предприятия 8» имеет ряд особенностей, отличающих ее от классических моделей систем управления базами данных (например, основанных на реляционных таблицах), с которыми имеют дело разработчики в универсальных системах.
Основное отличие заключается в том, что разработчик «1С:Предприятия 8» не обращается к базе данных напрямую. Непосредственно он работает с платформой «1С:Предприятия 8». При этом он может:
- описывать структуры данных в конфигураторе,
- манипулировать данными с помощью объектов встроенного языка,
- составлять запросы к данным, используя язык запросов.
Платформа «1С:Предприятия 8» обеспечивает операции исполнения запросов, описания структур данных и манипулирования данными, транслируя их в соответствующие команды. Это могут быть команды системы управления базами данных, в случае клиент-серверного варианта работы, или команды собственного движка базы данных для файлового варианта.

Зачем она нужна
Прежде чем создать сайт, человек в идеале сначала изучает html, затем css, ну и потом JavaScript. Первое помогает справиться с текстом, второе определяет дизайн, третье дает возможность создавать скрипты. Кстати, такой подход – явная заявка на успех в интернет-сфере.

Но многие обходятся совсем без этого, выбирая свою сферу. Сейчас эти этапы не так важны. Существует множество готовых решений и любой человек, даже без особенных навыков может просто и быстро обрести свой проект. Но мы говорим об идеальном мире.
Даже если вы все это постигли и на данный момент создали портал по всем правилам, пока его нельзя назвать динамическим. Им он станет после того, как перестанет просто лежать на сервере, а начнет обновляться.
Делать это помогает система управления или движок. По правилам, вы сами должны его спрограммировать, но сейчас существует множество готовых CMS. К примеру, WordPress, о котором я неоднократно говорил. Он-то и помогает управлять контентом и сайтом. Добавлять новые статьи и менять что-то на сайте даже без знаний кода.
Давайте предположим, вы создаете не сайт, а библиотеку. Это поможет разобраться с БД (базами данных). Вполне реальную библиотеку с полками и всем прочим. Человек приходит и видит где стоят книги, это видимая часть контента, то есть сами статьи на портале.
Как посетителю найти конкретное издание? Если вы бывали в публичных библиотеках, то возможно видели картотеки. А если писали диплом самостоятельно, то наверняка знаете, что это такое и зачем они нужны.

Картотека – это архив с небольшими записочками, в которые внесена вся основная информация о изданиях: где расположена книга, кто ее автор, в каком году он ее написал. Это и есть база данных. Только сейчас мы говорим о базе для сайта.
Когда книг не много, то можно обойтись и без архива, у вас все на виду. Вы найдете необходимый материал, но когда у вас огромный портал вы или ваш читатель потратит уйму времени, пока не отыщет нужное среди книг и полок.
Существуют движки, которые себе в преимущество ставят то, что они обходятся без Mysql. Но что это значит? По факту, где-то должен располагаться текстовый документ, в котором все равно находится информация о новых публикациях.
Вернемся к аналогии. Представьте, вы приходите в библиотеку, просите Бунина, а вам предлагают поискать его в трехметровом списке. Сначала букву нужную найди и не пропустить, затем произведение, потом нужный год выпуска. Приходится пробегать глазами от начала и до конца. Такое отношение мало кому понравится.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:
Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:
Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:
В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:
Что может храниться в MySQL
В MySQL может храниться что угодно, если вы можете настроить связи между данными. Вы можете хранить в такой базе заметки, фото, музыку, списки дел, задачи на год и все лекции по теории вероятности. Весь вопрос в том, чтобы вы понимали, как вы будете это использовать дальше.
Например, все наши статьи в «Коде» хранятся в MySQL-базе, с которой мы работаем через Вордпресс. Там же есть информация и об авторах, и о картинках для статей, о дате публикации и о многом другом. Чтобы вы прочитали эту статью, сайт обратился к базе данных, взял оттуда статью, правильно её обработал и показал вам.
Другие используют MySQL для работы с клиентской базой — в бизнесе, поликлиниках или системах учёта товаров.
Самой базе всё равно, что в ней хранится и как вы этим пользуетесь. База данных — это просто способ связать данные вместе, а потом найти в них то, что нужно.
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели. Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц. Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц). Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога. Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов. Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel). Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация. В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы. Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно. Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение. А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой. Что это за связи? Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации. В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными. Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов. В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот! Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Это интересно: Трудовая книжка
Типы движков баз данных MySQL
Каждый из примеров создания таблицы в этой статье до этого момента включал в себя определение ENGINE= . MySQL поставляется с несколькими различными движками баз данных, каждый из которых имеет свои преимущества. Используя директиву ENGINE =, можно выбрать, какой движок использовать для каждой таблицы. В настоящее время доступны следующие движки баз данных MySQL:
- InnoDB — был представлен вMySQL версии 4.0 и классифицирован как безопасная среда для транзакций.Ее механизм гарантирует, что все транзакции будут завершены на 100%. При этом частично завершенные транзакции (например, в результате отказа сервера или сбоя питания) не будут записаны. Недостатком InnoDB является отсутствие поддержки полнотекстового поиска.
- MyISAM — высокопроизводительный движок с поддержкой полнотекстового поиска. Эта производительность и функциональность обеспечивается за счет отсутствия безопасности транзакций.
- MEMORY— с точки зрения функционала эквивалентен MyISAM, за исключением того, что все данные хранятся в оперативной памяти, а не на жестком диске. Это обеспечивает высокую скорость обработки. Временный характер данных, сохраняемых в оперативной памяти, делает движок MEMORY более подходящим для временного хранения таблиц.
Движки различных типов могут сочетаться в одной базе данных. Например, некоторые таблицы могут использовать движок InnoDB, а другие — MyISAM. Если во время создания таблицы движок не указывается, то по умолчанию MySQL будет использовать MyISAM.
Чтобы указать тип движка, который будет использоваться для таблицы, о поместите соответствующее определение ENGINE= после определения столбцов таблицы:
CREATE TABLE tmp_orders
{
tmp_number int NOT_NULL,
tmp_quantity int NOT_NULL,
tmp_desc char(20) NOT_NULL,
PRIMARY KEY (tmp_number)
) ENGINE=MEMORY;
Пожалуйста, опубликуйте ваши комментарии по текущей теме статьи. За комментарии, отклики, лайки, дизлайки, подписки низкий вам поклон!
Данные
Вокруг нас всегда много разных данных, например:
- телефонные номера;
- дела на день;
- записи на бумажках, стикерах и в блокнотах;
- опубликованные мысли разных людей;
- фотографии в смартфоне;
- и всё остальное, что можно прочитать, увидеть или услышать.
Если это компьютерная игра, то данными будут типы и местоположения врагов, их уровень здоровья, уровень здоровья героя, тип героя, его положение, характеристики карты.
Если это приложение для работы с клиентом, то там будут храниться имя клиента, его заказы, номер телефона, уровень в программе лояльности.
Если это служба слежения за гражданами — фотография, имя, посещённые станции метро и улицы, место работы.
Как узнать имя сервера, имя пользователя и пароль для подключения к базе данных MySQL?
Для подключения к базе данных MySQL и для входа в phpMyAdmin необходимо указывать логин и пароль пользователя базы данных.
Логин и пароль
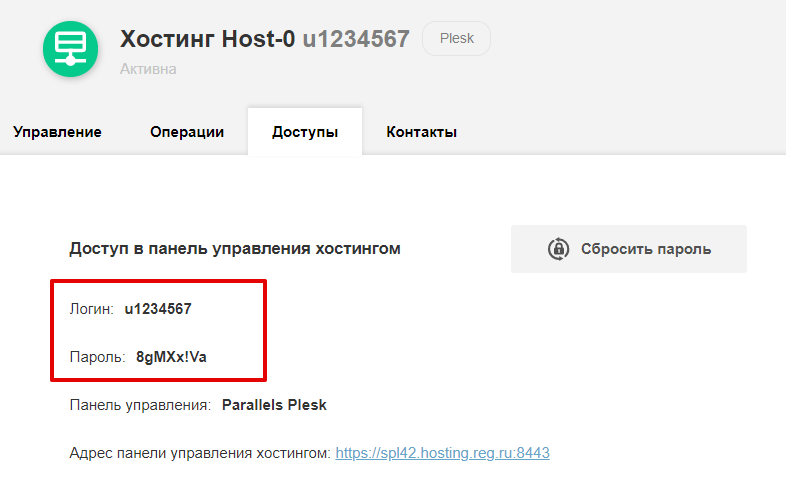
После заказа услуги хостинга в панели управления уже присутствует база данных «u1234567_default» (u1234567 — ваш логин хостинга). Вы можете воспользоваться этой базой данных. Реквизиты доступа к ней приведены в информационном письме и в Личном кабинете в карточке услуги.
Как узнать логин и пароль услуги хостинга?
Или вы можете создать новую базу данных. В этом случае имя базы, имя пользователя и пароль вы зададите самостоятельно.
Если у вас уже есть созданный сайт на CMS, узнать пароль базы данных можно в конфигурационном файле сайта: Где CMS хранит настройки подключения к базе данных.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:

Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Типы баз данных
Есть много разных типов баз данных. Лучшая база данных для конкретной организации зависит от того, как организация намеревается использовать данные.
- Реляционные базы данных. Реляционные базы данных стали доминирующими в 1980-х годах. Элементы в реляционной базе данных организованы как набор таблиц со столбцами и строками. Технология реляционных баз данных обеспечивает наиболее эффективный и гибкий способ доступа к структурированной информации.
- Объектно-ориентированные базы данных. Информация в объектно-ориентированной базе данных представлена в виде объектов, как в объектно-ориентированном программировании.
- Распределенные базы данных. Распределенная база данных состоит из двух или более файлов, расположенных на разных сайтах. База данных может храниться на нескольких компьютерах, находиться в одном физическом месте или разбросана по разным сетям.
- Хранилища данных. Централизованное хранилище данных, хранилище данных — это тип базы данных, специально разработанный для быстрого запроса и анализа.
- Базы данных NoSQL. NoSQL, или нереляционная база данных, позволяет хранить и обрабатывать неструктурированные и полуструктурированные данные (в отличие от реляционной базы данных, которая определяет, как должны быть составлены все данные, вставленные в базу данных). Базы данных NoSQL становились популярными по мере того, как веб-приложения становились все более распространенными и сложными.
- Графовые базы данных. База данных графов хранит данные в терминах сущностей и отношений между сущностями.
- Базы данных OLTP. База данных OLTP — это быстрая аналитическая база данных, предназначенная для большого количества транзакций, выполняемых несколькими пользователями.
Это лишь некоторые из нескольких десятков типов баз данных, используемых сегодня. Другие, менее распространенные базы данных предназначены для очень конкретных научных, финансовых или других функций. Помимо различных типов баз данных, изменения в подходах к разработке технологий и значительные достижения, такие как облачные технологии и автоматизация, продвигают базы данных в совершенно новых направлениях. Некоторые из последних баз данных включают:
- Базы данных с открытым исходным кодом (OpenSource). Система баз данных с открытым исходным кодом — это система с открытым исходным кодом; такие базы данных могут быть базами данных SQL или NoSQL.
- Облачные базы данных (Cloud Database). Облачная база данных — это набор структурированных или неструктурированных данных, который хранится на частной, общедоступной или гибридной платформе облачных вычислений. Существует два типа моделей облачных баз данных: традиционные и база данных как услуга (DBaaS). В случае DBaaS административные задачи и обслуживание выполняются поставщиком услуг.
- Многомодельная база данных. Мультимодельные базы данных объединяют различные типы моделей баз данных в единую интегрированную серверную часть. Это означает, что они могут поддерживать различные типы данных.
- База данных Документов / JSON. Базы данных документов, разработанные для хранения, извлечения и управления документально-ориентированной информацией, представляют собой современный способ хранения данных в формате JSON, а не в строках и столбцах.
- Автономные базы данных. Новейший и самый революционный тип базы данных, автономные базы данных (также известные как автономные базы данных) являются облачными и используют машинное обучение для автоматизации настройки базы данных, обеспечения безопасности, резервного копирования, обновления и других рутинных задач управления, традиционно выполняемых администраторами баз данных.
Создание базы данных на T-SQL (CREATE DATABASE)
Процесс создания базы данных на языке T-SQL, наверное, еще проще, так как для того чтобы создать БД с настройками по умолчанию (как мы это сделали чуть выше), необходимо написать всего три слова в редакторе SQL запросов – инструкцию CREATE DATABASE и название БД.
Сначала открываем редактор SQL запросов, для этого щелкаем на кнопку «Создать запрос» на панели инструментов.
Затем вводим следующую инструкцию, и запускаем ее на выполнение, кнопка «Выполнить».
CREATE DATABASE TestDB;
Где CREATE – это команда языка T-SQL для создания объектов на SQL сервере, командой DATABASE мы указываем, что хотим создать базу данных, а TestDB — это имя новой базы данных.
Конечно же, на данном этапе многие не знают ни Microsoft SQL Server, ни языка T-SQL, многие, наверное, как раз и создают базу данных для того, чтобы начать знакомиться с этой СУБД и начать изучать язык SQL. Поэтому чтобы Вам легче было это делать, советую почитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов, которую написал я, и в которой я подробно, и в то же время простым языком, рассказываю о языке SQL.
С помощью инструкции CREATE DATABASE можно задать абсолютно все параметры, которые отображались у нас в графическом интерфейсе SSMS. Например, если бы мы заменили вышеуказанную инструкцию следующей, то у нас база данных создалась бы в каталоге DataBases на диске D.
--Создание БД TestDB
CREATE DATABASE TestDB
ON PRIMARY --Первичный файл
(
NAME = N'TestDB', --Логическое имя файла БД
FILENAME = N'D:\DataBases\TestDB.mdf' --Имя и местоположение файла БД
)
LOG ON --Явно указываем файлы журналов
(
NAME = N'TestDB_log', --Логическое имя файла журнала
FILENAME = N'D:\DataBases\TestDB_log.ldf' --Имя и местоположение файла журнала
)
GO