Собираю семантическое ядро для сайта в key collector 4
Содержание:
- Key Collector
- Главное меню программы
- Другие функции Кей Коллектора полезные для директолога:
- Работа с частотностью запросов
- Создание структуры
- Парсинг
- Сбор частотностей
- Редактирование ячеек
- Процесс парсинга в Кей Коллекторе
- Сбор семантики
- Почему лучше не собирать все маски в единой группе?
- Панель фиксированных настроек групп
- Drag & Drop (перетягивание) групп и фраз
- Настройка Кей Коллектора
- Настройки в зависимости от размера семантики
Key Collector
Key Collector – одна из программ занимающихся парсингом ключевых слов и статистики из различных сервисов включая такие, как Яндекс Wordstat, Google AdWords, Begun, и другие.
Интерфейс Key Collector
Key Collector – программа хоть и платная 1 800 за одну копию (без учета скидок), зато она не имеет платной ежемесячной подписки, а это явное преимущество над другими конкурентами.
Также хочется заметить, что она довольно быстро обновляется и реагирует на обновления сервисов.
Интерфейс программы довольно простой, а на официальном сайте есть отличное руководство по всем тонкостям работы с ним.
Перед созданием нового проекта нам потребуется настроить программу, для этого перейдем в настройки.
Настройки Key Collector
Из всего многообразия параметров изменять лучше лишь те, в которых вы уже разобрались, так как при неправильном их задании обычно все сводится к бану прокси серверов и/или аккаунтов Яндекса, которые используются для парсинга.
Главное меню программы
Для того, чтобы попасть в меню нам нужно в верхнем правом углу выбрать “Файл”.
Добро пожаловать в Key Collector!
В появившемся меню вы можете создать новый файл или открыть уже ранее существующий проект, импортировать данные из другого проекта или файла в формате CSV.
Загрузка проекта
Меню быстрого доступа
Используя меню быстрого доступа вы можете добавить наиболее часто используемые кнопки.
Меню быстрого доступа
Для добавления новых элементов нужно правой кнопкой мышки нажать на интересующий значок. После чего в появившемся окне выбрать пункт “Добавить в панель быстрого доступа”
Добавить в палень быстрого доступа
Теперь данный элемент будет добавлен в меню. Если вы захотите удалить кнопку из меню быстрого доступа, тогда проделайте аналогичные действия: нажмите правой кнопкой мышки на иконку и дальше в меню выберите “Удалить с панели быстрого доступа”.
Удалить с панели быстрого доступа
Основная рабочая область
Основную рабочую область используют для отображения пользовательских групп и экрана приветствия после запуска программы. В ней вы можете ознакомиться со свежими новостям относительно программы, увидеть статистику хода выполнения работы и т.д.
Область новостей, журнала событий и статистика
Область новостей, журнала событий и статистика
Данная вкладка предназначена для:
-
Отображения журнала событий.
-
Получения последних новостей программы.
-
Просмотра статистики по текущему выполнению задач.
-
Просмотра дополнительных данных статистики: отображение списка релевантных страниц, графиков истории позиций, сезонности, поисковой выдачи и тд.
Под просмотром дополнительной статистики имеется в виду просмотр тех данных, которые не могут быть показаны в стандартных таблицах и выводятся для каждой фразы в отдельности. К дополнительной статистике принадлежит:
-
Просмотр количества акноров с помощью сервиса Solomono. Используем кнопку “Количество анкоров Solomono”.
-
Просмотр с помощью графика или в виде таблицы истории позиций. Для этого нажимаем “Позиция Yandex” и “Позиция Google”.
-
Просмотр состава поисковой выдачи по какому-либо запросу: адреса страниц, заголовки, сниппеты. Для этого используем «Кол-во вхождений в заголовок «, «Кол-во вхождений в заголовок » и «Кол-во вхождений в заголовок «.
-
Просмотр релевантных страниц — колонки «Рел. страница » и «Рел. страница «.
-
Просмотр частотности слов по месяцам для Google Adwors — колонка «Частотность (регионы) »
-
Просмотр частотности для Yandex Wordstats по неделям и месяцам. Для этого переходим в раздел «Сезонность «.
Для того, чтобы увидеть данную статистику надо выбрать нужную фразу и перейти во вкладку “Дополнительная статистика”. В этом меню будет доступна интересующая подвкладка с дополнительной статистикой.
Отображение вкладок можно настроить на свое усмотрение. Для этого надо зажать левую кнопку мышки на заголовок с вкладкой и перетащить в нужную сторону.
Отображение вкладок
Панель состояния
Панель состояния нужна для показа информации о количестве отмеченных строк и информацию об использовании автоматической капчи.
Панель состояния
Выше выделена кнопка принудительного обновления содержимого активной таблицы.
Другие функции Кей Коллектора полезные для директолога:
Удаление неявных дублей.
Если перейти во вкладку «Данные», то там будет полезная функция «Анализ неявных дублей», с помощью данной функции вы можете очистить собранное семантическое ядро не только от дублей, но и то неявных дублей. Например: как убрать комнату и как комнату убрать, будут считаться дублями. Программа покажет какие есть дубли, в каких группах, там же есть кнопка «Умная отметка», она автоматом выделяет один из дублей и вы его (или их удаляете), т.е. самостоятельно выделять и удалять дубли не надо, это делается в два клика.
Фильтры.
Каждый столбец в программе имеет самые различные фильтра. Например в столбце «Фразы» по фильтрам можно отыскать нужные ключевые слова, можно найти ключевые слова, которые состоят из определенного числа слов, это удобно при группировки ключей при обходе статуса «мало показов», когда в одну группу помещаются ключи с малой частотностью, но схожие по смыслу и написанию; в столбце «Базовая чистота», можно отфильтровать частотность по любому направлению (все ключи больше или равны 10, или меньше 5 и т.д.).
Быстрое составление списка минус слов.
Для того, чтобы максимально комфортно собрать полный список минус слов, достаточно выделить все ключевые слова, кликнуть правой кнопкой мыши на них и выбрать «Отправить выделенные фразы в окно стоп-слов». После этого откроется список со всеми выделенными ключами, где отмечая нужные слова далее их помещаем в список минус-слов.
Режим мульти-группы.
Для того, чтобы выгрузить полученное семантическое ядро в единый эксель файл, или применить на все группы (папки) ключей минус слов и т.д. и т.п. необходимо сначала выделить все папки, и нажать на мульти-группы, и только тогда все папки как-бы объединяться в одну. Например: у вас много папок, и вы хотите выгрузить полное семантическое ядро в один единый файл в формате эксель. Если просто выделить все папки, то в эксель отправиться лишь одна папка, а для выбора и работы со всеми папками, как раз и нужен режим мульти-группа:
Сбор частотности ключевых слов.
С помощью Кей Коллектора можно не только парсить ключевые слова, но и собирать статистику с нужных ключевых слов. Это пригодиться тогда, когда вы делаете искусственную семантику и нужно ключи не спарсить, а просто узнать их частотность.
Для этого выбираем значок «Д», как указано на картинке, выбираем нужное гео именно в открывшейся вкладке и жмем «Получить данные»:
Работа с частотностью запросов
После фильтрации по минус-словам можно запустить парсинг по частотности.
Сейчас мы видим только колонку с общей частотностью. Чтобы получить точную частотность по каждому ключевому слову, нужно в Вордстате ввести его в операторе кавычки — «ключевое слово».
В Коллекторе это делается следующим образом:
При необходимости можно собрать частотность с оператором «!слово».
Затем нужно отсортировать список по частотности » » и удалить слова с частотностью менее 10 (иногда 20-30).
Второй способ собрать частотность (более медленный):
Если вы точно знаете, что частотность ниже определённого значения вас не интересует, можно задать порог в настройках программы. В этом случае фразы с частотностью ниже порога вообще не будут попадать в список. Но так можно упустить перспективные фразы, поэтому я эту настройку не использую и вам не советую. Впрочем, действуйте по своему усмотрению.
В итоге получается более-менее пригодное для последующей работы семантическое ядро:
Обратите внимание, что это семантическое ядро — лишь пример, созданный только для демонстрации работы программы. Оно не годится под реальный проект, так как слабо проработано
Правая колонка Yandex.Wordstat
Иногда есть смысл парсить правую колонку Вордстата (запросы, похожие на «ваш запрос»). Для этого нужно кликнуть на соответствующую кнопку:
Создание структуры
Результаты группировки могут быть перенесены в проект через создание структуры.
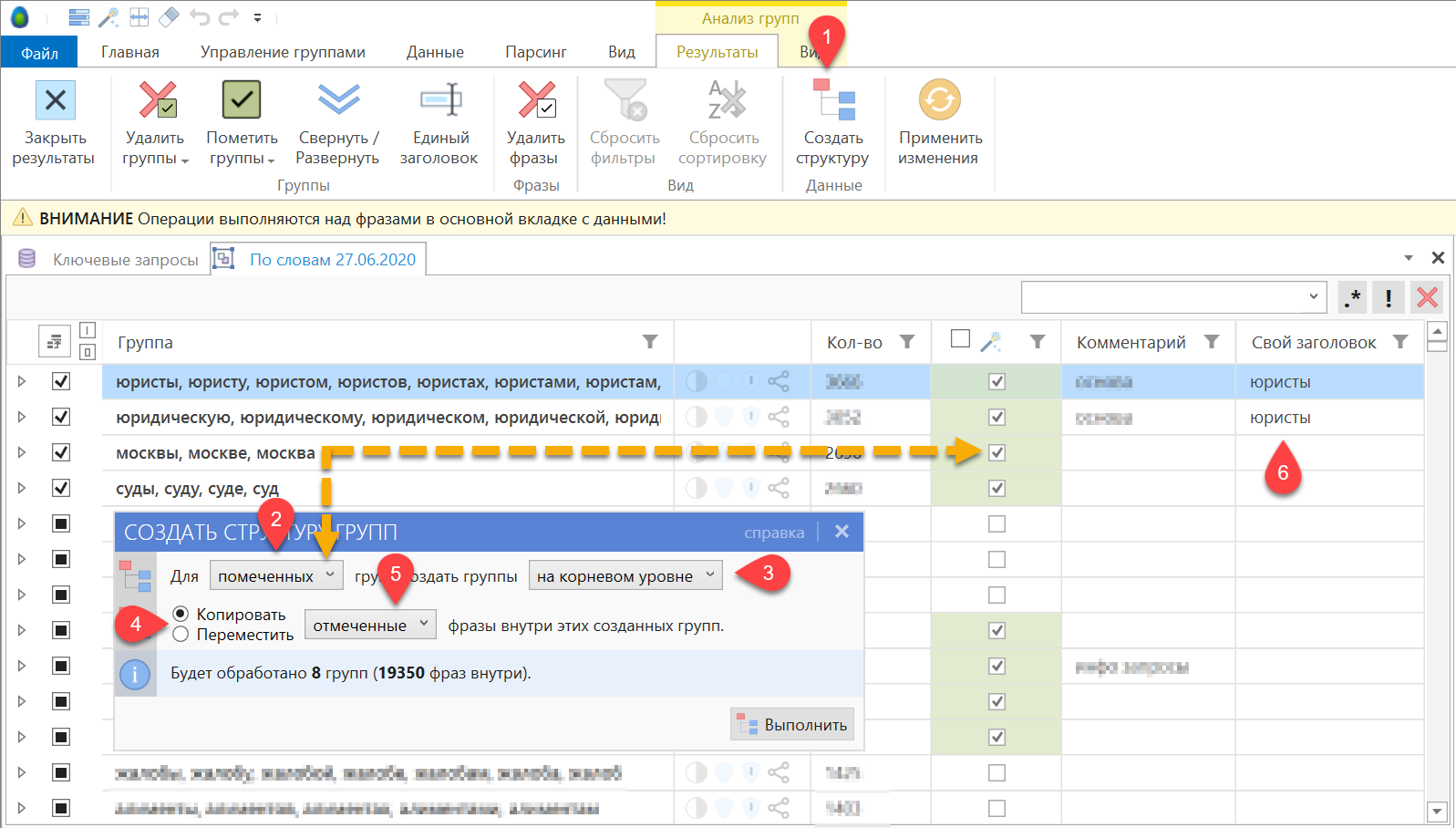
Шаг 1. Нажмите кнопку «Создать структуру» на панели инструментов. Откроется окно параметров выполнения операции.
Шаг 2. Структура может быть создана для помеченных или выделенных групп. Как правило, удобней работать с помеченными группами. находится справа от названия группы, помеченные группы подсвечиваются зеленым цветом (см. скриншот).
Не перепутайте колонку пометки групп и колонку группового статуса отметки фраз внутри группы!
Шаг 3. Выбранные на шаге 2 группы могут быть созданы на корневом уровне проекта или внутри активной группы. Выберите подходящий режим.
Шаг 4. Выберите тип операции: копирование или перенос. При переносе одна и та же фраза может быть перенесена только единожды, т.е. она не будет продублирована во все целевые группы.
Шаг 5. Выберите источник фраз: только отмеченные фразы или все фразы сформированной группы.
Шаг 6. Для достижения эффекта этот шаг нужно выполнять в самом начале перед вызовом инструмента создания структуры. По умолчанию группы создаются в проекте с автоматически сформированными заголовками, однако вы можете переопределить заголовок группы на свой более подходящий. Если несколько групп будут иметь одинаковый заголовок, то их фразы попадут в общую группу с определенным самостоятельно заголовком (дублирования групп не произойдет).
Парсинг
Далее переходим к следующему шагу — жмём «Начать сбор»:
Обратите внимание: если перед добавлением слов в проект вы отключали удаление знака «+», то перед парсингом нужно вернуть его обратно. Если, конечно, вы не хотите, чтобы слова попадали в «вордстатовском» виде, например, «купить шкаф +в москве +на таганке».
И снова о важности распределения масок на группы: пока программа готовит группы «велик» и «велек», мы уже работаем с группой «велосипед»
Профит!
И снова о важности распределения масок на группы: пока программа готовит группы «велик» и «велек», мы уже работаем с группой «велосипед». Профит!
После минусовки рекомендуем «спарсить» ядро ещё несколько раз, так как у каждой собранной ключевой фразы могут быть вложенные фразы, которые не «спарсились» на первом круге. Собранное «отминусованное» ядро в таком случае будет новым списком масок.
Повторно следует «парсить» не все слова, а только высоко- и среднечастотные запросы, так как в низкочастотных вложенных запросов почти не будет.
Чтобы понять, как много вложенных запросов у конкретного слова, можно снять его частотность в широком и в точном соответствии, а затем поделить широкое на точное. Чем больше соотношение, тем больше в ключевике вложенных фраз. Это такой себе «коэффициент замусоренности». Также вложенные запросы можно почистить через прогнозатор «Яндекс.Директа». Кому как удобнее.
А после завершения парсинга не забудьте прогнать полученные фразы через инструмент KC «Анализ неявных дублей». Он поможет найти в списке дубли в стиле «купить велосипед москва» и «купить велосипеды в москве» — и удалить их по заданным условиям.
В следующей части статьи мы расскажем, как отминусовать ненужные слова, сгруппировать нужные, перенести данные в Excel и подготовить объявления для «Яндекс.Директа» или Google AdWords.
Авторы статьи:Анастасия Якунина, production-менеджер в Adventum,Артур Семикин, performance-менеджер в Adventum.
Читайте далее: Как проработать семантическое ядро с помощью Key Collector. Часть 2
Сбор частотностей
После получения данных из Вордстата или других источников нужно собрать частотности, чтобы оценить спрос. На его основе будем делать группировку и составлять ТЗ.
Для этого есть 2 основных варианта.
- Можно собирать частотности с помощью кнопки «Сбор частотности из сервиса Yandex Wordstat». Это медленный вариант, он подходит для сбора частотностей фраз состоящих из 8 слов и более. В других случаях используйте следующий вариант.
- Лучше всего собирать частотность с помощью Yandex Direct. Программа будет обрабатывать слова не по одному, а целой пачкой зараз.
При сборе частотностей Директ можно указать, какие снимать и за какой период.
- Рекомендуется снимать частотности за последние 30 дней, если это не сезонные запросы. При съеме за другой период могут получиться не совсем адекватные цифры – видимо, Яндекс не хранит точные данные за более длительные периоды или выдает их в округленном виде.
- Съем фраз разных частотностей можно разбить на 2 или 3 этапа. Например, сначала снять базовую частотность (если добавлены запросы из других источников), отфильтровать по частотности и удалить запросы ниже определенного порога. Далее снять частотность в кавычках, снова отфильтровать запросы с неподходящей частотой и удалить их. И только потом снять самую точную частотность. Таким образом, процесс съема будет дешевле и быстрее.
Редактирование ячеек
Вы можете изменять значения ячеек в таблице. При этом редактировать можно как сами фразы, так и данные в колонках статистики (если они не заблокированы для редактирования).
Перед редактированием фраз убедитесь, что это разрешено в «Настройках — Интерфейс — Таблица данных — Управление таблицей».
Для редактирования фразы нажмите клавишу F2 или совершите двойной клик мышкой по фразе. Ячейка перейдет в режим редактирования.
В силу ограничения уникальности фраз в пределах одной группы допускается ввод только уникальных фраз (в случае нахождения полного дубликата операция редактирования будет отменена).
Для редактирования ячеек в остальных колонках можно поступить аналогичным образом. Однако в дополнение к этому также становится доступной контекстная вкладка«Таблица данных», где вы можете найти дополнительные инструменты для редактирования значений.
Вы можете изменить значения нескольких ячеек в одно действие. Для этого выделите ячейки и нажмите кнопку «Редактировать». В открывшемся диалоговом окне задайте желаемое значение и нажмите кнопку «OK».
Процесс парсинга в Кей Коллекторе
Сам процесс достаточно прост и не является чем-то сложным и выполняется в автоматическом режиме.
Первоначально нужно сразу же выставить нужное гео для парсинга, это делается в самом низу программы:
После этого нужно создать папки, куда будут помещаться спарсенные ключевые слова, папки создаются в левой колонке программы. Конечно можно парсить все в одну папку и потом делать группировку ключей, но логичнее и удобнее заранее поделить маски ключей по смыслу и парсить маски по папкам. Например: есть две маски ключей, которые хотим спарсить — вызов такси и заказать такси, для удобства дальнейшей работы с ключами, парсим маски не в общую папку, а в соответствующие две папки, чтобы ключи уже были отсортированы.
Кроме этого, если масок не много, то можно каждую папку назвать маской и тогда программа сделает парсинг по названию папки, что является очень удобным функционалом.
Для этого заранее создаем нужные папки и нажимаем на парсинг с вордстата. По умолчанию стоит галочка «Добавить в текущую группу», но нужно поставить галочку «Распределить по группам» и нажать на красную стрелочку, как показано на картинке. Здесь можно в каждую папку поместить нужные маски (т.е. не каждую маску парсить отдельно, а чтобы в одной папке были распарсено сразу несколько масок ключей); можно убрать не нужные папки и стоит заметить, что названия папок тоже будут распарсены (если этого вам не нужно просто убираем не нужное ключевое слово). Далее нажимаем на «Начать сбор» и происходит парсинг, после которого идет следующая работа — сбор минус слов, чистка ключей и их группировка:
Сбор семантики
Вот мы и перешли к самому вкусному. Собирать ключи можно из левой и правой колонок Вордстата. Как вы наверняка знаете, в левой показываются запросы с вхождением ключевого слова. В правой же – похожие запросы.
В этом материале мы рассмотрим именно сбор из левой колонки. Итак, нажимаем на красную иконку, после чего у нас открывается такое окно.
Здесь мы можем ввести все ключевые слова, которые нам нужны. Их можно разбить на вкладки и группы. Ключи можно вводить вручную, а можно просто выгрузить из файла.
После нажатия кнопки “Начать сбор” программа начнет свою работу. В зависимости от настроек и количества ключей этот процесс может занять определенное время. Иногда и по несколько часов. В конечном итоге вы получите список всех ключевых слов и фраз из левой колонки Вордстата.
Далее мы можем снять более точную частотность, потому как та, что будет доступна сразу после сбора, – ложная. Не стоит ей доверять и уж тем более делать какие-то выводы.
При сборе из правой колонки порядок действий тот же самый. Только ключей получится больше, в силу того, что в таблицу попадут все “похожие”.
Частотность
После сбора самой семантики, вы можете собрать частотность. Причем базовая частотность не даст нам особо полезной информации, поэтому нас интересует частотности с вхождением конкретных слов (“ “) и с точным вхождением (“!”)
Для сбора всех видов частотностей мы можем использовать одну кнопку.
Съем более точных частотностей позволит вам получить наиболее правильные статистические данные о количестве запросов в Яндексе. Базовая вариация не отражает истинную суть, и чаще всего при составлении семантического ядра она игнорируется.
Именно сбор частотности в конечном итоге позволяет вам кластеризовать семантическое ядро по запросам: ВЧ, СЧ и НЧ. Исходя из этих данных, сеошники могут разделять ключи по группам, создавая для каждой отдельной статьи свою небольшую базу из тайтла и нескольких ключевых слов. Далее эта информация передается копирайтерам для написания статей. Сейчас такой способ является наиболее популярным при работе с информационными сайтами.
Сезонность
Сезонные запросы – это ключи, которые актуальны в какое-то время года или в какое-то конкретное время. Если вы собираете семантику для магазина с пляжными товарами, то вам нужно брать в расчет наибольший спрос, а именно в летнее время.
Сбор сезонности позволит вам определить, какие запросы в какое время пользуются наибольшей популярностью. Чтобы собрать эту информацию с помощью Кей Коллектора, найдите в меню иконок кнопку “Сбор ключевых слов и статистики”.
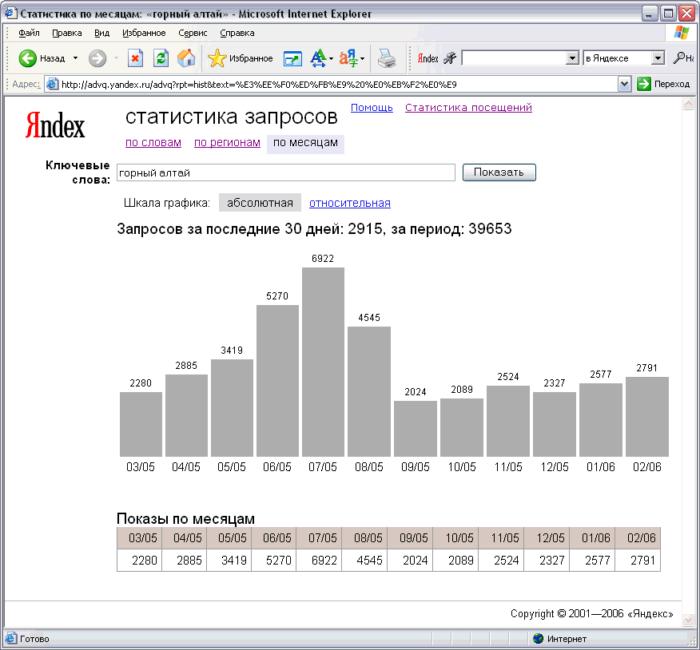
После завершения процесса на примере графика вы сможете увидеть популярность того или иного запроса в какой-то конкретный месяц.
Вы можете получить данные по неделям, а не по месяцам, как это представлено на скриншоте. Для настройки используйте все ту же кнопку “Сбор ключевых слов и статистики”, она раскрывается, там вы и найдете соответствующий пункт.
При необходимости вы можете посмотреть более подробную информацию. Для этого просто кликните на нужной ячейке.
Почему лучше не собирать все маски в единой группе?
Во-первых, при большом количестве масок Key Collector работает медленно (но в разы быстрее, чем человек). Когда у вас «спарсится» первая подгруппа, вы уже сможете с ней работать — минусовать, группировать, анализировать. Параллельно будут собираться и остальные подгруппы. Этот подход здорово экономит время, когда нужно оперативно «спарсить» маски.
Во-вторых, если ядро новое и незнакомое, вы не знаете, как поведёт себя та или иная маска. Некоторые из них (на вид безобидные ) могут оказаться чертовски мусорными. Например, при сборе РК по видеонаблюдению в маске «камера школа» мы нашли уйму порно и куда меньше запросов о видеонаблюдении. Если решите собирать всё в одной группе, а в список попадёт такая маска, у вас в один лист «спарсится» 10 000 слов, 5000 которых будут мусорными.
В результате вам придётся несколько часов вычищать неподходящие фразы. Разумнее парсить в разные группы — тогда маска «камера школа» будет стоять особняком.
Другая крайность: масок очень много (больше 200–300). Раскидывать их по отдельным группам долго, да и нагрузка на программу неоправданно высокая. В таком случае создаём отдельную группу не под одну, а под несколько масок, желательно близких по смыслу. Обычно это столбцы или строки из нашей матрицы масок. Для этого приёма необходимо выбрать способ группировки (например, по столбцам):
Затем копируем заголовки групп и вставляем их в инструмент сбора Key Collector, жмём «Распределить все фразы по одноимённым группам» — и получаем список выбранных групп:
Удаляем из них первые слова (это просто названия столбцов) и вставляем сами группы:
Важный момент. Если используете в списке масок операторы или минус-слова, перед добавлением этих слов в Key Collector проверьте в настройках, не включено ли автоматическое удаление символов:
В противном случае фраза «Шкаф +в Москве — холодильный» отправится на парсинг как «Шкаф в Москве холодильный».
Панель фиксированных настроек групп
Некоторые модули поддерживают фиксированные настройки для выбранных групп. Панель настроек можно скрыть или восстановить.
Фиксированные настройки обладают большим приоритетом над регулярными настройками.
Настройки могут наследоваться, если для родительской группы включен режим распространения настроек вниз.
Например, вы можете определить 2 корневых группы «Москва» и «Санкт-Петербург» и назначить группам фиксированные настройки региональности.
Включите режим распространения настроек вниз, чтобы подгруппы указанных групп наследовали фиксированные настройки. Теперь все вложенные в эти группы подгруппы будут наследовать заданные настройки региональности.
Далее можно добавить несколько групп в каждую из родительских групп, добавить внутрь фразы.
При сборе статистики модули будут учитывать приоритетно фиксированные настройки групп, а лишь затем заданные в окне запуска сбора статистики.
Drag & Drop (перетягивание) групп и фраз
Если вам удобно работать с операцией Drag & Drop (перетягивать элементы мышкой), вы можете выделить интересующие вас группы фраз или фразы внутри групп и перетянуть их в область заголовка группы.
]]]][[[[/wp-content/uploads/2021/01/drag-drop-groups-compressed.mp4
При перетягивании групп можно выбрать вид операции: скопировать/перенести только фразы из выделенных групп в целевую группу либо создать подгруппы внутри целевой группы и наполнить их фразами, сохраняя структуру.

При перетягивании фраз открывается диалог инструмента «Копировать/перенести фразы» для реальных фраз в проекте, которые вы видите на вкладке «Ключевые слова».
Перед вызовом инструмента всплывает окно с предложением скрыть перетянутые фразы из таблицы временных результатов группировки. Вы можете воспользоваться предложением и скрыть перетянутые фразы, чтобы они не мешали и чтобы визуально зафиксировать «обработку» фраз вручную.
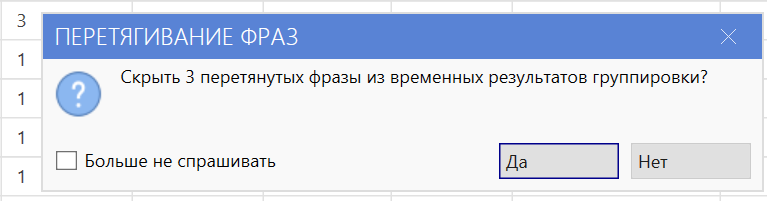
При согласии фразы скрываются еще до выполнения фактической операции копирования/переноса.
Настройка Кей Коллектора
После того, как вы оплатили лицензию с помощью Вебмани, вам придет подробная и простая инструкция по установке Key Collector. Не буду тут дублировать данную информацию.
Лучше приступим непосредственно к запуску и настройке программы Key Collector.
Окно программы состоит из верхней, нижней, боковой панели, а также основного поля, где отображаются собранные ключевые слова.
Верхняя панель инструментов:

Нижняя панель состояния:

Бокова панель управления группами:

Основное поле сбора:
Для начала работы нам необходимо зайти в настройки в верхней панели слева.

Первым делом, в настройках необходимо указать зарегистрированные вами аккаунты в тех сервисах, которые вы собираетесь использовать.
Например, для Яндекс Директа (основной источник сбора информации):
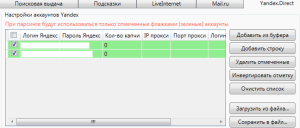
Указываете логин и через двоеточие пароль: к примеру, pro.wp:1234. Можно указать два или больше аккаунтов, тогда в случае блокировки одного, будет задействован второй. Не рекомендуется использовать больше 3-х.
Аккаунт может быть вычеркнуть системой, а соответственно информация не будет обрабатываться по причине слишком маленьких промежутков между запросами.
Для Яндекс Директа у меня проставлены такие значение:
Пока проблем не наблюдалось. Соответственно, если сократить временные диапазоны между обращениями к системе, результаты будут обрабатываться быстрее, но это может привести к блокировке аккаунта.
Обратите также внимание на остальные закладки настроек, кроме «Парсинга» это «Сеть», «Интерфейс», «Антикапча», «KEI». В разделе «Сеть» вы можете задать значения прокси-серверов, если вы их используете для работы с программой
В разделе «Сеть» вы можете задать значения прокси-серверов, если вы их используете для работы с программой.
В «Интерфейс» в Key Collector можно настроить отображения столбцов и заголовков таблиц, особенности экспорта файлов в Excel.
На вкладке «KEI» вы можете задать любые значения, которые вам нужно просчитать посредством вами заданных формул Kei в Кей Коллекторе. Например, просчет конкурентности запроса: сумма главных страниц с данным ключевым словом и заголовков других страниц с этим словом в Яндексе или Гугле.
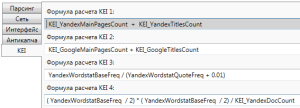
Когда вы подкорректировали все настройки, можно приступать к работе с Кей Коллектор.
Настройки в зависимости от размера семантики
Настройки для небольшой семантики (от 0 до 1 000 ключей).
Дальше все настройки зависят от того какая скорость сбора семантика вам требуется, если семантика небольшая, то и времени на ее парсинг уйдет немного.
Тогда можно обойтись добавлением одного (не основного!) аккаунта Яндекса для парсинга и можно приступать.
-
Выбираем пункт меню Yandex.Direct
-
Жмем кнопку «Добавить строку»
-
Вводим логин и пароль от аккаунта Яндекса
-
Нажимаем на кнопку пуск для проверки работоспособности аккаунта
И Жмем сохранить изменения
Настройки Yandex Direct в Key Collector
Настройки для средних и больших семантик (более 1 000 ключей)Сначала теория
Для настройки парсинга средних или больших семантических ядер потребуется расширить количество потоков и соответственно количество аккаунтов Яндекс Директ для ускорения сбора ключевых фраз.
Принцип сбора заключается в том, что Key Collector используя добавленные в него аккаунты Яндекса, обращается к yandex wordstat и постранично копирует все выданные запросы по ключевой фразе (если страница полная, то запросов в левой колонке ровно 50)
далее уходит в ожидание на 25-30 секунд, для избежания бана аккаунта и после этого еще раз обращается уже к следующей странице, либо к следующей фразе. В итоге получается 100 запросов в минуту, не считая перехода на другое ключевое слово, т.е. примерно 6 000 запросов в час.
Следовательно, если требуется собрать большие семантики на 10 000 – 20 000 слов потребуется от 2 часов и более.
А если у вас сразу несколько тематик и количество ключевых фраз более 100 000? На их сбор уйдет слишком много времени.
Для увеличения скорости требуется увеличивать количество потоков, при этом скорость увеличивается ровно во столько раз сколько будет добавлено потоков.
Для этого потребуется равное количество Яндекс аккаунтов и готовых прокси серверов. Их можно приобрести на специальных площадках. В среднем, цена за один прокси + один аккаунт Яндекса — 100 рублей в месяц.
Мы используем 10 прокси и соответственно 10 аккаунтов Яндекса.
Это примерно 1 000 запросов в минуту.
Перейдем к настройке
Заходим в настройки Yandex.Wordstat и отключаем галочку напротив «Использовать основной Ip-адрес»
Здесь же выставляем количество потоков равное количеству доступных нам прокси и аккаунтов Яндекса.
Если вы приобрели 10 прокси и 8 Яндекс аккаунтов, то выставляйте 8 потоков, чтобы не повышать шансы блокировки Яндекс аккаунтов.
Настройка Yandex Wordstat в Key Collector
Для дальнейшей настройки переходим во вкладку Яндекс директ.
Жмем по кнопке добавить списком и вносим сюда все аккаунты по шаблону логин:пароль.
Настройки Яндекс Директ в Key Collector часть 1
После внесения списка аккаунтов требуется их проверить на работоспосоность:
-
Пролистываем настройки чуть ниже.
-
Нажимаем на зеленую кнопку запустить — все рабочие аккаунты отобразятся как зеленые, нерабочие красные.
-
Выставляем количество потоков
-
Снимаем галочку с использования основного ip-адреса.
Настройки Яндекс Директ в Key Collector
Переходим во вкладку «Сеть»
Вкладка Сеть настройки Key Collector
-
Здесь ставим галочку на пункте «Использовать прокси-серверы»
-
Далее нажимаем кнопку «Добавить из буфера»
Настройки Сети Key Collector
Копируем сюда прокси по шаблону адрес:порт@логин:пароль.
Настройка прокси кей коллектор
После добавления проверяем прокси также, как и с Яндекс директом, красные не рабочие, зеленые в полном порядке.
Нажимаем кнопку сохранить изменения.
Проверка прокси в кей коллектор
С настройками закончили. Данных настроек вполне хватит для сбора семантики и ее частотности. На свой страх и риск можно также протестировать настройки паузы между запросами для увеличения скорости сбора.