Семантическое ядро сайта
Содержание:
- Сервисы для парсинга и кластеризации семантического ядра
- Этапы работы с семантическим ядром
- Особенности ядра для Интернет-магазина
- Группировка семантического ядра для информационного сайта
- Как сделать правильное семантическое ядро сайта
- Основные правила составления семантического ядра
- Виды и типы поисковых запросов: классификация
- Что такое семантическое ядро простыми словами
Сервисы для парсинга и кластеризации семантического ядра
Для сбора и кластеризации семантики есть много платных и бесплатных инструментов. Мы уже упоминали несколько сервисов и сейчас остановимся на них подробнее.
Key Collector
Автоматизированный сервис для подбора семантического ядра. Умеет собирать ключи через «Яндекс.Вордстат», парсить поисковые подсказки, выгружать данные с Google Ads и сервисов аналитики, чистить семантику от стоп-слов, дублей и сезонных запросов, делать фильтрацию по частотности. Частотность Key Collector собирает в Yandex Direct, Google Ads, LiveInternet, Rambler Adstat и APIShop.com.
Главные достоинства Key Collector — разнообразные источники парсинга, большая глубина сбора, возможность группировки собранной базы. Из минусов SEO специалисты отмечают медленную работу, особенно при увеличенной глубине сбора, и необходимость покупки антикапч.
Интерфейс Key Collector
Программа платная, работает по лицензии. Стоимость лицензии зависит от статуса покупателя: физическому лицу бессрочная лицензия обойдется в 2 200 рублей, организации придется заплатить 2 300 рублей.
MOAB.Tools Семантика
Это онлайн-сервис, который парсит до четырех миллионов фраз в час и собирает для семантического ядра запросы из Wordstat и подсказок, в том числе запросы с длинным полным хвостом спецификаторов. При поиске нет проблем с капчей, можно выбрать регионы, найти ультранизкочастотные запросы и интегрировать результат с Key Collector. Удобно, что сервис сразу проверяет частотность.
Работа парсера MOAB.Tools
Инструмент платный, но в тарифе Free первые 5 000 фраз можно собрать бесплатно. Тариф Mini стоит 1 299 рублей и рассчитан на ядро до 50 000 фраз. Для крупных проектов разработан тариф Pro, с которым за 6 099 рублей можно найти до 500 000 фраз.
«Словоеб»
Сервис позиционируется как бесплатная альтернатива Key Collector. У программы похожий интерфейс и принцип работы, но возможности парсинга ограничены результатами «Вордстат», Rambler.Adstat и поисковыми подсказками «Яндекс» и Google. Частотность фраз программа тоже проверяет только по «Вордстат».
Работа программы «Словоеб»
По сути, «Словоеб» выполняет базовую работу по сбору семантики в «Яндекс.Вордстат», но в автоматическом режиме. За 10-15 минут он собирает несколько тысяч запросов, что в разы быстрей ручного сбора.
Yandex Wordstat Assistant
Браузерное расширение для упрощения работы с «Вордстат». Бесплатный сервис, который копирует и сохраняет ключевые слова из «Яндекс.Вордстат» в таблицы Excel. Умеет сортировать запросы по частотности, алфавиту или порядку добавления. Автоматически ищет дубли и позволяет добавлять ключи вручную.
Составление семантического ядра с помощью браузерного расширения
Расширение бесплатное, устанавливается для Google Chrome, Opera, Mozilla Firefox и «Яндекс.Браузер».
Serpstat
Мультиинструментальный сервис для работы с семантическим ядром, кластеризации и SEO анализа.
Интерфейс сервиса Serpstat
При сборе семантики учитывает частотность и конкурентность запросов по шкале от 1 до 100, показывает сложность продвижения. Может работать с региональной выдачей и сравнивать результаты с сайтами конкурентов. Особенно удобно, что Serpstat группирует ключевые слова по страницам и рекламным кампаниям с учетом однородности.
У сервиса есть бесплатная версия с ограниченным функционалом. Подписки оформляются на месяц или год. Самая недорогая стоит 55$ в месяц.
Rush Analytics
Сервис автоматизации парсинга и кластеризации семантического ядра. Собирает запросы и показывает их частотность на основе данных «Яндекс.Вордстат» и Google Ads, ищет подсказки в «Яндекс», Google и YouTube. Умеет кластеризовать ключевые слова методом Soft и Hard, автоматически создает структуру сайта.
Интерфейс Rush Analytics
Бесплатная версия с ограниченным функционалом доступна семь дней. Минимальный тариф стоит 500 рублей в месяц.
Готовое ядро выглядит как электронная таблица, где по каждой ключевой фразе указана базовая (по всем вариантам использования ключевого слова) и точная (без словоформ) частотность, а для каждого кластера — продвигаемая страница.
Данные в таком формате можно сразу использовать для SEO и контекстной рекламы:
- Разрабатывать или оптимизировать структуру сайта.
- Отбирать перспективные запросы с низкой стоимостью клика и запускать контекстную рекламу с дешевым целевым трафиком.
- Составлять контент-план на несколько лет или месяцев.
- Делать технические задания для контентного наполнения или оптимизации текущего контента.
Этапы работы с семантическим ядром
Теперь когда мы знаем, что такое семядро и для чего оно нужно, а также знакомы с основными классификациями запросов, давайте вкратце разберём основные этапы работы с ядром.
Сбор семантики
Подробные способы сбора семантики будут даны в части «», здесь же мы остановимся на основных моментах.
На этом этапе вы должны найти и выписать общие запросы (их ещё называют маркерными), которые характеризуют деятельность вашего бизнеса: как общие направления, так и отдельные услуги и товары.
Например, вы продаёте мотоциклы определённой компании. Вашими маркерными запросами могут являться «мотоциклы», «мотоциклы + бренд» , «как выбрать мотоцикл», «запчасти для мотоцикла + бренд», «как ухаживать за мотоциклом», «классические/спортивные/круизёры и другие типы мотоциклов», «ремонт мотоциклов + бренд» и т.д. То есть в зависимости от оказываемых услуг или имеющихся товаров выбираются соответствующие маркеры.
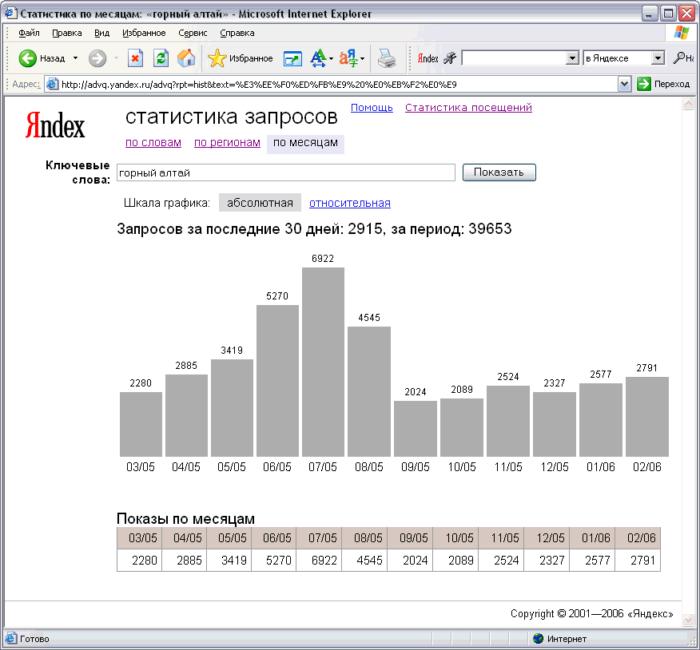
После определения маркерных запросов проверяйте собранные ключевые слова в основных сервисах статистики запросов: Яндекс.Вордстат или Google Ads Планировщик ключевых слов. В них вы найдёте как частотность запросов, так и варианты других ключевых слов по вашей тематике. Собирайте всё, что как-то связано с вашим бизнесом.
Принципиальная разница между обозначенными сервисами заключается в следующем:
- Статистика в каждом актуальна только для родной поисковой системы. То есть если запрос «юридические услуги» смотреть в Вордстате, то показов будет более 100 000 именно в Яндекс. В Планировщике ключевых слов значения соответственно будут отличаться в Google.
- Плюс Вордстата в том, что он показывает точное значение показов запроса. Если у вас новый аккаунт в Google Ads, вместо точных значений запроса вы получите диапазоны типа 10–100, 100–1000 и т.д.
- Плюс Планировщика ключевых слов в том, что он даёт множество вариантов ключей сразу, чтобы учесть все варианты запросов для вашего сайта в продвижении и рекламе.
Если денег на платные инструменты нет, советуем использовать сразу 2 сервиса при сборе семантики. Но всё же рекомендуем купить Key Collector. Его основная задача — это автоматический сбор (парсинг) ключевых слов не только с Вордстата и Планировщика, но и с других сервисов и баз. Это не реклама данного инструмента, но уточним, что, кроме парсинга, сервис удобен для чистки и кластеризации ядра. Для многих SEO-специалистов Key Collector как швейцарский нож.
Интерфейс KeyCollector
Очистка
Когда все варианты запросов пользователей собраны в одной таблице, наступает время чистки от лишнего.
Лишними являются запросы, которые:
- слишком общие,
- не относятся к деятельности вашего сайта,
- не подходят по географии,
- включают в себя неактуальные цифры и даты,
- имеют брендовые составляющие конкурентов,
- состоят из 8 слов и более,
- затруднительно использовать на одной странице.
В качестве примера приведём подобранные ключи для одной из компаний, которая занимается продажей электрических каминов в Санкт-Петербурге:
Кластеризация и выбор страниц
Кластеризация — это группировка запросов по общности их смысловых значений в иерархическом порядке. То есть в одном кластере, или группе, должны быть запросы, описывающие одну сущность в глазах пользователя и поисковой системы. Делается это либо вручную, либо с помощью специальных сервисов.
Вернёмся к нашим каминам и возьмём следующие запросы:
- камин электрический с эффектом пламени;
- камины электрические с эффектом живого пламени;
- камины электрические фото;
- купить камин электрический;
- камин электрический купить в спб;
- угловой камин электрический;
- угловые камины электрические купить.
Первые два запроса можно объединить в один кластер и продвигать на одной странице. 3-й предполагает галерею или каталог, 4 и 5-й маркерные и достаточно общие, поэтому для них подойдёт главная страница или каталог. 6 и 7-й описывают категорию электрокаминов и под них стоит создать отдельную страницу на сайте.
Это пример ручной кластеризации, но мы указали, что запросы должны описывать одну сущность и в глазах пользователя, и поисковика. И вот тут начинаются проблемы, потому что часто можно столкнуться с тем, что схожие на первый взгляд запросы формируют разную поисковую выдачу. Чтобы избежать таких ошибок, используются специальные сервисы кластеризации, которые сравнивают выдачу и группируют кластеры.
Мониторинг
Важно не просто собрать ключевые слова и использовать их в создании контента для сайта, но и отслеживать рост позиций и трафика по этим запросам. О том, как это делать и какие сервисы можно использовать, читайте в нашей статье про проверку позиций
Особенности ядра для Интернет-магазина
Примечание: Уникальные запросы — это фразы, которые вбивали в строку поиска всего 1 раз. Статистики по ним нету, так как в предыдущие и последующие месяцы их частотность равна нулю. Обычно, это длинные и конкретные запросы.
Что делать в таком случае? Многие рекомендуют собирать огромное семантическое ядро с десятками тысяч низкочастотников. Сложность заключается в том, что работать с такой семантикой крайне сложно. Мы предлагаем немного иной подход.
В ядре необходимо отразить дерево всех основных ключевых запросов с частотностью до 5-10 показов. А вместо очень низкочастотных запросов просто выписать слова, которые необходимо упомянуть в тексте и тэгах. Огромное количество низкочастотников формируется из достаточно небольшого количества слов.
Таким образом, Вы сможете упомянуть в описании товара большинство слов, которые формируют низкочастотные запросы. При этом, ядро будет наглядным и структурированным. Выглядеть это может таким образом:
Группировка семантического ядра для информационного сайта
При группировке семантического ядра я руководствуюсь здравой логикой, сравнивая её с выдачей.
Для информационных сайтов я не вижу смысла прибегать к кластеризации и четко следовать её требованиям. Поисковая система постоянно обучается и совершенствуется. Сегодня она показывает, что запросы “черный хлеб” и “ржаной хлеб” это разные продукты, а завтра покажет правильно, что это одно и тоже.
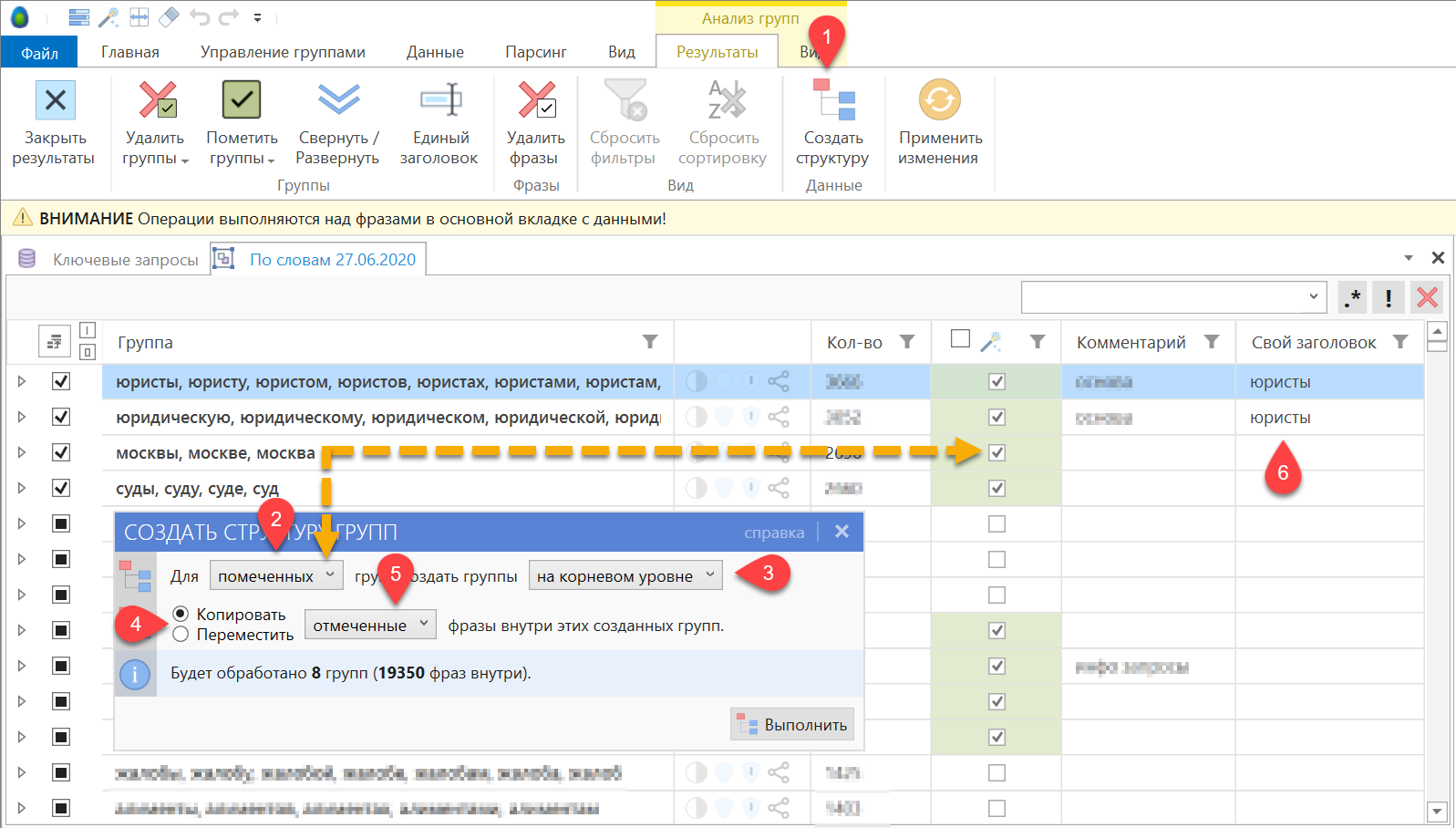
Итак, в KeyCollector у нас есть чистенький список запросов и мы собрали по нему данные из поисковой выдачи. Чтобы облегчить работу, группируем ядро средствами KeyCollector.
Заходим в анализ групп, ставим по поисковой выдаче Яндекс, сила 2. Обновляем группировку и экспортируем результаты в Excel.Таким способом у нас получилась группировка исходя из данных поисковой системы Яндекс. Но, как я писал уже выше, что надо следовать преимущественно логике и свои предположения проверять в поисковой системе, поэтому в некоторых группах могут быть запросы, которые вообще никак к ней не относятся. Их надо все пересмотреть и доработать.
Чтобы легче было дорабатывать, лучше всего оставить несколько столбцов только с нужными данными. Обычно я оставляю: базовую частотность, точную, KEI по полноте охвата, конкуренцию.
Покажу группировку на примере, чтобы было наглядно. Например, мы создаем сайт посвященный рецептам блинов. Мы увидели, что есть множество запросов связанные с молоком. Решаем, что будем делать отдельную рубрику “Рецепты блинов на молоке”. На примере этой рубрики и рассмотрим группировку.
Смотрим первую группу:Видим, что в группу “простого рецепта” попал общий запрос “тесто для блинов на молоке рецепт” – этим запросом человек не обязательно хочет найти простой рецепт. По логике, лучше всего этот запрос перенести в общую группу, которая будет вести на категорию со всеми рецептами блинов на молоке.
Но так же следует и глянуть выдачу в яндексе, что там вообще находится. Смотрим и видим, что действительно в выдаче по этому запросу есть пара страниц, которые ведут не на один рецепт, а на множество. Так же видим, что в выдаче большинство страниц ведут на один рецепт, при этом на рецепты тонких блинов. Но это же тупо, человек не обязательно хочет тонкие блины. Если бы он хотел тонкие блины, то он ввёл это в запрос. А у нас общий запрос, мы должны показать ему общую страницу, а он уже на ней должен определиться какие блины он хочет на молоке – с простым рецептом или тонкие блины или в дырочку или еще какие-то. В общем я мыслю так.
Переносим лишний запрос в другую группу, а точнее создаем выше новую “Рубрика рецепты блинов на молоке” отмечаем её другим цветом, потому что это рубрика, а в неё уже будут входить рецепты в нашем случае “простой рецепт блинов на молоке”. Тем самым у нас создается структура внутри семантики.
Все данные по группе суммируем. Бюджет можно выводить средним числом, так как это взаимодополняемые запросы, вы все их продвигаете на одной странице, а не по отдельности.
KEI1 (полнота охвата) выводим по уже известной нам формуле:
/*100
Получается вот такая красота:Данные по «рубрике рецепты блинов на молоке» еще не суммируем, потому что скорее всего туда добавятся еще запросы. Но и не исключено, что в “простой рецепт блинов на молоке” тоже еще добавятся запросы.
К тому же тут еще и затесался запрос с “тонкие блины”. Его тоже отдельно, он будет страницей к рубрике “рецепт блинов на молоке и воде”
И таким вот способом перерабатываем все ядро, в итоге получается вот так:Красным шрифтом помечены дополнительные фразы, которые имеют приставки фото, видео. Для нас это не совсем актуальные фразы. Эти фразы конкурируют с сервисами поисковых систем и трафику по ним очень мало. Но эти фразы подходят по нашему смыслу, поэтому мы их добавляем в группу.
Каждая группа помечена своим цветом. Цвет является структурой сайта, то есть уровнем вложенности страницы.
Например, если бы у нас был запрос “простой рецепт блинов на скисшем молоке”. То он бы уже шёл, как подгруппа к группе “блины на скисшем молоке” и естественно был бы выделен другим цветом. Выглядело бы это вот так:Думаю, идея с цветом понятна. Вот так создается семантика и удобная, понятная структура сайта, где все логично и имеет свой уровень вложенности.
Новые или измененные рубрики добавляем в нашу структуру в xmind.
В общем, чтобы нормально разгруппировать ядро необходимо мыслить логически, вставать на место посетителя, отвечать на вопрос – что он хочет увидеть, введя этот запрос? А также смотреть выдачу по этому запросу и принимать решение, как поступить наилучшим образом.
Как сделать правильное семантическое ядро сайта
Существует несколько этапов, которые помогут тщательно проработать тематику.
Первый этап. Сбор информации
На этом шаге нам нужно максимально включиться в тему и узнать все, что касается клиента и его направления.
Для этого иногда используется “мозговой штурм”, когда нужно сесть и записать все, что будем искать и прорабатывать.
Что учитываем:
Часть информации вам придется искать самостоятельно, чтобы лучше разобраться в тематике. Частично вам поможет продвигаемый сайт клиента и то, что он может рассказать о том, что хочет продать. Учитывайте бриф, конкурентов, структуру уже имеющегося веб-ресурса (если заказчик пришел не с нуля), вся информация о продукции в каталогах и прайсах, подсказки Вордстата и Гугл Адвордс.
Можно проанализировать контекстную рекламу и определить, что используют в рекламных объявлениях конкуренты — как вручную, так и с помощью сервисов spywords, advodka.
Второй этап. Подбор ключевых слов
После этого составляем таблицу всех запросов и перемножаем их. Для этого применяется специальный генератор.
Следует собрать все данные из Яндекс.Вордстат и Google Adwords. Для этого нужно поочередно вводить каждое подобранное словосочетание из первичного списка в сервисы, дополнительно вы получите еще уточненные и ассоциативные варианты.
Для автоматического подбора лучше использовать специальные программы, например, Кей Коллектор.
Совет: в планировщике Гугл Адвордс можно удобно осуществлять поиск не только по словам, но и по урлам конкурентов.
После всех манипуляций требуется отфильтровать неподходящие по специфике или тематике. Для этого используют программы, которые убирают все запросы с минус-словами (отминусовываем СЯ).
Перечислим конкретнее, что точно следует вычеркнуть:
- упоминания конкурирующих брендов;
- опечатки и ошибки;
- другие регионы;
- иная тематика.
Третий этап. Кластеризация и группировка ключевых слов
После всех перечисленных шагов вы имеется большой список ключей, которым можете воспользоваться для продвижения. Однако сейчас это сплошное полотно, которое нужно разделить по блокам в зависимости от тематики и страниц/услуг клиента.
Например, в контекстной рекламе важна дажа словоформа. Ведь в одно рекламное объявление может входить запрос “водоочистка”, а в другое — “очистка воды”. Это происходит из-за того, что ключ должен быть в заголовке при выдаче и лучше соответствовать поиску. В итоге, получается множество групп объявлений, которое в конечном счете виду на одинаковые урлы. В сети Гугл и РК Яндекса, наоборот, все ключи одного товара или услуги объединяют, чтобы упростить структуру.
А как собрать семантическое ядро для сайта для сео? При SEO-продвижении придется сложнее, потому что требуется под каждый запрос определять, какому url он будет соответствовать, есть ли он у клиента
Очень важно это сделать, иначе урлы не станут ранжироваться или совсем не будут соответствовать СЯ. Обязательно нужно проверять, чтобы это выполнялось, а если релевантных страниц нет — создавать самостоятельно
Самый дешевый способ кластеризовать — в ручную. Однако это выполнимо, если проект небольшой, а слов мало.
Для крупных сайтов требуется автоматизировать весь процесс. Например, платный сервис Rush Analytics позволяет автоматически группировать. Там придется указать точность (обычно 5), которая показывается, сколько общих урлов должно быть в результатах поиска по запросам, чтобы они не были в одной группе.
Четвертый этап. Сопоставление ключей и структуры, доработка
После тщательной кластеризации мы получили готовые группы. Однако может оказаться, что у нас несколько кластеров соответствуют одному урлу. Тогда придется создавать новые и менять, дорабатывать структуру.
При группировке нам нужно все запросы разделить на всех страница сайта максимально. Но при этом не допустить появление дублирующих урлов по смыслу.
Основные правила составления семантического ядра
-
Чтобы собрать СЯ, потребуется собрать наборы ключевых слов. В этом отношении нужно оценивать свои силы относительно продвижения по высоко- и среднечастотным запросам. Если требуется получить максимум посетителей при наличии бюджета, нужно использовать высоко- и среднечастотные запросы. Если наоборот, то средне- и низкочастотные запросы.
-
Даже при наличии высокого бюджета нет смысла продвигать сайт только по высокочастотным запросам. Часто такие запросы имеют слишком общий характер и неконкретизированную смысловую нагрузку, например «слушать музыку», «новости», «спорт».
При выборе поисковых запросов анализируют множество показателей, которые соответствуют поисковому словосочетанию:
Великолепная пятёрка: удобные плагины WordPress для вашего блога (перевод).
Виды и типы поисковых запросов: классификация
Очень важно разобраться в классификации поисковых запросов. И это не пустая теоретическая вода — это то, что поможет понять, какие именно нам нужны запросы и почему, чтобы не хвататься за нецелевые и неэффективные
-
Традиционная классификация поисковых запросов:
- Навигационные — поиск конкретного сайта или сервиса, например, «риа новости».
- Информационные — поиск информации как таковой, например, «как готовить борщ».
- Транзакционные — поиск чего-либо с целью осуществить какое-либо действие «купить утюг».
- Общие — запросы, которые могут быть как информационными, так и транзакционными, например, «машины».
-
Виды поисковых запросов:
- Конкуренция: высосоконкурентные (ВК), среднеконкурентные (СК) и низкоконкурентные (НК) — насколько сложно продвинуться по этому запросу.
- Частотность: высокочастотные (ВЧ), среднечастотные (СК) и, не поверите, низкочастотные (НЧ) — сколько трафика можно получить с этого запроса.
- Коммерческие и информационные — является ли целью посетителя сделать ваш кошелек более тугим или нет.
- Геозависимые и геонезависимые — относится ли запрос к какому-то конкретному региону или нет.
- Сезонные и внесезонные — имеются ли у частотности запроса циклические колебания, повторяющиеся из года в год.
Что же нам нужно? Если отложить в сторону показатель конкурентности, с которым и так всё понятно, то легче всего продвигать геозависимые информационные запросы (если, конечно, вы продвигаете в регионе, к которому они относятся), а сложнее всего — геонезависимые коммерческие. Геопривязку можно определить через программу Key Collector, сервис SeoPult или же ручками, схема к чем я в одном из следующих материалов.
Определение геопривязки через SeoPult
Примеры геозапросов:
«Куда сходить» — геозависимый информационный запрос.
«Натяжные потолки калькулятор онлайн» — геонезависимый коммерческий запрос.
Высокочастотные запросы нам пока особо не требуются — они по умолчанию высококонкурентны, но если вы нашли высокочастотный низкоконкурентный ключ, то напишите мне — с меня чай с печеньками 🙂
Но мы поступимся высокочастотными запросами не потому, что сложно продвинуть, а потому что те средства и силы, которые мы затратим на продвижение ВЧ будут несоизмеримо больше, чем в случае с сотней НЧ или нескольких десятков СЧ, а трафика будет больше (эффект длинного хвоста). Неэффективно, одним словом. График распределения частот между типами запросов:
Нет-нет, это не значит, что в СЯ не должно быть ВЧ, просто не нужно биться лбом об стенку и бросать на них все силы. По мере подтягивания к топу НЧ и СЧ и прокачке тематических характеристик хоста в целом, ВЧ тоже будут ползти к заветной десятке.
В общем и целом, в своё семантическое ядро мы в первую очередь подбираем геозависимые НЧ и СЧ c как можно меньшей конкурентностью. И лишь затем, на будущее, приправляем его геонезависимыми и высокочастотными.
Для информационного сайта, соответственно, нужные информационные геозависимые запросы, а для коммерческого — коммерческие геозависимые и частично информационные, которые, по логике, могут привести не только зевак, но и клиентов — «как выбрать то-то», «характеристики того-то» и т.д.
Подробнее о типах поисковых запросов: https://pingoblog.ru/21-tipy-poiskovyh-zaprosov.html
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.