Работа с файлами в python
Содержание:
- Чтение документов MS Word
- Стилевое оформление
- Основа
- Чтение из файла Python
- Форматы файлов в Python 3
- Открытие файла Python
- Чтение и запись файлов
- Закрытие
- 🔸 Как прочитать файл
- Генератор случайных файлов
- Шаг 6 — Проверка кода
- Модули для чтения и записи
- 2: Открытие файла
- Извлечение текста с помощью PyMuPDF
- The read() Method
- The write() Method
- Концепт пути и директории в Python
- Настройка строк и столбцов
- Чтение данных из файла с помощью Python
- Использование модуля pickle
Чтение документов MS Word
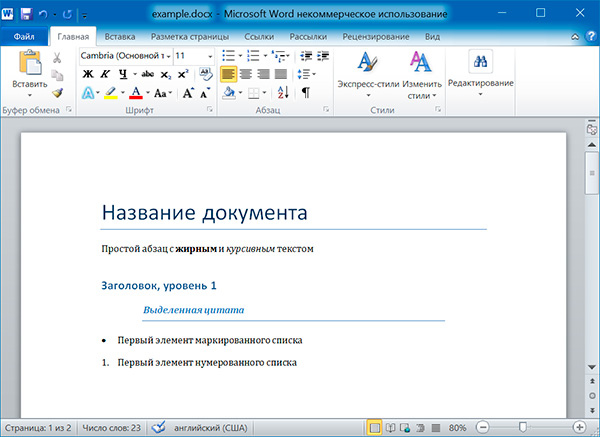
Файлы с расширением .docx обладают развитой внутренней структурой. В модуле python-docx эта структура представлена тремя различными типами данных. На самом верхнем уровне объект представляет собой весь документ. Объект содержит список объектов , которые представляют собой абзацы документа. Каждый из абзацев содержит список, состоящий из одного или нескольких объектов , представляющих собой фрагменты текста с различными стилями форматирования.

import docx
doc = docx.Document('example.docx')
# количество абзацев в документе
print(len(doc.paragraphs))
# текст первого абзаца в документе
print(doc.paragraphs.text)
# текст второго абзаца в документе
print(doc.paragraphs1.text)
# текст первого Run второго абзаца
print(doc.paragraphs1.runs.text)
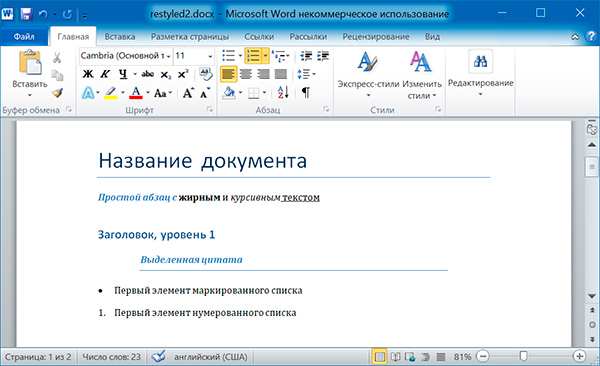
6 Название документа Простой абзац с жирным и курсивным текстом Простой абзац с
Получаем весь текст из документа:
text =
for paragraph in doc.paragraphs
text.append(paragraph.text)
print('\n'.join(text))
Название документа Простой абзац с жирным и курсивным текстом Заголовок, уровень 1 Выделенная цитата Первый элемент маркированного списка Первый элемент нумерованного списка
Стилевое оформление
В документах MS Word применяются два типа стилей: стили абзацев, которые могут применяться к объектам , стили символов, которые могут применяться к объектам . Как объектам , так и объектам можно назначать стили, присваивая их атрибутам значение в виде строки. Этой строкой должно быть имя стиля. Если для стиля задано значение , то у объекта или не будет связанного с ним стиля.
Стили символов
paragraph.style = 'Quote' run.style = 'Book Title'
Атрибуты объекта Run
Отдельные фрагменты текста, представленные объектами , могут подвергаться дополнительному форматированию с помощью атрибутов. Для каждого из этих атрибутов может быть задано одно из трех значений: (атрибут активизирован), (атрибут отключен) и (применяется стиль, установленный для данного объекта ).
- — Полужирное начертание
- — Подчеркнутый текст
- — Курсивное начертание
- — Зачеркнутый текст
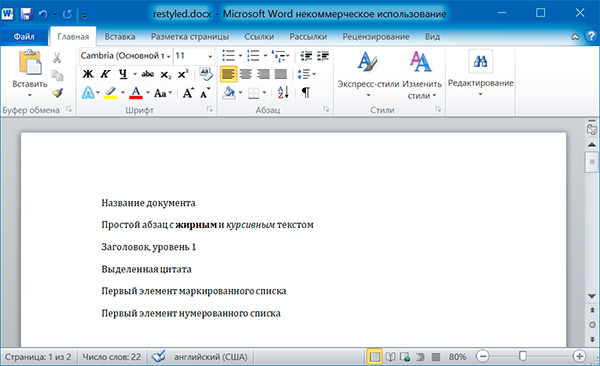
Изменим стили для всех параграфов нашего документа:
import docx
doc = docx.Document('example.docx')
# изменяем стили для всех параграфов
for paragraph in doc.paragraphs
paragraph.style = 'Normal'
doc.save('restyled.docx')
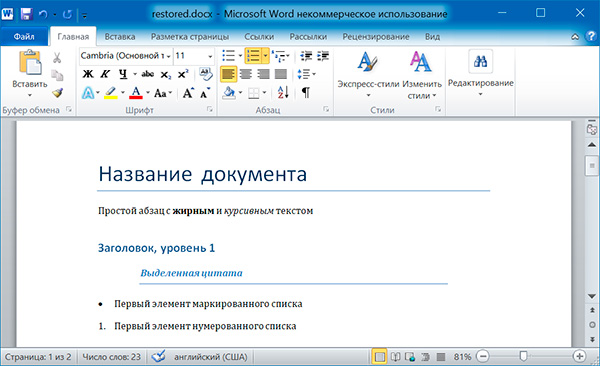
А теперь восстановим все как было:
import docx
os.chdir('C:\\example')
doc1 = docx.Document('example.docx')
doc2 = docx.Document('restyled.docx')
# получаем из первого документа стили всех абзацев
styles =
for paragraph in doc1.paragraphs
styles.append(paragraph.style)
# применяем стили ко всем абзацам второго документа
for i in range(len(doc2.paragraphs))
doc2.paragraphsi.style = stylesi
doc2.save('restored.docx')
Изменим форматирвание объектов второго абзаца:
import docx
doc = docx.Document('example.docx')
# добавляем стиль символов для runs
doc.paragraphs1.runs.style = 'Intense Emphasis'
# добавляем подчеркивание для runs
doc.paragraphs1.runs4.underline = True
doc.save('restyled2.docx')
Стилевое оформление
Для настройки шрифтов, используемых в ячейках, необходимо импортировать функцию из модуля :
from openpyxl.styles import Font
Ниже приведен пример создания новой рабочей книги, в которой для шрифта, используемого в ячейке , устанавливается шрифт , красный цвет, курсивное начертание и размер 24 пункта:
import openpyxl
from openpyxl.styles import Font
# создаем новый excel-файл
wb = openpyxl.Workbook()
# добавляем новый лист
wb.create_sheet(title = 'Первый лист', index = )
# получаем лист, с которым будем работать
sheet = wb'Первый лист'
font = Font(name='Arial', size=24, italic=True, color='FF0000')
sheet'A1'.font = font
sheet'A1' = 'Здравствуй мир!'
# записываем файл
wb.save('example.xlsx')
Именованные стили применяются, когда надо применить стилевое оформление к большому количеству ячеек.
import openpyxl
from openpyxl.styles import NamedStyle, Font, Border, Side
# создаем новый excel-файл
wb = openpyxl.Workbook()
# добавляем новый лист
wb.create_sheet(title = 'Первый лист', index = )
# получаем лист, с которым будем работать
sheet = wb'Первый лист'
# создаем именованный стиль
ns = NamedStyle(name='highlight')
ns.font = Font(bold=True, size=20)
border = Side(style='thick', color='000000')
ns.border = Border(left=border, top=border, right=border, bottom=border)
# вновь созданный именованный стиль надо зарегистрировать
# для дальнейшего использования
wb.add_named_style(ns)
# теперь можно использовать именованный стиль
sheet'A1'.style = 'highlight'
# записываем файл
wb.save('example.xlsx')
Основа
Python может с относительной легкостью обрабатывать различные форматы файлов:
| Тип файла | Описание |
| Txt | Обычный текстовый файл хранит данные, которые представляют собой только символы (или строки) и не включает в себя структурированные метаданные. |
| CSV | Файл со значениями,для разделения которых используются запятые (или другие разделители). Что позволяет сохранять данные в формате таблицы. |
| HTML | HTML-файл хранит структурированные данные и используется большинством сайтов |
| JSON | JavaScript Object Notation — простой и эффективный формат, что делает его одним из часто используемых для хранения и передачи данных. |
В этой статье основное внимание будет уделено формату txt
Чтение из файла Python
Чтобы осуществить чтение из файла Python, нужно открыть его в режиме чтения. Для этого можно использовать метод read(size), чтобы прочитать из файла данные в количестве, указанном в параметре size. Если параметр size не указан, метод читает и возвращает данные до конца файла.
>>> f = open("test.txt",'r',encoding = 'utf-8')
>>> f.read(4) # чтение первых 4 символов
'This'
>>> f.read(4) # чтение следующих 4 символов
' is '
>>> f.read() # чтение остальных данных до конца файла
'my first filenThis filencontains three linesn'
>>> f.read() # дальнейшие попытки чтения возвращают пустую строку
''
Метод read() возвращает новые строки как ‘n’. Когда будет достигнут конец файла, при дальнейших попытках чтения мы получим пустые строки.
Чтобы изменить позицию курсора в текущем файле, используется метод seek(). Метод tell() возвращает текущую позицию курсора (в виде количества байтов).
>>> f.tell() # получаем текущую позицию курсора в файле 56 >>> f.seek(0) # возвращаем курсор в начальную позицию 0 >>> print(f.read()) # читаем весь файл This is my first file This file contains three lines
Мы можем прочитать файл построчно в цикле for.
>>> for line in f: ... print(line, end = '') ... This is my first file This file contains three lines
Извлекаемые из файла строки включают в себя символ новой строки ‘n’. Чтобы избежать вывода, используем пустой параметр end метода print(),.
Также можно использовать метод readline(), чтобы извлекать отдельные строки. Он читает файл до символа новой строки.
>>> f.readline() 'This is my first filen' >>> f.readline() 'This filen' >>> f.readline() 'contains three linesn' >>> f.readline() ''
Метод readlines() возвращает список оставшихся строк. Все эти методы чтения возвращают пустую строку, когда достигается конец файла.
>>> f.readlines()
Форматы файлов в Python 3
Python очень гибкий и может относительно легко обрабатывать множество различных форматов файлов. Вот основные форматы:
| Формат | Описание |
| txt | Обычный текстовый файл, который хранит данные в виде символов (или строк) и исключает структурированные метаданные. |
| CSV | Файл, который хранит данные в виде таблицы; для структурирования хранимых данных используются запятые (или другие разделители). |
| HTML | Файл Hypertext Markup Language хранит структурированные данные; такие файлы используются большинством сайтов. |
| JSON | Простой файл JavaScript Object Notation, один из наиболее часто используемых форматов для хранения и передачи данных. |
Данное руководство рассматривает только формат txt.
Открытие файла Python
Не знаете как открыть файл в питоне? В Python есть встроенная функция open(), предназначенная для открытия файла. Она возвращает объект, который используется для чтения или изменения файла.
>>> f = open("test.txt") # открыть файл в текущей папке
>>> f = open("C:/Python33/README.txt") # указание полного пути
При этом можно указать необходимый режим открытия файла: ‘r’- для чтения,’w’ — для записи,’a’ — для изменения. Мы также можем указать, хотим ли открыть файл в текстовом или в бинарном формате.
По умолчанию файл открывается для чтения в текстовом режиме. При чтении файла в этом режиме мы получаем строки.
В бинарном формате мы получим байты. Этот режим используется для чтения не текстовых файлов, таких как изображения или exe-файлы.
| Открытие файла Python- возможные режимы | |
| Режим | Описание |
| ‘r’ | Открытие файла для чтения. Режим используется по умолчанию. |
| ‘w’ | Открытие файла для записи. Режим создаёт новый файл, если он не существует, или стирает содержимое существующего. |
| ‘x’ | Открытие файла для записи. Если файл существует, операция заканчивается неудачей (исключением). |
| ‘a’ | Открытие файла для добавления данных в конец файла без очистки его содержимого. Этот режим создаёт новый файл, если он не существует. |
| ‘t’ | Открытие файла в текстовом формате. Этот режим используется по умолчанию. |
| ‘b’ | Открытие файла в бинарном формате. |
| ‘+’ | Открытие файла для обновления (чтения и записи). |
f = open("test.txt") # эквивалент 'r' или 'rt'
f = open("test.txt",'w') # запись в текстовом режиме
f = open("img.bmp",'r+b') # чтение и запись в бинарном формате
В отличие от других языков программирования, в Python символ ‘a’ не подразумевает число 97, если оно не закодировано в ASCII (или другой эквивалентной кодировке).
Кодировка по умолчанию зависит от платформы. В Windows – это ‘cp1252’, а в Linux ‘utf-8’.
Поэтому мы не должны полагаться на кодировку по умолчанию. При работе с файлами в текстовом формате рекомендуется указывать тип кодировки.
f = open("test.txt",mode = 'r',encoding = 'utf-8')
Чтение и запись файлов
Python предлагает различные методы для чтения и записи файлов, где каждая функция ведет себя по-разному. Следует отметить один важный момент – режим работы с файлами. Чтобы прочитать файл, вам нужно открыть файл в режиме чтения или записи. В то время, как для записи в файл на Python вам нужно, чтобы файл был открыт в режиме записи.
Вот некоторые функции Python, которые позволяют читать и записывать файлы:
- read() – эта функция читает весь файл и возвращает строку;
- readline() – эта функция считывает строки из этого файла и возвращает их в виде строки. Он выбирает строку n, если она вызывается n-й раз.
- readlines() – эта функция возвращает список, в котором каждый элемент представляет собой одну строку этого файла.
- readlines() – эта функция возвращает список, в котором каждый элемент представляет собой одну строку этого файла.
- write() – эта функция записывает фиксированную последовательность символов в файл.
- Writelines() – эта функция записывает список строк.
- append() – эта функция добавляет строку в файл вместо перезаписи файла.
Возьмем пример файла «abc.txt» и прочитаем отдельные строки из файла с помощью цикла for:
#open the file
text_file = open('/Users/pankaj/abc.txt','r')
#get the list of line
line_list = text_file.readlines();
#for each line from the list, print the line
for line in line_list:
print(line)
text_file.close() #don't forget to close the file
Вывод:
Теперь, когда мы знаем, как читать файл в Python, давайте продвинемся вперед и выполним здесь операцию записи с помощью функции Writelines().
#open the file
text_file = open('/Users/pankaj/file.txt','w')
#initialize an empty list
word_list= []
#iterate 4 times
for i in range (1, 5):
print("Please enter data: ")
line = input() #take input
word_list.append(line) #append to the list
text_file.writelines(word_list) #write 4 words to the file
text_file.close() #don’t forget to close the file
Вывод
Закрытие
Если для открытия текстового документа применяется метод open() то, логично, для закрытия – close(). Это надо делать всегда, если программа не будет с ним больше работать. Если этого не сделать, его след останется в оперативной памяти, и компьютер может начать работать медленнее. В случае с маленькими файлами это не критично, а что если придется открывать большой?
Если присвоить новый файл той же переменной, то закрытие старого произойдет автоматически.
Есть несколько способов осуществления закрытия.
Способ 1
Наиболее легкий способ – просто закрыть файл после того, как с ним будет произведено последнее действие.
f = open(‘example.txt’,’r’)
# процессы, выполняемые над файлом
f.close()
Пока его снова не открыть средствами программы, она уже ничего не сможет с ним сделать, если выполнить последнюю инструкцию.
Способ 2
Приведенный выше способ прост, но имеет недостаток. Если возникает какая-то ошибка, это может привести к сбою в работе программы. Чтобы обработать ошибки при открытии файла, используется комбинация try/finally. В таком случае, если что-то пойдет не так, то программа просто закроет файл, а не аварийно завершит свою работу.
Вот код, как это делается.
f = open(‘example.txt’,’r’)
try:
# работа с файлом
finally:
f.close()
Открытие файла должно осуществиться до того, как создается конструкция try/finally. Потом пишется try, и это начинается обработчик ошибок. Далее пишутся инструкции по работе с этим файлом, после чего finally записывается, и тогда файл закрывается. То есть, синтаксис обработчика стандартный, и ничем принципиально не отличается.
Способ 3
Сделать обработку ошибок значительно легче можно с помощью инструкции with. Она упаковывает в себя сразу несколько задач, в том числе и закрытие, очистку. Очень удобно, поскольку не надо писать несколько строк кода, чтобы закрыть файл в случае неудачи.
with open(‘example.txt’) as f:
# работа с файлом
🔸 Как прочитать файл
Теперь, когда вы узнаете больше о аргументах, которые Открыть () Функция берет, давайте посмотрим, как вы можете открыть файл и хранить его в переменной, чтобы использовать его в вашей программе.
Это основной синтаксис:
Мы просто назначаем значение, возвращенное в переменную. Например:
names_file = open("data/names.txt", "r")
Я знаю, что вы можете спросить: какую ценность возвращается Открыть () ?
Ну, А Файл объект Отказ
Давайте немного поговорим о них.
Файловые объекты
Согласно , а Файл объект является:
Это в основном говорит нам, что объект файла является объектом, который позволяет нам работать и взаимодействовать с существующими файлами в нашей программе Python.
Файловые объекты имеют атрибуты, такие как:
- Имя : имя файла.
- закрыто : Если файл закрыт. иначе.
- Режим : Режим, используемый для открытия файла.
Например:
f = open("data/names.txt", "a")
print(f.mode) # Output: "a"
Теперь давайте посмотрим, как вы можете получить доступ к содержите файла через файл объекта.
Методы для чтения файла
Для нас, чтобы иметь возможность работать файловые объекты, нам нужно иметь способ «взаимодействовать» с ними в нашей программе, и это именно какие методы. Давайте посмотрим некоторые из них.
Читать()
Первый метод, который вам нужно узнать о том, это , который Возвращает все содержимое файла в виде строки.
Здесь у нас есть пример:
f = open("data/names.txt")
print(f.read())
Вывод:
Nora Gino Timmy William
Вы можете использовать Функция, чтобы подтвердить, что значение, возвращенное это строка:
print(type(f.read())) # Output
Да, это строка!
В этом случае весь файл был напечатан, потому что мы не указываем максимальное количество байтов, но мы можем сделать это также.
Здесь у нас есть пример:
f = open("data/names.txt")
print(f.read(3))
Возвращенная стоимость ограничена этим количеством байтов:
Nor
️ Важно: .. Вам нужно Закрыть Файл после того, как задача была завершена для освобождения ресурсов, связанных с файлом
Для этого вам нужно позвонить в Метод, как это:
Readline () vs. readleines ()
Вы можете прочитать линию файла по строке с этими двумя методами. Они немного отличаются, поэтому давайте посмотрим их подробно.
readline () Читает одна линия файла, пока он не достигнет конца этой линии. Персонаж Craining Newline ( ) хранится в строке.
Совет: Необязательно, вы можете пройти размер, максимальное количество символов, которые вы хотите включить в результирующую строку.
Например:
f = open("data/names.txt")
print(f.readline())
f.close()
Вывод:
Nora
Это первая строка файла.
Напротив, Readleines () Возвращает Список со всеми линиями файла как отдельные элементы (строки). Это синтаксис:
Например:
f = open("data/names.txt")
print(f.readlines())
f.close()
Вывод:
Обратите внимание, что есть (Новый символ) в конце каждой строки, кроме последнего. Совет: Вы можете получить тот же список с Отказ
Совет: Вы можете получить тот же список с Отказ
Вы можете работать с этим списком в вашей программе, назначая его переменной или используя ее в цикле:
f = open("data/names.txt")
for line in f.readlines():
# Do something with each line
f.close()
Мы также можем итерации за Прямой (объект файла) в цикле:
f = open("data/names.txt", "r")
for line in f:
# Do something with each line
f.close()
Это основные методы, используемые для чтения файловых объектов. Теперь давайте посмотрим, как вы можете создавать файлы.
Генератор случайных файлов
Создадим папку , а внутри нее еще одну — . Дерево каталогов теперь должно выглядеть вот так:
ManageFiles/ | |_RandomFiles/
Чтобы поиграться с файлами, мы сгенерируем их случайным образом в директории . Создайте файл в папке . Вот что должно получиться:
ManageFiles/ | |_ create_random_files.py |_RandomFiles/
Готово? Теперь поместите в файл следующий код, и перейдем к его рассмотрению:
import os
from pathlib import Path
import random
list_of_extensions =
# перейти в папку RandomFiles
os.chdir('./RandomFiles')
for item in list_of_extensions:
# создать 20 случайных файлов для каждого расширения имени
for num in range(20):
# пусть имя файла начинается со случайного числа от 1 до 50
file_name = random.randint(1, 50)
file_to_create = str(file_name) + item
Path(file_to_create).touch()
Начиная с Python 3.4 мы получили pathlib, нашу маленькую волшебную палочку. Также мы импортируем функцию для генерации случайных чисел, но ее мы посмотрим в действии чуть ниже.
Сперва создадим
список файловых расширений для формирования названий файлов. Не стесняйтесь
добавить туда свои варианты.
Далее мы переходим в папку и запускаем цикл. В нем мы просто говорим: возьми каждый элемент и сделай с ним кое-что во внутреннем цикле 20 раз.
Теперь пришло время для импортированной функции . Используем ее для производства случайных чисел от 1 до 50. Это просто не очень творческий способ побыстрее дать названия нашим тестовым файлам: к сгенерированному числу добавим расширение файла и получим что-то вроде или . И так 20 раз для каждого расширения. В итоге образуется беспорядок, достаточный для того, чтобы его было лень сортировать вручную.
Итак, запустим
наш генератор хаоса через терминал.
python create_random_files.py
Поздравляю,
теперь у нас полная папка неразберихи. Будем распутывать.
В той же директории, где , создадим файл и поместим туда следующий код.
Шаг 6 — Проверка кода
Конечный результат должен выглядеть примерно так:
files.py
path = '/users/sammy/days.txt' days_file = open(path,'r') days = days_file.read() new_path = '/users/sammy/new_days.txt' new_days = open(new_path,'w') title = 'Days of the Weekn' new_days.write(title) print(title) new_days.write(days) print(days) days_file.close() new_days.close()
После сохранения кода откройте терминал и запустите свой Python- скрипт, например:python files.py
Результат должен выглядеть так:
Вывод Days of the Week Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Теперь проверим код полностью, открыв файл new_days.txt. Если все пройдет хорошо, когда мы откроем этот файл, его содержимое должно выглядеть следующим образом:
new_days.txt
Days of the Week Monday Tuesday Wednesday Thursday Friday Saturday Sunday
Модули для чтения и записи
Модуль CSV имеет несколько функций и классов, доступных для чтения и записи CSV, и они включают в себя:
- функция csv.reader
- функция csv.writer
- класс csv.Dictwriter
- класс csv.DictReader
csv.reader
Модуль csv.reader принимает следующие параметры:
- : обычно это объект, который поддерживает протокол итератора и обычно возвращает строку каждый раз, когда вызывается его метод .
- : необязательный параметр, используемый для определения набора параметров, специфичных для определенного диалекта CSV.
- : необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Вот пример того, как использовать модуль csv.reader.
модуль csv.writer
Этот модуль похож на модуль csv.reader и используется для записи данных в CSV. Требуется три параметра:
- : это может быть любой объект с методом .
- : необязательный параметр, используемый для определения набора параметров, специфичных для конкретного CSV.
- : необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
2: Открытие файла
Создайте сценарий files.py в текстовом редакторе и для простоты сохраните его в тот же каталог (/users/8host/).
Чтобы открыть файл в Python, нужно связать файл на диске с переменной Python. Сначала сообщите Python, где находится нужный файл. Чтобы открыть какой-либо файл, Python должен знать путь к этому файлу. Путь к файлу days.txt выглядит так: /users/8host/days.txt.
В файле files.py создайте переменную path и укажите в ней путь к файлу days.txt.
Теперь можно использовать функцию open(), чтобы открыть файл days.txt. В качестве первого аргумента функция open() требует путь к файлу, который нужно открыть. Эта функция имеет много других параметров. Одним из основных параметров является режим; это опциональная строка, которая позволяет выбрать режим открытия файла:
- ‘r’: открыть файл для чтения (опция по умолчанию).
- ‘w’: открыть файл для записи.
- ‘x’: создать новый файл и открыть его для записи.
- ‘a’: вставить в файл.
- ‘r+’: открыть файл для чтения и записи.
Попробуйте открыть файл для чтения. Для этого создайте переменную days_file и задайте в ней опцию open() и режим ‘r’, чтобы открыть файл days.txt только для чтения.
Извлечение текста с помощью PyMuPDF
Перейдём к PyMuPDF.
Отображение информации о документе, печать количества страниц и извлечение текста из документа PDF выполняется аналогично PyPDF2 (см. скрипт ниже). Импортируемый модуль имеет имя , что соответствует имени PyMuPDF в ранних версиях.
import fitz
pdf_document = "./source/Computer-Vision-Resources.pdf"
doc = fitz.open(pdf_document)
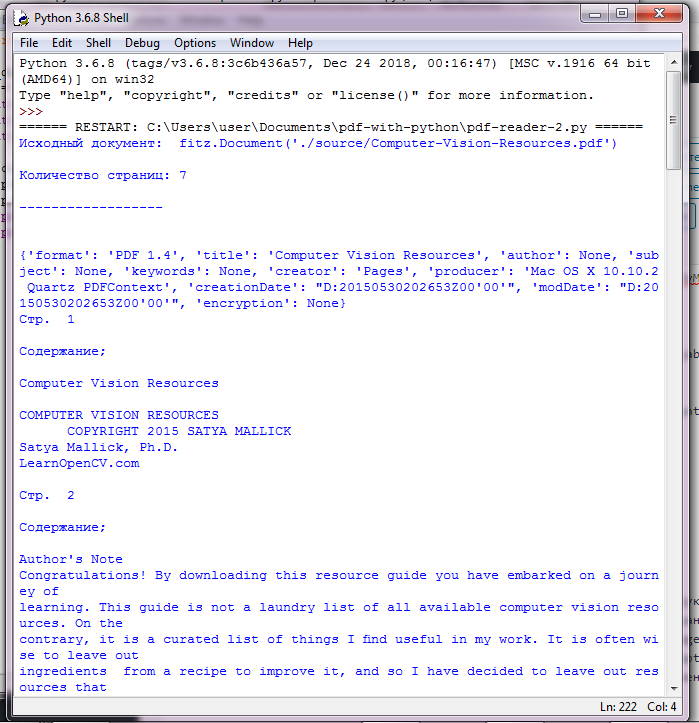
print("Исходный документ: ", doc)
print("\nКоличество страниц: %i\n\n------------------\n\n" % doc.pageCount)
print(doc.metadata)
for current_page in range(len(doc)):
page = doc.loadPage(current_page)
page_text = page.getText("text")
print("Стр. ", current_page+1, "\n\nСодержание;\n")
print(page_text)
 Извлечение текста с помощью PyMuPDF
Извлечение текста с помощью PyMuPDF
Приятной особенностью PyMuPDF является то, что он сохраняет исходную структуру документа без изменений — целые абзацы с разрывами строк сохраняются такими же, как в PDF‑документе.
The read() Method
The read() method reads a string from an open file. It is important to note that Python strings can have binary data. apart from text data.
Syntax
fileObject.read()
Here, passed parameter is the number of bytes to be read from the opened file. This method starts reading from the beginning of the file and if count is missing, then it tries to read as much as possible, maybe until the end of file.
Example
Let’s take a file foo.txt, which we created above.
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "r+")
str = fo.read(10);
print "Read String is : ", str
# Close opend file
fo.close()
This produces the following result −
Read String is : Python is
The write() Method
The write() method writes any string to an open file. It is important to note that Python strings can have binary data and not just text.
The write() method does not add a newline character (‘\n’) to the end of the string −
fileObject.write(string)
Here, passed parameter is the content to be written into the opened file.
Example
#!/usr/bin/python
# Open a file
fo = open("foo.txt", "wb")
fo.write( "Python is a great language.\nYeah its great!!\n")
# Close opend file
fo.close()
The above method would create foo.txt file and would write given content in that file and finally it would close that file. If you would open this file, it would have following content.
Python is a great language. Yeah its great!!
Концепт пути и директории в Python
Перед началом подробного рассмотрения модуля Pathlib важно разобраться в разнице между главными концептами темы — путем (path) и директорией (directory)
- Путь используется для идентификации файла. Путь предоставляет необязательную последовательность названий директорий, в конце которой значится конечное имя файла, а также его расширение;
- Расширение названия файла предоставляет некоторую информацию о формате/содержимом файла. Модуль Pathlib может работать как с абсолютными, так и с относительными путями;
- Абсолютный путь начинается с корневой директории и определяет полное дерево каталогов;
- Относительный путь, как следует из названия, является путем к файлу относительно другого файла или директории, обычно текущей;
- Директория представляет собой запись пути в файловой системе и включает название файла, время создания, размер, владельца и так далее.
Модуль Pathlib в Python занимается задачами, связанными с путями, такими как создание новых путей из названий файлов и других путей, проверка различных свойств путей, создание файлов и папок по определенным путям.
Настройка строк и столбцов
С помощью модуля OpenPyXL можно задавать высоту строк и ширину столбцов таблицы, закреплять их на месте (чтобы они всегда были видны на экране), полностью скрывать из виду, объединять ячейки.
Настройка высоты строк и ширины столбцов
Объекты имеют атрибуты и , которые управляют высотой строк и шириной столбцов.
sheet'A1' = 'Высокая строка' sheet'B2' = 'Широкий столбец' sheet.row_dimensions1.height = 70 sheet.column_dimensions'B'.width = 30

Атрибуты s и представляют собой значения, подобные словарю. Атрибут содержит объекты , а атрибут содержит объекты . Доступ к объектам в осуществляется с использованием номера строки, а доступ к объектам в — с использованием буквы столбца.
Для указания высоты строки разрешено использовать целые или вещественные числа в диапазоне от 0 до 409. Для указания ширины столбца можно использовать целые или вещественные числа в диапазоне от 0 до 255. Столбцы с нулевой шириной и строки с нулевой высотой невидимы для пользователя.
Объединение ячеек
Ячейки, занимающие прямоугольную область, могут быть объединены в одну ячейку с помощью метода рабочего листа:
sheet.merge_cells('A1:D3')
sheet'A1' = 'Объединены двенадцать ячеек'
sheet.merge_cells('C5:E5')
sheet'C5' = 'Объединены три ячейки'

Чтобы отменить слияние ячеек, надо вызвать метод :
sheet.unmerge_cells('A1:D3')
sheet.unmerge_cells('C5:E5')
Закрепление областей
Если размер таблицы настолько велик, что ее нельзя увидеть целиком, можно заблокировать несколько верхних строк или крайних слева столбцов в их позициях на экране. В этом случае пользователь всегда будет видеть заблокированные заголовки столбцов или строк, даже если он прокручивает таблицу на экране.
У объекта имеется атрибут , значением которого может служить объект или строка с координатами ячеек. Все строки и столбцы, расположенные выше и левее, будут заблокированы.
| Значение атрибута freeze_panes | Заблокированные строки и столбцы |
|---|---|
| Строка 1 | |
| Столбец A | |
| Столбцы A и B | |
| Строка 1 и столбцы A и B | |
| Закрепленные области отсутствуют |
Чтение данных из файла с помощью Python
Допустим, вы (или ваш пользователь посредством вашего приложения) поместили данные в файл, и ваш код должен их получить. Тогда перед вами стоит цель – прочитать файл. Логика чтения такая же, как логика записи:
- Открыть файл
- Прочесть данные
- Закрыть файл
Опять же, этот логический поток отражает то, что вы и так делаете постоянно, просто используя компьютер (или читая книгу, если на то пошло). Чтобы прочитать документ, вы открываете его, читаете и закрываете. С компьютерной точки зрения «открытие» файла означает загрузку его в память.
На практике текстовый файл содержит более одной строки. Например, вашему коду может потребоваться прочитать файл конфигурации, в котором сохранены данные игры или текст следующей песни вашей группы. Так же, как вы не прочитываете всю книгу прямо в момент открытия, ваш код не должен распарсить весь файл целиком при загрузке в память. Вероятно, вам потребуется перебрать содержимое файла.
f = open('example.tmp', 'r')
for line in f:
print(line)
f.close()
В первой строке данного примера мы открываем файл в режиме чтения. Файл обозначаем переменной , но, как и при открытии файлов для записи, имя переменной может быть произвольным. В имени нет ничего особенного – это просто кратчайший из возможных способов представить слово file, поэтому программисты Python часто используют его.
Во второй строке мы резервируем (еще одно произвольное имя переменной), для представления каждой строки . Это сообщает Python, что нужно выполнить итерацию по строкам нашего файла и вывести каждую из них на экран.
Чтение файла с использованием конструкции with
Как и при записи данных, существует более короткий метод чтения из файлов с использованием конструкции . Поскольку здесь не требуется вызов функции , это более удобно для быстрого взаимодействия.
with open('example.txt', 'r') as f:
for line in f:
print(line)
Использование модуля pickle
Различные методы, описанные до сих пор, хранят список таким образом, чтобы люди могли его прочитать. Если в этом нет необходимости, модуль pickle может вам пригодиться. Его метод dump() эффективно сохраняет список, как поток двоичных данных. Во-первых, в строке 7 (в приведенном ниже коде) выходной файл listfile.data открывается для двоичной записи («wb»). Во-вторых, в строке 9 список сохраняется в открытом файле с помощью метода dump():
# load additional module
import pickle
# define a list of places
placesList =
with open('listfile.data', 'wb') as filehandle:
# store the data as binary data stream
pickle.dump(placesList, filehandle)
В качестве следующего шага мы читаем список из файла следующим образом. Во-первых, файл listfile.data открывается двоичный файл для чтения («rb») в строке 4. Во-вторых, список мест загружается из файла с помощью метода load().
# load additional module
import pickle
with open('listfile.data', 'rb') as filehandle:
# read the data as binary data stream
placesList = pickle.load(filehandle)
Два примера здесь демонстрируют использование строк. Хотя, pickle работает со всеми видами объектов Python, такими как строки, числа, самоопределяемые структуры и любые другие встроенные структуры данных, которые предоставляет Python.