Функции repr() и str() в python
Содержание:
- ISNUMERIC (): Как проверить числовые численности только в строке в Python
- Как обрабатывать многослойные строки в Python
- Создание Подстроки Python С Помощью Метода Slice
- Вопросы пользователей по теме Python
- Производительность
- 5 способов форматирования строк
- Rjust (): как правильно озвучить строку в Python
- Строковые функции, методы и операторы
- Escape Sequences
- Как создать строку
- Идите с миром и форматируйте!
- Произвольные выражения
- Сигналы между потоками
- re.split()
- Центр (): Как центрировать строку в Python
- Строки байтов — bytes и bytearray
- lstrip () vs readleprefix () и rstrip () vs removeuffix ()
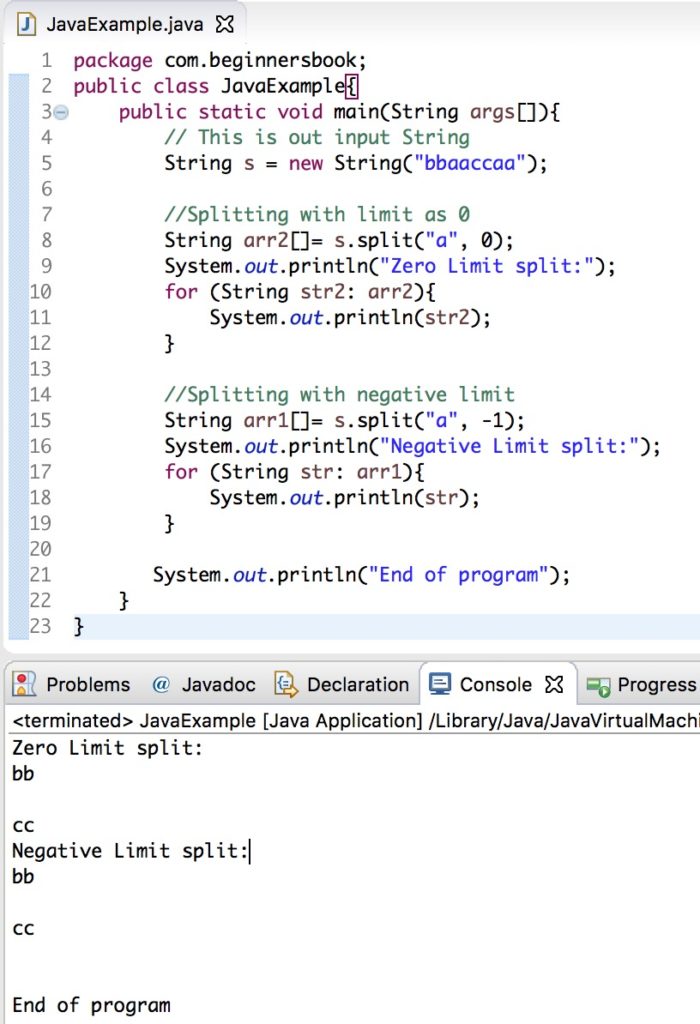
- Пример __str__ и __repr__ в Python
- Создание строк и вывод их на экран
ISNUMERIC (): Как проверить числовые численности только в строке в Python
Используйте Метод проверки, содержит ли строка только числовые символы.
Числовые включают число от 0 до 9 и комбинации их, римских цифр, суперскрипет, подписку, фракций и других вариаций.
word = '32'
print(word.isnumeric())
#output: True
print("\u2083".isnumeric()) #unicode for subscript 3
#output: True
print("\u2169".isnumeric()) #unicode for roman numeral X
#output: True
word = 'beach'
print(word.isnumeric())
#output: False
word = 'number32'
print(word.isnumeric())
#output: False
word = '1 2 3' #notice the space between chars
print(word.isnumeric())
#output: False
word = '@32$' #notice the special chars '@' and '$'
print(word.isnumeric())
#output: False
более строгим, чем , который в свою очередь строчен, чем Отказ
Как обрабатывать многослойные строки в Python
Тройные цитаты
Чтобы обрабатывать многослойные струны в Python, вы используете тройные цитаты, либо одиноки, либо двойные.
Этот первый пример использует двойные кавычки.
long_text = """This is a multiline, a long string with lots of text, I'm wrapping it in triple quotes to make it work.""" print(long_text) #output: #This is a multiline, # #a long string with lots of text, # #I'm wrapping it in triple quotes to make it work.
Сейчас так же, как и раньше, но с одиночными цитатами:
long_text = '''This is a multiline, a long string with lots of text, I'm wrapping it in triple quotes to make it work.''' print(long_text) #output: #This is a multiline, # #a long string with lots of text, # #I'm wrapping it in triple quotes to make it work.
Обратите внимание, что оба выхода одинаковы
Круглые скобки
Давайте посмотрим пример с круглыми скобками.
long_text = ("This is a multiline, "
"a long string with lots of text "
"I'm wrapping it in brackets to make it work.")
print(long_text)
#This is a multiline, a long string with lots of text I'm wrapping it in triple quotes to make it work.
Как видите, результат не то же самое. Для достижения новых строк я должен добавить , как это:
long_text = ("This is a multiline, \n\n"
"a long string with lots of text \n\n"
"I'm wrapping it in brackets to make it work.")
print(long_text)
#This is a multiline,
#
#a long string with lots of text
#
#I'm wrapping it in triple quotes to make it work.
Вершины
Наконец, обратные косания также являются возможностью.
Уведомление нет места после персонаж, как он бросил бы ошибку.
long_text = "This is a multiline, \n\n" \ "a long string with lots of text \n\n" \ "I'm using backlashes to make it work." print(long_text) #This is a multiline, # #a long string with lots of text # #I'm wrapping it in triple quotes to make it work.
Создание Подстроки Python С Помощью Метода Slice
- Во-первых, вы должны хранить строку в переменной Python. Наш пример:
- С помощью команды “str ” теперь вы выведете строку без первых четырех символов: ‘o world this is Karan from Python Pool’
- С помощью команды “str ” в свою очередь выводятся только первые четыре символа: “Hello”
- Команда “str ”, которая выводит строку без последних двух символов, также очень практична: “Hello world this is Karan from Python Po”
- Это также работает наоборот, “str” так что выводятся только последние два символа:”ol”
- Наконец, вы также можете комбинировать команды. Например, команда “x ” выводит строку без первых и последних четырех символов:’o world this is Karan from Python ‘
Вы можете выполнить все вышеперечисленные команды в терминале Python, как показано на рисунке ниже.
Вопросы пользователей по теме Python
Pandas DataFrame Drop 0.000000 значений после .sum ()
Как можно удалить строки со значениями 0.000000 из фрейма данных?
Например:
PassengerId 0.000000
Survived 0.000000
Pclass 0.000000
Name 0.000000
Sex 0.000000
Age 0.198653
SibSp 0.000000
Parch 0.000000
Ticket 0.000000
Fare ….
1 Сен 2021 в 19:20
Какую аннотацию возвращаемого типа использовать, если функция возвращает модуль в Python?
Я пишу функцию, чтобы помочь с необязательной зависимостью (аналогично pytest.importorskip), и я хотел бы ввести его, но не знаю, какой тип использовать. Поскольку я всегда возвращаю определенный модуль или None, я думаю, что могу быть более конкретным, чем «Any».
def try_import_pyarrow():
try:….
1 Сен 2021 в 18:30
Python 3.9.6 — Попытка установить флаг в False. Продолжайте получать ошибку TypeError: ‘<‘ не поддерживается между экземплярами ‘str’ и ‘int’
В приведенном ниже коде я пытаюсь установить флаг «активный» в значение «Ложь». Это не удается. Программа должна прекратить работу, когда возраст «выйдет», но продолжит работу.
Я вижу, что ошибка связана с тем, что я пытаюсь сравнить строку и целое число, но я не знаю, почему программа достигает э….
1 Сен 2021 в 18:21
сделать декоратор Только создатель Контента может управлять им
Я создал два декоратора, чтобы заблокировать кому-либо доступ к определенному контенту, например:
@method_decorator(login_required(login_url=’core:login’), name=’dispatch’)
@method_decorator(allowed_users(allowed_roles=), name=’dispatch’)
class BookDeleteView(BSModalDeleteView):
….
1 Сен 2021 в 18:14
Сохранять только столбцы в Pandas Dataframe на основе нескольких условий
Предположим следующий фрейм данных:
import pandas as pd
data = {‘Name’: ,
‘Height of Person’: ,
‘Qualification’: ,
‘Country is’:
}
df = pd.DataFrame(data)
d….
1 Сен 2021 в 17:45
Экспорт в формат csv Python Dataframe
Фрейм данных Pycharm
У меня есть фрейм данных, который отображается именно так, как я хочу, но когда я использую функцию pandas to_csv, файл csv содержит множество специальных символов, которых нет в pycharm. есть идеи о том, как экспортировать точный формат pycharm df?
экспортированный формат csv….
1 Сен 2021 в 17:30
Как я могу пометить индекс как «используемый» при итерации по списку?
Я буду перебирать list of integers, nums, несколько раз, и каждый раз, когда целое число было «использовано» для чего-то (неважно что), я хочу отметить индекс как используемый. Так что в будущих итерациях я больше не буду использовать это целое число.
Два вопроса:
Моя идея — просто создать отдельны….. 1 Сен 2021 в 17:21
1 Сен 2021 в 17:21
Хранить массив Python в каждой записи столбца
У меня есть массив mutlilabel, который выглядит так:
,
,
,
…
,
]
И хочу сохранить каждый из этих массивов в моей целевой пе….
1 Сен 2021 в 17:03
Получить значение определенного ключа из файла JSON python
У меня есть файл JSON, содержащий список изменений цен на все криптовалюты Я хочу извлечь все ‘percentage’ для всех монет.
Используя приведенный ниже код, он выдает ошибку TypeError: строковые индексы должны быть целыми числами (что, как я знаю, совершенно неверно, в основном я пытаюсь понять, как ….
1 Сен 2021 в 16:48
Индексирующий массив с массивом на numpy
Это похоже на некоторые вопросы по SO, но я не совсем понимаю, как получить то, что я хочу.
У меня два массива, arr формы (x, y, z) индексы формы (x, y), которые содержат интересующие индексы для z.
Для каждого индексов я хочу получить фактическое значение в arr , где:
arr.x == indexes.x
….
1 Сен 2021 в 16:43
Производительность
F-строки не только гибкие, но и быстрые. И для сравнения производительности разных подходов к форматированию я подготовил два шаблона:
- простой, в который нужно вставить всего два значения: строку и число;
- сложный, данные для которого собираются из разных переменных, а внутри происходит преобразование даты, вещественного числа, а также округление.
Финальная простая строка получается такой:
Сложная строка на выходе такая:
Далее я написал 5 функций, каждая из которых возвращает строку отформатированную одним из способом, а после запустил каждую функцию много раз. Пример всех функций и тестового скрипта можете скачать тут.
После недолгого тестирования я получил следующие результаты:
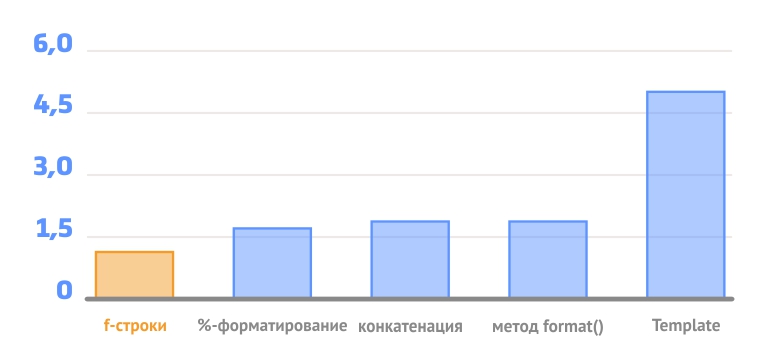
На простых примерах f-строки показывают самые лучшие результаты.На 25% быстрее %-форматирования и метода format().
5 способов форматирования строк
1. Конкатенация. Грубый способ форматирования, в котором мы просто склеиваем несколько строк с помощью операции сложения:
2. %-форматирование. Самый популярный способ, который перешел в Python из языка С. Передавать значения в строку можно через списки и кортежи , а также и с помощью словаря. Во втором случае значения помещаются не по позиции, а в соответствии с именами.
3. Template-строки. Этот способ появился в Python 2.4, как замена %-форматированию (), но популярным так и не стал. Поддерживает передачу значений по имени и использует $-синтаксис как в PHP.
4. Форматирование с помощью метода format(). Этот способ появился в Python 3 в качестве замены %-форматированию. Он также поддерживает передачу значений по позиции и по имени.
5. f-строки. Форматирование, которое появилось в Python 3.6 (). Этот способ похож на форматирование с помощью метода format(), но гибче, читабельней и быстрей.
Rjust (): как правильно озвучить строку в Python
Используйте направо – оправдать строку.
word = 'beach' number_spaces = 32 word_justified = word.rjust(number_spaces) print(word) #'beach' print(word_justified) #' beach'
Обратите внимание на пробелы во второй строке. Слово «Beach» имеет 5 символов, что дает 27 пространства для заполнения пустым пространством
Оригинал Переменная остается неизменным, поэтому нам нужно назначить возврат метода новой переменной, в таком случае.
Также принимает определенный символ в качестве параметра для заполнения оставшегося пространства.
word = 'beach' number_chars = 32 char = '$' word_justified = word.rjust(number_chars, char) print(word) #beach print(word_justified) #$$$$$$$$$$$$$$$$$$$$$$$$$$$beach
Похоже на первую ситуацию, у меня есть 27 Знаки, чтобы сделать его 32, когда я считаю 5 символов, содержащихся в словом «Beach».
Строковые функции, методы и операторы
Строки являются последовательностями, а последовательности в языке Python образуют целый класс типов данных, который объединяет наличие общих свойств, а следовательно, общих функций и операторов. Например списки – это последовательности объектов, доступ к которым так же осуществляется по их индексу:
Списки, так же как и строки могут «складываться» (соединяться) и «умножаться» (дублироваться):
Для определения длины строк, списков и прочих последовательностей, можно воспользоваться функцией :
Операторы и позволяют выяснить наличие или отсутствие в последовательности некоторого элемента:
С помощью оператора можно осуществлять перебор всех элементов любой последовательности в цикле :
Поскольку работа с текстовыми данными занимает значительную часть повседневной деятельности, то неудивительно, что строки обзавелись большим количеством встроенных методов, которые позволяют выполнять самые распространенные действия над ними. Вот лишь малая часть этих методов:
Что бы посмотреть на список всех доступных строкам функций и методов достаточно передать функции какой-нибудь строковый объект:
Мы не спроста, воспользовались модулем так как простая команда привела бы к выводу длинного списка в виде одной длинной строки. Имейте ввиду, что данный модуль может оказаться очень полезным для организации удобочитаемого вывода данных и в некоторых ситуациях, гораздо проще воспользоваться именно им, чем ломать голову над форматированием строки для удобочитаемого вывода.
Escape Sequences
Экранированный символ теряет своё изначальное значение
и воспринимается интерпретатором как обычный символ либо наоборот приобретает дополнительный смысл как мы уже видели на
примере \n
Сравните
>>> «This is n it is a normal symbol»
‘This is n it is a normal symbol’
>>> s = «This is n it is a normal symbol»
>>> print(s)
This is n it is a normal symbol
И
>>> «This is \n it is an escaped symbol»
‘This is \n it is an escaped symbol’
>>> s = «This is \n it is an escaped symbol»
>>> print(s)
This is
it is an escaped symbol
Вместо n теперь перенос строки
Экранирование можно применить для использования одинаковых кавычек внутри и снаружи строки
>>> «Двойная кавычка \» внутри двойных»
‘Двойная кавычка » внутри двойных’
>>> ‘Одинарная кавычка \’ внутри одинарных’
‘Одинарная кавычка ‘ внутри одинарных’
Если экранирование не подразумевается, то \ будет всё равно будет воспринят интерпретатором как попытка экранирования и не появится как обычный символ
>>> ‘Двойную кавычку \» можно не экранировать внутри одинарных а \’ одинарную нужно’
‘Двойную кавычку » можно не экранировать внутри одинарных а \’ одинарную нужно’
>>> s = ‘Двойную кавычку \» можно не экранировать внутри одинарных а \’ одинарную нужно’
>>> print(s)
Двойную кавычку » можно не экранировать внутри одинарных а ‘ одинарную нужно
Чтобы всё-таки увидеть \ нужно написать \\ то есть проэкранировать символ экранирования
>>> s = ‘\\’
>>> print(s)
| Escape Sequence | Значение | Примечания |
|---|---|---|
| \newline | Backslash and newline ignored | |
| \\ | Backslash (\) | |
| \’ | Single quote (‘) | |
| \» | Double quote («) | |
| \a | ASCII Bell (BEL) | |
| \b | ASCII Backspace (BS) | |
| \f | ASCII Formfeed (FF) | |
| \n | ASCII Linefeed (LF) | |
| \r | ASCII Carriage Return (CR) | |
| \t | ASCII Horizontal Tab (TAB) | |
| \v | ASCII Vertical Tab (VT) | |
| \ooo | Character with octal value ooo |
(1,3) |
| \xhh | Character with hex value hh | (2,3) |
| Escape Sequence | Значение | Примечания |
|---|---|---|
| \N{name} | Character named name in the Unicode database | (4) |
| \uxxxx | Character with 16-bit hex value xxxx | (5) |
| \Uxxxxxxxx | Character with 32-bit hex value xxxxxxxx | (6) |
Примечания:
As in Standard C, up to three octal digits are accepted.
Unlike in Standard C, exactly two hex digits are required.
In a bytes literal, hexadecimal and octal escapes denote the byte with the given value. In a string literal, these escapes denote a Unicode character with the given value.
Changed in version 3.3: Support for name aliases 1 has been added.
Exactly four hex digits are required.
Any Unicode character can be encoded this way. Exactly eight hex digits are required.
Как создать строку
Строки всегда создаются одним из трех способов. Вы можете использовать одинарные, двойные и тройные скобки. Давайте посмотрим
Python
my_string = «Добро пожаловать в Python!»
another_string = ‘Я новый текст тут…’
a_long_string = »’А это у нас
новая строка
в троичных скобках»’
|
1 2 3 4 5 6 |
my_string=»Добро пожаловать в Python!» another_string=’Я новый текст тут…’ a_long_string=»’А это у нас новая строка |
Строка с тремя скобками может быть создана с использованием трех одинарных скобок или трех двойных скобок. Так или иначе, с их помощью программист может писать строки в нескольких линиях. Если вы впишете это, вы увидите, что выдача сохраняет разрыв строк. Если вам нужно использовать одинарные скобки в вашей строке, то впишите двойные скобки. Давайте посмотрим на пример:
Python
my_string = «I’m a Python programmer!»
otherString = ‘Слово «Python» обычно подразумевает змею’
tripleString = «»»В такой «строке» мы можем ‘использовать’ все.»»»
|
1 2 3 |
my_string=»I’m a Python programmer!» otherString=’Слово «Python» обычно подразумевает змею’ tripleString=»»»В такой «строке» мы можем ‘использовать’ все.»»» |
Данный код демонстрирует то, как вы можете вписать одинарные или двойные скобки в строку. Существует еще один способ создания строки, при помощи метода str. Как это работает:
Python
my_number = 123
my_string = str(my_number)
|
1 2 |
my_number=123 my_string=str(my_number) |
Если вы впишете данный код в ваш интерпретатор, вы увидите, что вы изменили значение интегратора на строку и присвоили ее переменной my_string. Это называется кастинг, или конвертирование. Вы можете конвертировать некоторые типы данных в другие, например числа в строки. Но вы также заметите, что вы не всегда можете делать обратное, например, конвертировать строку вроде ‘ABC’ в целое число. Если вы сделаете это, то получите ошибку вроде той, что указана в этом примере:
Python
int(‘ABC’)
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
ValueError: invalid literal for int() with base 10: ‘ABC’
|
1 2 3 4 5 |
int(‘ABC’) Traceback(most recent call last) File»<string>»,line1,in<fragment> ValueErrorinvalid literal forint()withbase10’ABC’ |
Мы рассмотрели обработку исключений в другой статье, но как вы могли догадаться из сообщения, это значит, что вы не можете конвертировать сроки в цифры. Тем не менее, если вы вписали:
Python
x = int(«123»)
| 1 | x=int(«123») |
То все должно работать
Обратите внимание на то, что строка – это один из неизменных типов Python. Это значит, что вы не можете менять содержимое строки после ее создания
Давайте попробуем сделать это и посмотрим, что получится:
Python
my_string = «abc»
my_string = «d»
Traceback (most recent call last):
File «<string>», line 1, in <fragment>
TypeError: ‘str’ object does not support item assignment
|
1 2 3 4 5 6 |
my_string=»abc» my_string=»d» Traceback(most recent call last) File»<string>»,line1,in<fragment> TypeError’str’objectdoes notsupport item assignment |
Здесь мы пытаемся изменить первую букву с «а» на «d«, в итоге это привело к ошибке TypeError, которая не дает нам сделать это. Теперь вы можете подумать, что присвоение новой строке то же значение и есть изменение строки. Давайте взглянем, правда ли это:
Python
my_string = «abc»
a = id(my_string)
print(a) # 19397208
my_string = «def»
b = id(my_string)
print(b) # 25558288
my_string = my_string + «ghi»
c = id(my_string)
print(c) # 31345312
|
1 2 3 4 5 6 7 8 9 10 11 |
my_string=»abc» a=id(my_string) print(a)# 19397208 my_string=»def» b=id(my_string) print(b)# 25558288 my_string=my_string+»ghi» c=id(my_string) print(c)# 31345312 |
Проверив id объекта, мы можем определить, что когда мы присваиваем новое значение переменной, то это меняет тождество
Обратите внимание, что в версии Python, начиная с 2.0, строки могут содержать только символы ASCII. Если вам нужен Unicode, тогда вы должны вписывать u перед вашей строкой
Пример:
Python
# -*- coding: utf-8 -*-
my_unicode_string = u»Это юникод!»
|
1 2 |
# -*- coding: utf-8 -*- my_unicode_string=u»Это юникод!» |
В Python, начиная с версии 3, все строки являются юникодом.
Идите с миром и форматируйте!
Разумеется, вы можете использовать старые методы форматирования строк, но с f-строками у вас есть более лаконичный, читаемый и удобный способ, который одновременно и быстрее, и менее вероятно приведет к ошибке. Упростить свою жизнь используя f-строки — отлична причина пользоваться Python 3.6, если вы еще не перешли к этой версии. (Если вы все еще пользуетесь Python 2.7, не беспокойтесь, 2020 год не за горами!)
Согласно дзену Python, когда вам нужно выбрать способ решения задачи, всегда “есть один — и желательно только один очевидный способ сделать это”. Кстати, f-строки не являются единственным способом форматирования строк. Однако, их использование вполне может стать единственным адекватным способом.
Произвольные выражения
Так как f-строки оцениваются по мере выражения, вы можете внести любую или все доступные выражения Python в них. Это позволит вам делать интересные вещи, например следующее:
Python
print(f»{2 * 37}»)
# Вывод: ’74’
|
1 2 |
print(f»{2 * 37}») # Вывод: ’74’ |
Также вы можете вызывать функции. Пример:
Python
def to_lowercase(input):
return input.lower()
name = «Eric Idle»
print(f»{to_lowercase(name)} is funny.»)
# Вывод: ‘eric idle is funny.’
|
1 2 3 4 5 6 7 |
defto_lowercase(input) returninput.lower() name=»Eric Idle» print(f»{to_lowercase(name)} is funny.») # Вывод: ‘eric idle is funny.’ |
Также вы можете вызывать метод напрямую:
Python
print(f»{name.lower()} is funny.»)
# Вывод: ‘eric idle is funny.’
|
1 2 |
print(f»{name.lower()} is funny.») # Вывод: ‘eric idle is funny.’ |
Вы даже можете использовать объекты, созданные из классов при помощи f-строки. Представим, что у вас есть следующий класс:
Python
class Comedian:
def __init__(self, first_name, last_name, age):
self.first_name = first_name
self.last_name = last_name
self.age = age
def __str__(self):
return f»{self.first_name} {self.last_name} is {self.age}.»
def __repr__(self):
return f»{self.first_name} {self.last_name} is {self.age}. Surprise!»
|
1 2 3 4 5 6 7 8 9 10 11 |
classComedian def__init__(self,first_name,last_name,age) self.first_name=first_name self.last_name=last_name self.age=age def__str__(self) returnf»{self.first_name} {self.last_name} is {self.age}.» def__repr__(self) returnf»{self.first_name} {self.last_name} is {self.age}. Surprise!» |
Вы могли бы сделать следующее:
Python
new_comedian = Comedian(«Eric», «Idle», «74»)
print(f»{new_comedian}»)
# Вывод: ‘Eric Idle is 74.’
|
1 2 3 4 |
new_comedian=Comedian(«Eric»,»Idle»,»74″) print(f»{new_comedian}») # Вывод: ‘Eric Idle is 74.’ |
Методы __str__() и __repr__() работают с тем, как объекты отображаются в качестве строк, так что вам нужно убедиться в том, что вы используете один из этих методов в вашем определении класса. Если вы хотите выбрать один, попробуйте __repr__(), так как его можно использовать вместо __str__().
Строка, которая возвращается __str__() является неформальным строковым представлением объекта и должна быть читаемой. Строка, которую вернул __str__() — это официальное выражение и должно быть однозначным. При вызове str() и repr(), предпочтительнее использовать __str__() и __repr__() напрямую.
По умолчанию, f-строки будут использовать __str__(), но вы должны убедиться в том, что они используют __repr__(), если вы включаете флаг преобразования !r:
Python
print(f»{new_comedian}»)
# Вывод: ‘Eric Idle is 74.’
print(f»{new_comedian!r}»)
# Вывод: ‘Eric Idle is 74. Surprise!’
|
1 2 3 4 5 |
print(f»{new_comedian}») # Вывод: ‘Eric Idle is 74.’ print(f»{new_comedian!r}») # Вывод: ‘Eric Idle is 74. Surprise!’ |
Если вы хотите прочитать часть обсуждения, в результате которого f-strings поддерживают полные выражения Python, вы можете сделать это здесь.
Сигналы между потоками
Бывают случаи, когда нужно синхронизировать операции в двух или более потоках. Простой способ реализации – использование объектов Event.
Event управляет внутренним флагом, который вызывающий объект может либо устанавливать (set()) либо сбрасывать (clear()). Другие потоки могут ждать (wait()), пока флаг не будет установлен (set()),блокируя процесс, пока не будет разрешено продолжить выполнение.
import logging
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def wait_for_event(e):
"""Wait for the event to be set before doing anything"""
logging.debug('wait_for_event starting')
event_is_set = e.wait()
logging.debug('event set: %s', event_is_set)
def wait_for_event_timeout(e, t):
"""Wait t seconds and then timeout"""
while not e.isSet():
logging.debug('wait_for_event_timeout starting')
event_is_set = e.wait(t)
logging.debug('event set: %s', event_is_set)
if event_is_set:
logging.debug('processing event')
else:
logging.debug('doing other work')
e = threading.Event()
t1 = threading.Thread(name='block',
target=wait_for_event,
args=(e,))
t1.start()
t2 = threading.Thread(name='non-block',
target=wait_for_event_timeout,
args=(e, 2))
t2.start()
logging.debug('Waiting before calling Event.set()')
time.sleep(3)
e.set()
logging.debug('Event is set')
Метод wait() принимает время задержки. Он возвращает логическое значение, указывающее, установлено событие или нет. Поэтому вызывающий объект знает, почему был возвращен wait(). Метод isSet() можно использовать для события отдельно, не опасаясь блокировки.
В этом примере wait_for_event_timeout() проверяет состояние события без бесконечной блокировки. wait_for_event() блокирует вызов wait(), который не возобновляет свою работу до изменения статуса события.
$ python threading_event.py (block ) wait_for_event starting (non-block ) wait_for_event_timeout starting (MainThread) Waiting before calling Event.set() (non-block ) event set: False (non-block ) doing other work (non-block ) wait_for_event_timeout starting (MainThread) Event is set (block ) event set: True (non-block ) event set: True (non-block ) processing event
re.split()
Данный метод разделяет строку по заданному шаблону. Если шаблон найден, оставшиеся символы из строки возвращаются в виде результирующего списка. Более того, мы можем указать максимальное количество разделений для нашей строки.
Синтаксис:
Возвращаемое значение может быть либо списком строк, на которые была разделена исходная строка, либо пустым списком, если совпадений с шаблоном не нашлось.
Рассмотрим, как работает данный метод, на примере.
import re
# '\W+' совпадает с символами или группой символов, не являющихся буквами или цифрами
# разделение по запятой ',' или пробелу ' '
print(re.split('\W+', 'Good, better , Best'))
print(re.split('\W+', "Book's books Books"))
# Здесь ':', ' ' ,',' - не буквенно-цифровые символы, по которым происходит разделение
print(re.split('\W+', 'Born On 20th July 1989, at 11:00 AM'))
# '\d+' означает цифры или группы цифр
# Разделение происходит по '20', '1989', '11', '00'
print(re.split('\d+', 'Born On 20th July 1989, at 11:00 AM'))
# Указано максимальное количество разделений - 1
print(re.split('\d+', 'Born On 20th July 1989, at 11:00 AM', maxsplit=1))
# Результат:
#
#
#
#
#
Центр (): Как центрировать строку в Python
Используйте Способ для центра строки.
word = 'beach' number_spaces = 32 word_centered = word.center(number_spaces) print(word) #'beach' print(word_centered) ##output: ' beach '
Обратите внимание на пробелы во второй строке. Слово «Beach» имеет 5 символов, что дает 28 пробелов для заполнения пустым пространством, 14 пробелами до 14 лет, чтобы центрировать слово
Оригинал Переменная остается неизменным, поэтому нам нужно назначить возврат метода новой переменной, в таком случае.
Также принимает определенный символ в качестве параметра для заполнения оставшегося пространства.
word = 'beach' number_chars = 33 char = '$' word_centered = word.center(number_chars, char) print(word) #beach print(word_centered) #output: $$$$$$$$$$$$$$beach$$$$$$$$$$$$$$
Похоже на первую ситуацию, у меня 14 В каждой стороне, чтобы сделать его 33, когда я считаю 5 символов, содержащихся в словом «Beach».
Строки байтов — bytes и bytearray
Определение которое мы дале в самом начале можно считать верным только для строк типа str. Но в Python имеется еще два дугих типа строк: bytes – неизменяемое строковое представление двоичных данных и bytearray – тоже что и bytes, только допускает непосредственное изменение.
Основное отличие типа str от bytes и bytearray заключается в том, что str всегда пытается превратить последовательность байтов в текст указанной кодировки. По умолчанию этой кодировкой является utf-8, но это очень большая кодировка и другие кодировки, например ASCII, Latin-1 и другие являются ее подмножествами
Одни символы кодируются одним байтом, другие двумя, а некоторые тремя и функция при декодировании последовательности байтов принимает это во внимание. А вот функциям и до этого нет дела, для них абсолютно все данные состоят только из последовательности одиночных байтов.
Такое поведение bytes и bytearray очень удобно, если вы работаете с изображениями, аудиофайлами или сетевым трафиком. В этом случае, вам следует знать, что ничего магического в этих типах нет, они поддерживоют все теже строковые методы, операции индексирования, а так же операторы и функции для работы с последовательностями. Единственное, что следует держать в уме, так это то, что вы имеете дело с последовательностью байтов, т.е. последовательностью чисел из интервала в шестнадцатеричном представлении, и что байтовые строки отличаются от обычных символом (реже) предваряющим все литералы обычных строк.
Например, что бы создать строку типа bytes или bytearray достаточно передать соответствующим функциям последовательности целых чисел:
Учитывая то, что для кодирования некоторых символов (например ASCII) достаточно всего одного байта, данные типы пытаются представить последовательности в виде символов если это возможно. Например, строка будет выведена как :
А это значит, что байтовые данные могут вполне обоснованно интерпретированться как ASCII символы и наоборот. Т.е. строки байтов могут быть созданы и так:
Но, следует помнить что это все-таки байты, в чем легко убедиться, если мы обратимся к какому-нибудь символу по его индексу в строке:
Так как строковые методы не изменяют сам объект, а создают новый, то при работе с очень длинными строками (а в мире двоичных данных это далеко не редкость) это может привести к большому расходу памяти. Собственно, по этой причине и существует тип bytearray, который позволяет менять байты прямо внутри строки:
lstrip () vs readleprefix () и rstrip () vs removeuffix ()
Это вызывает путаницу для многих людей.
Легко посмотреть на и И удивляйтесь, какая реальная разница между ними.
При использовании Аргумент – это набор ведущих персонажей, которые будут удалены столько раз, сколько они возникают:
>>> word = 'hubbubbubboo'
>>> word.lstrip('hub')
'oo'
В то время как Удалю только точное совпадение:
>>> word = 'hubbubbubboo'
>>> word.removeprefix('hub')
'bubbubboo'
Вы можете использовать ту же обоснование, чтобы различать и Отказ
>>> word = 'peekeeneenee'
>>> word.rstrip('nee')
'peek'
>>> word = 'peekeeneenee'
>>> word.removesuffix('nee')
'peekeenee'
И как бонус, на всякий случай, если вы никогда не работали с регулярными выражениями раньше, будьте благодарны, что у вас есть Обрезать наборы символов из строки вместо регулярного выражения:
>>> import re
>>> word = 'amazonia'
>>> word.strip('ami')
'zon'
>>> re.search('^*(.*?)*$', word).group(1)
'zon'
Пример __str__ и __repr__ в Python
Обе эти функции используются при отладке, давайте посмотрим, что произойдет, если мы не определим эти функции для объекта.
class Person:
name = ""
age = 0
def __init__(self, personName, personAge):
self.name = personName
self.age = personAge
p = Person('Pankaj', 34)
print(p.__str__())
print(p.__repr__())
Вывод:
<__main__.Person object at 0x10ff22470> <__main__.Person object at 0x10ff22470>
Как видите, реализация по умолчанию бесполезна. Давайте продолжим и реализуем оба этих метода:
class Person:
name = ""
age = 0
def __init__(self, personName, personAge):
self.name = personName
self.age = personAge
def __repr__(self):
return {'name':self.name, 'age':self.age}
def __str__(self):
return 'Person(name='+self.name+', age='+str(self.age)+ ')'
Обратите внимание, что мы возвращаем dict для функции __repr__. Посмотрим, что произойдет, если мы воспользуемся этими методами
p = Person('Pankaj', 34)
# __str__() example
print(p)
print(p.__str__())
s = str(p)
print(s)
# __repr__() example
print(p.__repr__())
print(type(p.__repr__()))
print(repr(p))
Вывод:
Person(name=Pankaj, age=34)
Person(name=Pankaj, age=34)
Person(name=Pankaj, age=34)
{'name': 'Pankaj', 'age': 34}
<class 'dict'>
File "/Users/pankaj/Documents/PycharmProjects/BasicPython/basic_examples/str_repr_functions.py", line 29, in <module>
print(repr(p))
TypeError: __repr__ returned non-string (type dict)
Обратите внимание, что функция repr() выдает ошибку TypeError, поскольку наша реализация __repr__ возвращает dict, а не строку. Изменим реализацию функции __repr__ следующим образом:
Изменим реализацию функции __repr__ следующим образом:
def __repr__(self):
return '{name:'+self.name+', age:'+str(self.age)+ '}'
Теперь он возвращает String, и новый вывод для вызовов представления объекта будет:
{name:Pankaj, age:34}
<class 'str'>
{name:Pankaj, age:34}
Ранее мы упоминали, что если мы не реализуем функцию __str__, то вызывается функция __repr__. Просто прокомментируйте реализацию функции __str__ из класса Person, и print (p) напечатает {name: Pankaj, age: 34}.
Создание строк и вывод их на экран
Строки в Python записываются либо с помощью одинарных » либо с помощью двойных «» кавычек. Поэтому, для того, чтобы создать строку, давайте заключим последовательность символов в один из видов этих кавычек.
'Это строка заключена в одинарные кавычки'
"Это строка заключена в двойные кавычки"
Вы можете использовать либо одинарные либо двойные кавычки, но чтобы вы не выбрали, вам следует придерживаться этого на протяжении всей программы.
Мы можем выводить на экран наши строки просто используя функцию .
print("Давайте выведем на экран эту строку!")
Давайте выведем на экран эту строку!
Используя знания о форматировании строк в Python давайте теперь посмотрим, как мы можем обрабатывать и изменять строки в программах.