Sql — что это, и какие плюсы использования этого языка?
Содержание:
- Ключевые слова SQL SOME | ANY и ALL
- Команда UPDATE
- Вставка (INSERT)
- Описание команды SELECT
- SQL Подстановочные знаки
- SQL Учебник
- Создание и настройка базы данных
- Зачем мне изучать SQL, если я занимаюсь данными?
- Группировка GROUP BY
- Пишите запросы как можно проще
- Что такое язык запросов SQL?
- Парсинг и компиляция запроса
- Подзапросы SQL-примеры
- Сравнение данных за две даты
Ключевые слова SQL SOME | ANY и ALL
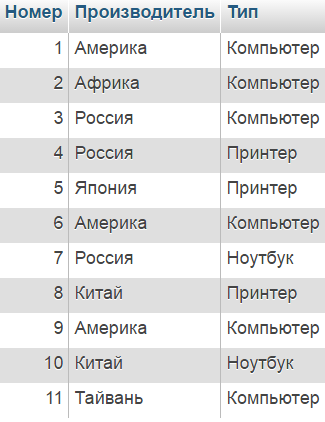
Пример: Найти поставщиков компьютеров, у которых номера отсутствуют в продаже (т.е. отсутствуют в таблице )
Решение:
Исходные данные таблиц:
| Таблица product: |
 |
| Таблица pc: |
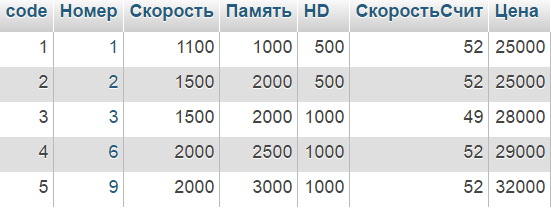 |
Решение:
1 2 3 4 5 6 7 |
SELECT DISTINCT Производитель FROM product WHERE Тип = "Компьютер" AND NOT Номер = ANY( SELECT Номер FROM pc ) |
Результат:
В примере предикат вернет в том случае значение TRUE, когда Номер из основного запроса найдется в списке Номеров таблицы (возвращаемом подзапросом). Кроме того, используется . Результирующий набор будет состоять из одного столбца — Производитель. Чтобы один производитель не выводился несколько раз, введено служебное слово .
Теперь рассмотрим использование ключевого слова ALL:
Пример: Найти номера и цены ноутбуков, стоимость которых превышает стоимость любого компьютера
Решение:
1 2 3 4 5 6 7 |
SELECT DISTINCT Номер, Цена FROM notebook WHERE Цена > ALL ( SELECT цена FROM pc ) |
Результат:
Важно: Стоит заметить, что в общем случае запрос с возвращает множество значений. Поэтому использование подзапроса в предложении без операторов , , и , которые дают булево значение (логическое), может привести к ошибке времени выполнения запроса
Пример: Найти номера и цены компьютеров, стоимость которых превышает минимальную стоимость ноутбуков. Решение:
Решение:
1 2 3 4 5 |
SELECT DISTINCT `Номер` , `Цена` FROM `pc` WHERE `Цена` > ( SELECT MIN(`Цена`) FROM notebook) |
Этот запрос корректен по той причине, что скалярное выражение сравнивается с подзапросом, который возвращает единственное значение
Команда UPDATE
Команда UPDATE — производит изменения в уже существующей записи или во множестве записей в таблице SQL. Изменяет существующие значения в таблице или в основной таблице представления.
Команда UPDATE Синтаксис команды
Синтаксис команды UPDATE
Команда UPDATE. Основные ключевые слова и параметры команды UPDATE
- schema — идентификатор полномочий, обычно совпадающий с именем некоторого пользователя
- table view — имя таблицы SQL, в которой изменяются данные; если определяется представление, данные изменяются в основной таблице SQL представления
- subquery_1 — подзапрос, который сервер обрабатывает тем же самым способом как представление
- сolumn — столбец таблицы SQL или представления SQL, значение которого изменяется; если столбец таблицы из предложения SET опускается, значение столбца остается неизменяемым
- expr — новое значение, назначаемое соответствующему столбцу; это выражение может содержать главные переменные и необязательные индикаторные переменные
- subquery_2 — новое значение, назначаемое соответствующему столбцу
- subquery_3 — новое значение, назначаемое соответствующему столбцу
WHERE — определяет диапазон изменяемых строк теми, для которых определенное условие является TRUE; если опускается эта фраза, модифицируются все строки в таблице или представлении.
При выдаче утверждения UPDATE включается любой UPDATE-триггер, определенный на таблице.Подзапросы. Если предложение SET содержит подзапрос, он возвращает точно одну строку для каждой модифицируемой строки. Каждое значение в результате подзапроса назначается соответствующим столбцам списка в круглых скобках. Если подзапрос не возвращает никакие строки, столбцу назначается NULL. Подзапросы могут выбирать данные из модифицируемой таблицы. Предложение SET может совмещать выражения и подзапросы.
Команда UPDATE Пример 1
Изменение для всех покупателей рейтинга на значение, равное 200:
Команда UPDATE Пример 2
Замена значения столбца во всех строках таблицы, как правило, используется редко. Поэтому в команде UPDATE, как и в команде DELETE, можно использовать предикат. Для выполнения указанной замены значений столбца rating, для всех покупателей, которые обслуживаются продавцом Giovanni (snum = 1003), следует ввести:
Команда SQL UPDATE Пример 3
В предложении SET можно указать любое количество значений для столбцов, разделенных запятыми:
Команда UPDATE Пример 4
В предложении SET можно указать значение NULL без использования какого-либо специального синтаксиса (например, такого как IS NULL). Таким образом, если нужно установить все рейтинги покупателей из Лондона (city = ‘London’) равными NULL-значению, необходимо ввести:
Команда UPDATE Пример 5
Поясняет использование следующих синтаксических конструкций команды UPDATE:
- Обе формы предложения SET вместе в одном утверждении.
- Подзапрос.
- Предложение WHERE, ограничивающее диапазон модифицируемых строк.
Вышеупомянутое утверждение UPDATE выполняет следующие операции:
- Модифицирует только тех служащих, кто работают в Dallas или Detroit
- Устанавливает значение колонки deptno для служащих из Бостона
- Устанавливает жалованье каждого служащего в 1.1 раз больше среднего жалованья всего отдела
- Устанавливает комиссионные каждого служащего в 1.5 раза больше средних комиссионных всего отдела
Вставка (INSERT)
Синтаксис 1:
> INSERT INTO <table> (<fields>) VALUES (<values>)
Синтаксис 2:
> INSERT INTO <table> VALUES (<values>)
* где table — имя таблицы, в которую заносим данные; fields — перечисление полей через запятую; values — перечисление значений через запятую.
* первый вариант позволит сделать вставку только по перечисленным полям — остальные получат значения по умолчанию. Второй вариант потребует вставки для всех полей.
1. Вставка нескольких строк одним запросом:
> INSERT INTO cities (`name`, `country`) VALUES (‘Москва’, ‘Россия’), (‘Париж’, ‘Франция’), (‘Фунафути’ ,’Тувалу’);
* в данном примере мы одним SQL-запросом добавим 3 записи.
2. Вставка из другой таблицы (копирование строк, INSERT + SELECT):
Синтаксис при копировании строк из одной таблицы в другую выглядит так:
> INSERT INTO <table1> SELECT * FROM <table2> WHERE <условие для select>;
* где table1 — куда копируем; table2 — откуда копируем.
а) скопировать все без разбора:
> INSERT INTO cities-new SELECT * FROM cities;
* в данном примере мы скопируем все строки из таблицы cities в таблицу cities-new.
б) скопировать определенные столбцы строк с условием:
> INSERT INTO cities-new (`name`, `country`) SELECT `name`, `country` FROM cities WHERE name LIKE ‘М%’;
* извлекаем все записи из таблицы cities, названия которых начинаются на «М» и заносим в таблицу cities-new.
в) копирование с обновлением повторяющихся ключей.
Если копировать таблицы несколько раз, то может возникнуть проблема повторения первичного ключа. В базах данных значения таких ключей должны быть уникальными и при попытке вставить повтор мы получим ошибку «Duplicate entry ‘xxx’ for key ‘PRIMARY’». Чтобы новые строки вставить, а повторяющиеся обновить (если есть изменения), используем «ON DUPLICATE KEY UPDATE»:
> INSERT INTO cities-new SELECT * FROM cities ON DUPLICATE KEY UPDATE `name`=VALUES(`name`), `country`=VALUES(`country`);
* в данном примере, как и в предыдущих, мы копируем данные из таблицы cities в таблицу cities-new. Но при совпадении значений первичного ключа мы будем обновлять поля name и country.
Описание команды SELECT
Основой всех синтаксических конструкций, начинающихся с ключевого слова SELECT, является синтаксическая конструкция “табличное выражение”.
Семантика табличного выражения состоит в том, что на основе последовательного применения разделов FROM, WHERE, GROUP BY и HAVING из заданных в разделе FROM таблиц строится некоторая новая результирующая таблица, порядок следования строк которой не определен и среди строк которой могут находиться дубликаты (т.е. в общем случае таблица-результат табличного выражения является мультимножеством строк).
Наиболее общей является конструкция “спецификация курсора”. Курсор — это понятие языка SQL, позволяющее с помощью набора специальных операторов получить построчный доступ к результату запроса к БД. К табличным выражениям, участвующим в спецификации курсора, не предъявляются какие- либо ограничения. При определении спецификации курсора используются три дополнительных конструкции: спецификация запроса, выражение запросов и раздел ORDER BY.
В спецификации запроса задается список выборки (список арифметических выражений над значениями столбцов результата табличного выражения и констант). В результате применения списка выборки к результату табличного выражения производится построение новой таблицы, содержащей то же число строк, но вообще говоря другое число столбцов, содержащих результаты вычисления соответствующих арифметических выражений из списка выборки.
Выражение запросов — это выражение, строящееся по указанным синтаксическим правилам на основе спецификаций запросов. Единственной операцией, которую разрешается использовать в выражениях запросов, является операция UNION (объединение таблиц) с возможной разновидностью UNION ALL.
Оператор выборки — это отдельный оператор языка SQL, позволяющий получить результат запроса в прикладной программе без привлечения курсора. Поэтому оператор выборки имеет синтаксис, отличающийся от синтаксиса спецификации курсора, и при его выполнении возникают ограничения на результат табличного выражения. Фактически, и то, и другое диктуется спецификой оператора выборки как одиночного оператора SQL: при его выполнении результат должен быть помещен в переменные прикладной программы. Поэтому в операторе появляется раздел INTO, содержащий список переменных прикладной программы, и возникает то ограничение, что результирующая таблица должна содержать не более одной строки.
В диалекте SQL СУБД Oracle поддерживается расширенный вариант оператора выборки, результатом которого не обязательно является таблица из одной строки. Такое расширение не поддерживается ни в SQL/89, ни в SQL/92.
Подзапрос — запрос, который может входить в предикат условия выборки оператора SQL.
Кстати, данную статью Вы можете найти в интернете по запросам:
Команда SELECT, Синтаксис команды SELECT, Описание команды SELECT.
- SELECT
- Команда SELECT
- SQL SELECT
- Синтаксис команды SELECT
- Описание команды SELECT
SQL Подстановочные знаки
Подстановочный знак используется для замены одного или нескольких символов в строке.
Подстановочные знаки используются с оператором SQL LIKE.
Оператор LIKE используется в предложении WHERE для поиска указанного шаблона в столбце.
Подстановочные знаки в MS Access
| Символ | Описание | Пример |
|---|---|---|
| * | Представляет ноль или более символов | bl* finds bl, black, blue, and blob |
| ? | Представляет собой один символ | h?t finds hot, hat, and hit |
| [] | Представляет любой отдельный символ в квадратных скобках | ht finds hot and hat, but not hit |
| ! | Представляет собой любой символ, не заключенный в скобки | ht finds hit, but not hot and hat |
| — | Представляет собой набор символов | ct finds cat and cbt |
| # | Представляет собой любой отдельный числовой символ | 2#5 finds 205, 215, 225, 235, 245, 255, 265, 275, 285, and 295 |
Подстановочные знаки в SQL Server
| Символ | Описание | Пример |
|---|---|---|
| % | Представляет ноль или более символов | bl% finds bl, black, blue, and blob |
| _ | Представляет собой один символ | h_t finds hot, hat, and hit |
| [] | Представляет любой отдельный символ в квадратных скобках | ht finds hot and hat, but not hit |
| ^ | Представляет собой любой символ, не заключенный в скобки | ht finds hit, but not hot and hat |
| — | Представляет собой набор символов | ct finds cat and cbt |
Все подстановочные знаки также могут быть использованы в комбинациях!
Вот несколько примеров, показывающих различные операторы LIKE с подстановочными знаками ‘%’ и ‘_’:
| Оператор LIKE | Описание |
|---|---|
| WHERE CustomerName LIKE ‘a%’ | Находит любые значения, которые начинаются с «a» |
| WHERE CustomerName LIKE ‘%a’ | Находит любые значения, которые заканчиваются на «a» |
| WHERE CustomerName LIKE ‘%or%’ | Находит любые значения, которые имеют «or» в любой позиции |
| WHERE CustomerName LIKE ‘_r%’ | Находит любые значения, имеющие букву «r» во второй позиции |
| WHERE CustomerName LIKE ‘a_%_%’ | Находит любые значения, начинающиеся с буквы «a» и имеющие длину не менее 3 символов |
| WHERE ContactName LIKE ‘a%o’ | Находит любые значения, которые начинаются с «a» и заканчиваются на «o» |
SQL Учебник
SQL ГлавнаяSQL ВведениеSQL СинтаксисSQL SELECTSQL SELECT DISTINCTSQL WHERESQL AND, OR, NOTSQL ORDER BYSQL INSERT INTOSQL Значение NullSQL Инструкция UPDATESQL Инструкция DELETESQL SELECT TOPSQL MIN() и MAX()SQL COUNT(), AVG() и …SQL Оператор LIKESQL ПодстановочныйSQL Оператор INSQL Оператор BETWEENSQL ПсевдонимыSQL JOINSQL JOIN ВнутриSQL JOIN СлеваSQL JOIN СправаSQL JOIN ПолноеSQL JOIN СамSQL Оператор UNIONSQL GROUP BYSQL HAVINGSQL Оператор ExistsSQL Операторы Any, AllSQL SELECT INTOSQL INSERT INTO SELECTSQL Инструкция CASESQL Функции NULLSQL ХранимаяSQL Комментарии
Создание и настройка базы данных
Нам нужна будет для примеров БД MS SQL Server 2017 и MS SQL Server Management Studio 2017.
Рассмотрим последовательность действий того, как создать SQL запрос. Воспользовавшись Management Studio, для начала создадим новый редактор скриптов. Чтобы это сделать, на стандартной панели инструментов выберем «Создать запрос». Или воспользуемся клавиатурной комбинацией Ctrl+N.
Нажимая кнопку «Создать запрос» в Management Studio, мы открываем тестовый редактор, используя который можно производить написание SQL запросов, сохранять их и запускать.
Используем для начала простые запросы SQL, благодаря которым можно создать и настроить новую БД, чтобы получить возможность в дальнейшем с ней работать.
Создадим новую БД с именем «b_library для библиотеки книг. Чтобы это делать наберем в редакторе такой SQL запрос:
CREATE DATABASE b_library;
Далее выделим введенный текст и нажмем F5 или кнопку «Выполнить». У нас создастся БД «b_library.
Все дальнейшие манипуляции мы можем провести с этой созданной нами БД. Для этого сначала подключимся к этой базе:
USE b_library;
В БД «b_library создадим таблицу авторов «tAuthors» с такими столбцами: AuthorId, AuthorFirstName, AuthorLastName, AuthorAge:
CREATE TABLE tAuthors ( AuthorId INT IDENTITY (1, 1) NOT NULL, AuthorFirstName NVARCHAR (20) NOT NULL, AuthorLastName NVARCHAR (20) NOT NULL, AuthorAge INT NOT NULL );
Заполним нашу таблицу таким авторами: Александр Пушкин, Сергей Есенин, Джек Лондон, Шота Руставели и Рабиндранат Тагор. Для этого используем такой SQL запрос:
INSERT tAuthors VALUES (‘Александр’, ‘Пушкин’, ’37’), (‘Сергей’, ‘Есенин’, ’30’), (‘Джек’, ‘Лондон’, ’40’), (‘Шота’, ‘Руставели’, ’44’), (‘Рабиндранат’, ‘Тагор’, ’80’);
Мы можем посмотреть в «tAuthors» записи, путем отправления в СУБД простого SQL запроса:
SELECT * FROM tAuthors;
В нашей БД «b_library» мы создали первую таблицу «tAuthors», заполнили «tAuthors» авторами книг и теперь можем рассмотреть различные примеры SQL запросов, которыми мы сможем взаимодействовать с БД.
Зачем мне изучать SQL, если я занимаюсь данными?
SQL весьма далек от забвения – напротив, это один из самых востребованных навыков, который вы можете найти в описаниях вакансий в области обработки больших данных, независимо от того, хотите ли вы устроиться на должность аналитика данных, инженера по данным, научного сотрудника в области данных или в качестве еще кого-либо. Этот факт подтверждается результатами исследования рынка труда, проведенным O’Reilly в 2016 году: 70% респондентов, участвовавших в опросе, подтвердили, что в своей профессиональной деятельности они используют SQL. Более того, в обзоре результатов этого исследования язык SQL занимает более высокую позицию, по сравнению с другими языками программирования, такими как R (57%) и Python (54%).
Теперь вы понимаете в чем тут дело: SQL является обязательным навыком, если вы хотите получить работу в сфере обработки больших данных.
Неплохо для языка, который был разработан еще в начале 1970-х годов прошлого века, не правда ли?
Но почему так часто используется именно этот язык? И почему он до сих пор не мертв, как многие другие языки того же поколения?
Для объяснения этого факта можно найти несколько причин: во-первых, компании в основном хранят данные в реляционных системах управления базами данных (RDBMS) или в системах управления реляционными потоками данных (RDSMS), и SQL требуется для доступа к таким хранимым данным. SQL – это универсальный язык данных: он дает вам возможность взаимодействовать практически с любой базой данных или даже создавать свои локальные базы данных!
Только имейте в виду, что существует немало реализаций SQL, которые несовместимы между собой и не обязательно соответствуют стандартам. Знание стандартного SQL, таким образом, является обязательным для каждого, желающего найти свой путь в это наукоемкой отрасли.
Кроме того, можно с уверенностью сказать, что SQL также включается в новые технологии, такие как Hive, SQL-подобный язык запросов, ориентированный на запросы и управление большими наборами данных, или Spark SQL, которые вы можете использовать для выполнения SQL запросов. Но еще раз напоминаем, SQL, который вы найдете в этих технологиях, будет отличаться от стандартного, который вы, возможно, уже знаете, но разобраться в особенностях конкретной реализации, зная стандартный SQL, вам будет значительно проще.
Если хотите, можем привести такую аналогию с линейной алгеброй: сосредоточив все усилия только на этой одной области математики, вы сможете использовать полученные знания и как хорошую основу для овладения машинным обучением!
Короче говоря, вот причины, по которым вам следует изучить язык структурированных запросов:
- Он довольно прост в изучении, даже для новичков. Рост знаний и навыков происходит довольно быстро, и вы в кратчайшие сроки научитесь писать запросы.
- Изучение SQL подчиняется принципу «однажды изученное может применяться повсюду», поэтому это отличное вложение вашего времени и сил!
- Это отличное дополнение к языкам программирования. В некоторых случаях писать запрос даже предпочтительнее, чем писать код, потому что он более эффективен!
- …
И чего же ты все еще ждешь?
Группировка GROUP BY
Можно проводить группировку значений по колонкам, например, нам нужно узнать среднюю цену для каждой модели компьютера, в данном случае запрос будет вот таким
SELECT model, AVG (price) AS AVGPrice FROM table GROUP BY model
Если вы заметили, я здесь применил присвоение «псевдонима» для более удобного восприятия результатов этого запроса, т.е. после колонки пишите AS и название, которое Вы хотите, чтобы отображалась в результатах.
Также как и при использовании условий в отдельных колонках можно указывать и условие на целую группу, с помощью функции HAVING. Например, нам нужно определить максимальную цену компьютера, сгруппированную по моделям этих компов, но максимальная цена которых, меньше 500.
SELECT model, MAX(price) FROM table GROUP BY model HAVING MAX(price) < 500
В этом случае наш запрос выдаст нам сгруппированные по моделям компьютеры, максимальная цена которых, меньше 500.
Примечание! Подробней о группировке в SQL можете почитать вот в этом материале.
Пишите запросы как можно проще
Преобразования типов данных приводят вас к следующему: вы не должны чрезмерно усложнять свои запросы. Старайтесь сохранять их простыми и эффективными. Этот совет может показаться слишком простым или глупым, особенно потому, что запросы могут быть и сложными.
Тем не менее, вы увидите на наших примерах в следующих разделах, действительно можно легко начать делать простые запросы более сложными, гораздо сложнее, чем это необходимо на самом деле.
Когда вы используете оператор в запросе, вероятно, вы не можете воспользоваться индексом.
Помните, что индекс — это структура данных, которая повышает скорость поиска данных в таблице базы данных, но она имеет свою стоимость: для поддержания индексной структуры данных необходимы дополнительные записи и дополнительное пространство для хранения. Индексы используются для быстрого поиска или поиска данных без необходимости поиска к каждой строке базы данных каждый раз, когда обращается к таблице баз данных. Индексы могут быть созданы на основе одного или нескольких столбцов в таблице базы данных.
Если вы не используете индексы, имеющиеся в базе данных, выполнение вашего запроса неизбежно займет больше времени. Вот почему лучше всего искать альтернативы использованию оператора в запросе.
Рассмотрим следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr = 123456 OR driverslicensenr = 678910 OR driverslicensenr = 345678;
Вы можете заменить оператор на:
SELECT driverslicensenr, name FROM Drivers WHERE driverslicensenr IN (123456, 678910, 345678);
Два оператора с .
Совет. Здесь вам нужно быть осторожным, и излишне не прибегать к использованию операции объединения , потому что в этом случае вы проходите одну и ту же таблицу несколько раз. С другой стороны, вы должны понимать, что при использовании в запросе время выполнения увеличивается. Альтернативой операции является переформулировка запроса таким образом, чтобы все условия были помещены в одну инструкцию или с использованием вместо .
Совет. Помните также, что, хотя и другие операторы, которые будут упомянуты в следующих разделах, вероятно, не используют индекс, индексные запросы не всегда предпочтительны!
Когда ваш запрос содержит оператор , вероятно, индекс не используется, как и для оператора . А это неизбежно замедлит выполнение вашего запроса. Если вы не понимаете, что мы подразумеваем, рассмотрите следующий запрос:
SELECT driverslicensenr, name FROM Drivers WHERE NOT (year > 1980);
Этот запрос определенно будет работать медленнее, чем вы могли бы ожидать, главным образом потому, что он сформулирован намного сложнее, чем это могло бы быть: в таких случаях, как этот, лучше искать альтернативу. Рассмотрите возможность замены операторами сравнения, такими как , или . Этот пример запроса действительно может быть переписан примерно в таком виде:
SELECT driverslicensenr, name FROM Drivers WHERE year <= 1980;
Это уже выглядит аккуратно, не так ли?
Оператор – это другой оператор, который не использует индекс и тоже может замедлить выполнение вашего запроса, особенно если он используется слишком сложным и неэффективным способом, как в примере ниже:
SELECT driverslicensenr, name FROM Drivers WHERE year >= 1960 AND year <= 1980;
Лучше переписать этот запрос и использовать оператор :
SELECT driverslicensenr, name FROM Drivers WHERE year BETWEEN 1960 AND 1980;
Кроме того, операторы и ‑ это такие операторы, с которыми нужно обращаться очень осторожно, потому что, включение их приводит к отказу от использования индекса. Альтернативными вариантами, которые могут здесь пригодится, являются функции агрегации, такие как или
Совет. В тех случаях, когда вы используете предлагаемые альтернативы, вы должны знать, что все функции агрегации, такие как , , , во многих строках, могут привести к повышению времени выполнения запроса. В этих случаях вы можете попытаться либо свести к минимуму количество строк для обработки или предварительного расчета этих значений
Здесь вы снова убеждаетесь в том, как важно знать, как можно больше о структуре своих данных, о цели запроса … когда вы принимаете решения о том, какой запрос использовать!
Также в тех случаях, когда столбец используется в вычислениях или в скалярной функции, индекс не используется. Возможное решение проблемы состоит в том, чтобы просто изолировать конкретный столбец, чтобы он больше не являлся частью операции вычисления или функции. Рассмотрим следующий пример:
SELECT driverslicensenr, name FROM Drivers WHERE year + 10 = 1980;
Это выглядит причудливо, да? Попробуйте вместо этого пересмотреть расчет и переписать запрос примерно так:
SELECT driverslicensenr, name FROM Drivers WHERE year = 1970;
Что такое язык запросов SQL?
Язык запросов sql используется программистами наиболее широко. Причиной тому является повсеместное распространение динамических веб сайтов. Как правило, такие ресурсы имеют гибкую оболочку. Но основной костяк такого сайта составляют базы данных. Если вы начинающий программист, вы просто обязаны освоить структурированный язык запросов SQL.
Зачем нужно знать язык запросов SQL?
Освоив язык запросов sql, вы с легкостью сможете писать приложения для WordPress. Это один из самых популярных блоговых движков в мире. Вы сможете писать sql запросы любой сложности, ведь писать sql запросы — это основное при изучении sql. На сайте запросы sql примеры найти не сложно, sql примеры Вы найдете в разделе SQL SELECT (запросы sql примеры).
Недавно появившийся веб ресурс sql-language.ru содержит массу информации касающейся языка запроса sql. По сути дела данный веб-сайт составляет огромный sql справочник. На сайте грамотно и в доступной форме рассмотрены запросы в sql.
Ресурс имеет раздел язык запросов sql для начинающих. Здесь вы можете получить начальные сведения о языке. Приведены основные возможности, которые будут доступны программистам на sql. В общих чертах это хранение и получение данных, их обработка и система команд. В данном разделе приведены типы команд, которые включает язык запросов sql и рассмотрено их назначение. Раздел описывающий данные входящие в язык запросов sql описывает строковые, числовые и прочие типы данных. На каждый тип приведено подробное описание и определена допустимая величина строки. Структурированный язык запросов sql предполагает аккуратное использование типов данных. Также в данном разделе содержится подробная информация по типам совместимым с Access и Oracle. Раздел привилегий языка запроса sql, расписывает как распределить или частично ограничить доступ к данным. Особенно это востребовано для веб сайтов с динамичным содержимым. Примером таких сайтов являются форумы или корпоративные сайты. Возможность редактирования отдельных данных допускается не для всех. Вот здесь то и пригодятся привилегии, которые допускает язык запросов sql. Вы сможете создать систему паролей и отсечь часть пользователей от активных действий. Раздел индексы, языка запроса sql, объясняет, как добиться максимальной производительности системы. Использование индексации позволит серверу легко и быстро находить данные. Структурированный язык запросов sql фактически создавался для этой цели. Простота и удобство в поиске данных, послужило быстрому признанию и распространению языка запроса sql. В восьмидесятых годах язык был признан стандартом для работы с базами данных. С тех пор язык запросов sql используется на большинстве серверов.
Еще один наиболее масштабный раздел сайта это команды. Пожалуй этот сектор рассмотрен на сайте sql-language.ru наиболее подробно. Как обычно, для начинающих приведена общая описательная часть о типах команд языка запроса sql. Рассмотрены такие общие типы как команды определения данных, команды языка управления, управление транзакциями и манипулирование данными. В дальнейшем, каждая из команд рассмотрена в деталях. Детально описан синтаксис команды, назначение, и конечный результат ее действия. Еще один серьезный раздел сайта посвящен условиям языка запроса sql. Здесь подробно описано как организовать обработку данных определенным образом. Возможны гибкие варианты, ограничения или исключения данных из процесса обработки.
Вся информация на сайте является абсолютно бесплатной. Сайт обладает достаточно простой навигацией. В структуре данных довольно легко ориентироваться даже неподготовленному человеку. Для новичков впервые осваивающих язык запросов sql веб сайт будет хорошим подспорьем. Оставьте закладку на sql-language.ru и вы всегда сможете найти необходимую информацию, касающуюся языка запроса sql. Для тех, кто уже сталкивался с программированием с использованием языка запроса sql, ресурс не будет лишним. Наверняка не всякий держит все тонкости языка в голове. Периодически возникают вопросы, требующие припоминания основ и деталей. Для зарегистрированных пользователей, на сайте предусмотрена возможность оставлять комментарии. Вы сможете задать вопрос, и прочитать, что по этому поводу думают другие. Удачи вам на поприще программирования.
Парсинг и компиляция запроса
Первое, что должна сделать задача, когда она начинает выполнять запрос — это понять содержимое запроса. На этом этапе SQL Server ведёт себя как виртуальная машина для интерпретируемых языков: тест запроса будет распарсен и на его основе будет построено абстрактное синтаксическое дерево. Запрос (или пакет запросов) парсится сразу и полностью весь. Если на этом этапе возникает ошибка, запрос прерывается с ошибкой компиляции (запрос при этом считается завершённым, задача выполнена и рабочий поток может приступить к следующей ожидающей задаче).
SQL и TSQL – это высокоуровневые декларативные языки с крайне сложными выражениями (представьте SELECT с несколькими JOIN’ами). Компиляция запроса не приводит к появлению ассемблерных инструкций – или даже чего-то похожего на байт-код для JVM. Вместо этого строится план обращения к данным (или план запроса). План описывает, как именно обращаться к таблицам и индексам, как искать и находить нужные строки и выполнять дальнейшие манипуляции с полученными данными. Условно, план может звучать так:
Тут же сразу важное замечание:
Многие разработчики пытаются сделать из запроса швейцарский перочинный нож, который пригодится сразу в 10 разных ситуациях. Для этого обычно используются хитрые условия в секции WHERE, часто содержащие несколько вариантов, соединённых через OR (COLUMN = @parameter OR @parameter IS NULL). Это хорошая практика для разработчиков, придерживающихся принципа DRY — и старающихся избегать дублирования кода. Но в случае SQL-запросов это выливается в большие проблемы. Компиляция должна завершиться с планом, который будет приемлемым для каждой из 10 ситуаций, для которых предназначен такой запрос. Это значит, что план скорее всего будет хуже, чем 10 планов, подобранных для каждой из ситуаций по отдельности
Если вы следите за чистотой клиентского кода, рекомендую обратить внимание на приёмы динамического SQL
Подзапросы SQL-примеры
В этом разделе мы рассмотрим, как использовать подзапросы. У нас есть следующие две таблицы: ‘student‘ и ‘marks‘ с общим полем ‘StudentID‘:
студенты
отметки
Теперь нужно составить запрос, определяющий всех студентов, которые получают лучшие отметки, чем студент со StudentID — «V002». Но мы не знаем отметок студента «V002».
Поэтому нужно составить два SQL подзапроса в Select. Один запрос возвращает отметки (хранятся в поле «Total_marks») для «V002», а второй запрос выбирает учеников, которые получают лучшие оценки, чем результат первого запроса.
Первый запрос:
SELECT * FROM `marks` WHERE studentid = 'V002';
Результат запроса:
Результатом запроса будет 80.
Используя результат этого запроса, мы написали еще один запрос, чтобы определить учеников, которые получают оценки лучше, чем 80.
Второй запрос:
SELECT a.studentid, a.name, b.total_marks FROM student a, marks b WHERE a.studentid = b.studentid AND b.total_marks >80;
Результат запроса:
Два приведенных запроса определяют студентов, которые получают лучше оценки, чем студент StudentID «V002» (Abhay).
Можно объединить эти два запроса, вложив один запрос в другой. Подзапрос — это запрос внутри круглых скобок. Рассмотрим подзапроса в SQL пример:
Код SQL:
SELECT a.studentid, a.name, b.total_marks FROM student a, marks b WHERE a.studentid = b.studentid AND b.total_marks > (SELECT total_marks FROM marks WHERE studentid = 'V002');
Результат запроса:
Графическое представление подзапроса SQL:
Сравнение данных за две даты
Хотя данная статистика из рода задач довольно редко встречаемых, но все-таки необходимость в ее получении иногда существует. И получить такую статистику ничуть не сложнее других.
Работать мы будем с двумя таблицами, структура которых представлена ниже:
Структура таблицы products
CREATE TABLE IF NOT EXISTS `products` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ShopID` int(11) NOT NULL, `Name` varchar(150) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=MyISAM DEFAULT CHARSET=utf-8 AUTO_INCREMENT=10 ;
Структура таблицы statistics
CREATE TABLE IF NOT EXISTS `statistics` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ProductID` bigint(20) NOT NULL, `Orders` int(11) NOT NULL, `Date` date NOT NULL DEFAULT '0000-00-00', PRIMARY KEY (`id`), KEY `ProductID` (`ProductID`) ) ENGINE=MyISAM DEFAULT CHARSET=utf-8 AUTO_INCREMENT=20 ;
Дело в том, что стандарт языка SQL допускает использование вложенных запросов везде, где разрешается использование ссылок на таблицы. Здесь вместо явно указанных таблиц, благодаря использованию псевдонимов, будут применяться результирующие таблицы вложенных запросов с имеющейся связью один – к – одному. Результатом каждой результирующей таблицы будут данные о количестве произведенных заказов некоего товара за определенную дату, полученные путем выполнения запроса на выборку данных из таблицы statistics по требуемым критериям. Иными словами мы свяжем таблицу statistics саму с собой. Пример запроса:
SELECT stat1.Name, stat1.Orders, stat1.Date, stat2.Orders, stat2.Date FROM (SELECT statistics.ProductID, products.Name, statistics.Orders, statistics.Date FROM products JOIN statistics ON products.id = statistics.ProductID WHERE DATE(statistics.date) = '2014-09-04') AS stat1 JOIN (SELECT statistics.ProductID, statistics.Orders, statistics.Date FROM statistics WHERE DATE(statistics.date) = '2014-09-12') AS stat2 ON stat1.ProductID = stat2.ProductID
В итоге имеем такой результат:
+------------------------+----------+------------+----------+------------+ | Name | Orders1 | Date1 | Orders2 | Date2 | +------------------------+----------+------------+----------+------------+ | Процессоры Pentium II | 1 | 2014-09-04 | 1 | 2014-09-12 | | Процессоры Pentium III | 1 | 2014-09-04 | 10 | 2014-09-12 | | Оптическая мышь Atech | 10 | 2014-09-04 | 3 | 2014-09-12 | | DVD-R | 2 | 2014-09-04 | 5 | 2014-09-12 | | DVD-RW | 22 | 2014-09-04 | 18 | 2014-09-12 | | Клавиатура MS 101 | 5 | 2014-09-04 | 1 | 2014-09-12 | | SDRAM II | 26 | 2014-09-04 | 12 | 2014-09-12 | | Flash RAM 8Gb | 8 | 2014-09-04 | 7 | 2014-09-12 | | Flash RAM 4Gb | 18 | 2014-09-04 | 30 | 2014-09-12 | +------------------------+----------+------------+----------+------------+