Что такое postgresql? плюсы и минусы бесплатной базы данных
Содержание:
- Преимущества и особенности СУБД PostgreSQL
- Вопросы
- Часто встречающиеся ошибки 1С и общие способы их решения Промо
- macOS GUI Clients
- 1.1. Предыстория
- 2. Postgres: общие сведения
- Оператор SELECT
- Производительность
- Установка PostgreSQL
- Кому надо переходить на Postgres
- Резюме
- Типы данных
- Базы данных и шаблоны
- Принцип работы
- Базовая статистика
Преимущества и особенности СУБД PostgreSQL
СУБД PostgreSQL использует для своих баз данных реляционную модель, поддерживая стандартный язык запросов SQL. При этом PostgreSQL предоставляет широкий спектр возможностей. Можно сказать, что Postgres обладает почти всеми возможностями, существующими в других базах данных (как коммерческих, так и Open Source), а также рядом дополнительных.
Сегодня СУБД PostgreSQL работает почти на всех UNIX-платформах, в том числе и на UNIX-подобных системах (FreeBSD и Linux). Вы сможете использовать эту базу данных и на Windows NT Server, и на Windows 2000 Server, и для разработки рабочих станций ME.
Рассмотрим краткий перечень преимуществ и функциональных возможностей СУБД PostgreSQL:
1. Надежность. Надёжность СУБД PostgreSQL проверена и доказана. Она обеспечивается соответствием принципам ACID (атомарность, изолированность, непротиворечивость, сохранность данных), многоверсионностью, наличием Write Ahead Logging (WAL) — общепринятого механизма протоколирования всех существующих транзакций. Сюда же стоит отнести и возможность восстановления базы данных Point in Time Recovery (PITR), репликацию, поддержку целостности данных на уровне схемы.
2. Производительность. В СУБД PostgreSQL она основана на применении индексов, наличии гибкой системы блокировок и интеллектуального планировщика запросов, использовании системы управления буферами памяти и кэширования. Не стоит забывать и про отличную масштабируемость при конкурентной работе.
3. Расширяемость. Для СУБД PostgreSQL это означает, что пользователь может настроить систему посредством определения новых функций, типов, языков, агрегатов, индексов и операторов. А объектная ориентированность СУБД PostgreSQL даёт возможность переносить логику приложения на уровень базы данных, а это, в свою очередь, заметно упрощает разработку клиентов, ведь вся бизнес-логика находится в БД. При этом функции в Postgres однозначно определяются названием, типами и числом аргументов.
4. Поддержка SQL. Её уже упоминали, однако кроме главных возможностей, которые присущи любой SQL-базе, PostgreSQL поддерживает схемы, подзапросы, внешние связки, правила, курсоры, наследование таблиц, триггеры и много чего ещё.
5. Поддержка многочисленных типов данных. СУБД PostgreSQL поддерживает численные (целые, денежные, с фиксированной/плавающей точкой), булевые, символьные, составные, сетевые типы данных, а также перечисление, типы «дата/время», геометрические примитивы, массивы, XML- и JSON-данные. Плюс можно создавать свои типы данных.
Конечно, это далеко не всё, но для общего понимания возможностей СУБД PostgreSQL вполне достаточно. Естественно, база данных заслуживает внимания, особенно если учесть, что она имеет открытый исходный код и распространяется свободно. Освоить эту СУБД вы cможете на курсе в OTUS.
Вопросы
Насколько полезна сертификация на Postgres, что она дает?
Сертификация очень полезна, дает почти то же самое, что сертификация на 1С:Эксперта в фирме «1С». Вы вроде и так все знаете без сертификатов, но ваш путь поиска проблем, когда они возникнут, очень долгий, поскольку он неправильный, он идет не так. А тут учат именно структурированию – как правильно искать, что где искать, как пользоваться инструментами, которые дают гораздо более быстрый результат, чем те, к которым вы привыкли. Поэтому крайне полезно. Фактически, это некий чек-лист и список инструментов, который можно использовать. При том, что подготовка к сертификации – это просмотр бесплатных видео, которые у них на сайте лежат. Просматривайте видео, выполняете задания, которые там даны, и вперед на сертификацию.
Дает ли возможность 1С перенести базу с MS SQL на PostgreSQL?
Конечно, выгружаем в dt-ник и загружаем. Если база очень большая, нужно просто посмотреть, что там лежит. Я не удивлюсь, что это вложенные файлы — уберите их из БД на дисковые тома Есть ещё лайфхак – почистите итоги перед переносом в dt-ник (truncate таблиц итогов на СУБД — делать только если точно понимаешь что делаешь). А после того, как вы загрузили в dt-ник, посчитайте их заново. Заодно порядок в итогах наведете. Тем более, что в платформе 8.3.18 включили многопоточный расчет итогов.
*************
Данная статья написана по итогам доклада (видео), прочитанного на онлайн-митапе «PostgreSQL VS Microsoft SQL». Больше статей можно прочитать здесь.
Часто встречающиеся ошибки 1С и общие способы их решения Промо
Статья рассчитана в первую очередь на тех, кто недостаточно много работал с 1С и не успел набить шишек при встрече с часто встречающимися ошибками. Обычно можно определить для себя несколько действий благодаря которым можно определить решится ли проблема за несколько минут или же потребует дополнительного анализа. В первое время сталкиваясь с простыми ошибками тратил уйму времени на то, чтобы с ними разобраться. Конечно, интернет сильно помогает в таких вопросах, но не всегда есть возможность им воспользоваться. Поэтому надеюсь, что эта статья поможет кому-нибудь сэкономить время.
macOS GUI Clients
Clients compatible with only OS X.
SQLPro for Postgres
macOS 10.8 and above
Features:
- 100% native OS X app with a clean and simple to use interface.
- Query editor with syntax highlighting and autocomplete.
- Support for multiple result set execution.
- History feature, displaying your last ten executed queries.
- Primary key detection for inline result set modifications.
- Custom theme support allowing developers to work with style.
TablePlus
A modern, native tool with an elegant UI that allows you to simultaneously manage multiple databases, including PostgreSQL. Available on macOS, Windows, and iOS.
True native built.
Workspace supports multiple tabs, multiple windows
Powerful SQL editor with full features: auto syntax highlight, auto-suggestion, split pane, favorite and history.
Data Filter & Sorting, import & export
Full-dark theme & modern shortcut
With plugin system, you can be able to write your own new features to work with database per your needs (export charts, pretty json…).
Postico
Postico is a fully native Mac app for connecting to your PostgreSQL server. It supports encrypted connections via SSL and SSH to PostgreSQL 8.0 and later, including Amazon Redshift.
Postico has a powerful table content editor with in-cell editing and form-based row editing in a sidebar. You can quickly filter tables by keywords or even complex SQL expressions.
There’s also a table structure editor for editing columns, types, default values, foreign keys, check constraints etc.
Finally, there’s a convenient SQL Query Editor with support for query history and syntax highlighting. It also has convenience features like auto-indent and shortcuts for comment line etc.
SEQUEL for PostgreSQL
SEQUEL for PostgreSQL is a professional DB administration and management tool, with extremely intuitive and feature-rich GUI that makes it the best assistant tool for developers and admins. SEQUEL is lightweight, fast and powerful that it can significantly simplify the DB management process. For those who cannot live without a CLI, SEQUEL offers a powerful Query Editor with syntax highlight, autocomplete and a Console log view that is always visible, so you can monitor the communication with your databases. It includes:
- Database management forms for Schema, Table, Index, Foreign key, Trigger, Rule, Sequence, Collation, Domain, Enum type, Tablespace and Language objects with full parameters support
- Assistant info views for Object information, Actions, Help, and Documentation
- Jump bar for quick objects selection and navigation
- Taskbar with multi-task monitoring support
- Console log view
- Syntax highlight, autocomplete, current and selection query execution and explain, line numbering and working statement detection
- Direct editing in the results view, query results explanation
- Powerful Field editor
- Transaction based database updates
- Code preview and Content editing
1.1. Предыстория
2. Postgres: общие сведения
†
- Поддержка АТД в системе баз данных
- Сложные объекты (т. е. вложенные данные или данные не первой нормальной формы (non-first-normal form — NF2))*
- Пользовательские абстрактные типы данных и функции*
- Расширяемые методы доступа для новых типов данных*
- Оптимизированная обработка запросов с дорогостоящими пользовательскими функциями
- Активные базы данных и системы правил (триггеры, предупреждения)*
- Правила, реализованные в виде перезаписи запроса†
- Правила, реализованные как триггеры уровня записи†
- Хранение и восстановление на основе журнала
- Код восстановления с уменьшенной сложностью, рассматривающий журнал как данные*, использование энергонезависимой памяти для состояния фиксации†
- Хранилище без перезаписи и темпоральные запросы†
- Поддержка новых технологий глубокого хранения данных, в особенности оптических дисков*
- Поддержка мультипроцессоров и специализированных процессоров*
- Поддержка различных языковых моделей
- Минимальные изменения реляционной модели и поддержка декларативных запросов*
- Доступ к «быстрому пути» из внутренних API в обход языка запросов†
- Многоязычность†
Оператор SELECT
Как упоминалось в начале статьи, SQL-запросы почти всегда начинаются с оператора SELECT. SELECT в запросах указывает, какие столбцы из таблицы должны нужно вернуть в наборе результатов. Запросы также почти всегда включают оператор FROM, который используется для указания таблицы, к которой нужно обратиться.
В общем SQL-запросы следуют такому синтаксису:
Например, чтобы извлечь столбец name из таблицы dinners, нужен такой запрос:
Вы также можете запрашивать несколько столбцов из одной таблицы, отделив их заголовки запятыми.
Вместо того чтобы называть конкретный столбец или набор столбцов, вы можете использовать оператор SELECT со звездочкой (*) – она служит заполнителем, представляющим все столбцы в таблице. Следующая команда отобразит все столбцы таблицы tourneys:
WHERE используется в запросах для фильтрации записей, которые удовлетворяют указанному условию. Все строки, которые не удовлетворяют этому условию, исключаются из результата. Оператор WHERE обычно использует следующий синтаксис:
Оператор сравнения в выражении WHERE определяет способ сравнения указанного столбца со значением. Вот некоторые распространенные операторы сравнения SQL:
| Оператор | Действие |
| = | Равно |
| != | Не равно |
| < | Меньше, чем |
| > | Больше, чем |
| <= | Меньше или равно |
| >= | Больше или равно |
| BETWEEN | проверяет, находится ли значение в заданном диапазоне |
| IN | проверяет, содержится ли значение строки в наборе указанных значений |
| EXISTS | проверяет, существуют ли строки при заданных условиях |
| LIKE | проверяет, соответствует ли значение указанной строке |
| IS NULL | Проверяет значения NULL |
| IS NOT NULL | Проверяет все значения, кроме NULL |
Например, если вы хотите узнать размер обуви Ирмы, вы можете использовать следующий запрос:
SQL позволяет использовать подстановочных знаков, и это особенно удобно при работе с выражениями WHERE. Знак процента (%) представляют ноль или более неизвестных символов, а подчеркивания (_) представляют один неизвестный символ. Они полезны, если вы пытаетесь найти конкретную запись в таблице, но не знаете точно, что это за запись. Чтобы проиллюстрировать это, предположим, что вы забыли любимое блюдо нескольких своих подруг, но вы уверены, что это блюдо начинается на t. Вы можете найти его название с помощью запроса:
Исходя из вышеприведенного вывода, это tofu.
Иногда приходится работать с базами данных, в которых есть столбцы или таблицы с относительно длинными или трудно читаемыми названиями. В этих случаях вы можете сделать эти имена более читабельными, создав псевдонимы – для этого есть ключевое слово AS. Псевдонимы, созданные с помощью AS, являются временными (они существуют только на время запроса, для которого они созданы):
Как видите, теперь SQL отображает столбец name как n, столбец birthdate как b и dessert как d.
На данный момент мы рассмотрели некоторые наиболее часто используемые ключевые слова и предложения в запросах SQL. Они полезны для базовых запросов, но они не помогут, если вам нужно выполнить вычисление или получить скалярное значение (одно значение, а не набор из нескольких различных значений) на основе ваших данных. Здесь вам понадобятся агрегатные функции.
Производительность
Базы данных должны обязательно быть оптимизированы для окружения, в котором вы будете работать. Исторически так сложилось что MySQL ориентировалась на максимальную производительность, а Postgresql разрабатывалась как база данных с большим количеством настроек и максимально соответствующую стандарту. Но со временем Postgresql получил много улучшений и оптимизаций.
MySQL
В большинстве случаев для организации работы с базой данных в MySQL используется таблица InnoDB, эта таблица представляет из себя B-дерево с индексами. Индексы позволяют очень быстро получить данные из диска, и для этого будет нужно меньше дисковых операций. Но сканирование дерева требует нахождения двух индексов, а это уже медленно. Все это значит что MySQL будет быстрее Postgresql только при использовании первичного ключа.
Postgresql
Вся заголовочная информация таблиц Postgresql находится в оперативной памяти. Вы не можете создать таблицу, которая будет не в памяти. Записи таблицы сортируются по индексу, а поэтому вы можете их очень быстро извлечь. Для большего удобства вы можете применять несколько индексов к одной таблице.
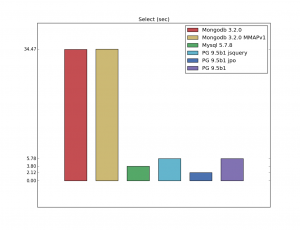
В целом PostgreSQL работает быстрее, за исключениям использования первичных ключей. Давайте рассмотрим несколько тестов с различными операциями:
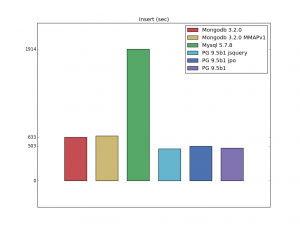
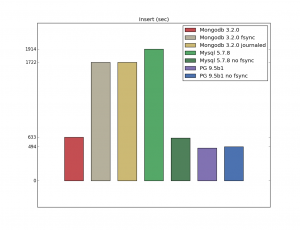
Установка PostgreSQL
Я достаточно долго думал над вопросом, какую систему управления базами данных (СУБД) выбрать для своих статей и решил остановиться на PostgreSQL.
Выбор обусловлен несколькими причинам:
- Бесплатная СУБД
- Простота установки.
- Поддержка основных операционных систем
- Удобная програма pgAdmin для работы с базами
- Это современная СУБД с хорошими возможностями
В принципе в JDK есть встроенная база данных — Derby. Но пользоваться ей, на мой взгляд, очень неудобно. MySQL в общем тоже неплохо, но в нем достаточно неудобная утилита для ввода команд. Остальные базы либо платные, либо малоизвестные. Само собой, после прочтения моих статей вам никто не мешает попробовать поработать с этими базами данных самостоятельно.
Загрузить нужную версию PostgreSQL можно с этой страницы: Download PostgreSQL.
На данный момент я использовал версию 9.5.2. Какая версия будет на момент чтения статьи вами — не знаю. Но надеюсь, что в ближайшие годы что-то кардинально не поменяется.
Будьте внимательны — загружайте версию для вашей операционной системы. Дальше запускаете установку. По экранам она выглядит вот так.
На втором экране вам надо выбрать директорию для установки. Я не рекомендую устанавливать в каталог “Program Files” по умолчанию, т.к. на Windows серверных платформ это бывает чревато. На домашних системах скорее всего проблем не будет, но как говорится, “обэегшись на молоке, дуешь на воду”. Посему я обычно ставлю директорию “C:\PostgreSQL\”
Далее вам предложат дирекотрию для хранения файлов для баз данных — оставляйте как есть.
На следующем экране вам надо ввести парль для пользователя “postgres”. Для разработки я выбираю такой же пароль: “postgres”.
На следующем экране запрашивается порт, на котором будет “висеть” PostgreSQL. Если у вас не установлен PostgreSQL, то можно оставить по умолчанию “5432”.
Локализацию можно оставить как есть. Кому интересно, может выбрать что-нибудь конкретное. Я в принципе проблем не имел при выборе по-умолчанию.
Запускаем установку …
и ждем, пока она закончится.
По окончанию вам предложат установить дополнительную утилиты Stack Builder — я ее обычно не ставлю, так что “галочку” можно снять и нажать “Finish”.
В общем установка закончилась. Теперь в списке сервисов Windows можно увидеть PostgreSQL
Я нередко устанавливаю ручной запуск сервиса, но это уже как вам будет удобно.
Осталось только узнать, что в комплекте PostgreSQL устанавливается весьма удобная и легко понятная программа для управления СУБД — pgAdmin III. Ее можно найти в стартовом меню Windows (если вы работаете под другой ОС — поищите, наверняка найдете).
Запускайте и дальше все достаточно просто.
Кликаем дважды на PostgreSQL 9.5 слева — вас могу попросить ввести пароль.
Дальше вы увидите слева струткуру вашей СУБД.
Открываем слева раздел “Базы данных” и видим уже заранее созданную базу “postgres”.
Щелкните правой кнопкой мыши на пункте “Базы данных” и в выпадающем меню выберите “Новая база данных…”. Появится форма для ввода — для начала достаточно ввести имя базы данных — я назвал ее “contactdb”
Выделите мышкой вновь созданную базу данных и получите возможность делать с ней, что хотите.
Для запуска команд вам надо открыть SQL-редактор. Проще всего — нажать кнопку на верхней панели.
В открытом окне можно набирать команды SQL.
В общем все готово. Мы можем запускать SQL-скрипт, который создаст нужную нам таблицу для контактов и вставит туда тестовые данные.
Для создания необходимых нам данных SQL-скрипт выглядит вот так:
DROP TABLE IF EXISTS JC_CONTACT;
SELECT * from JC_CONTACT;
|
1 |
DROP TABLE IFEXISTS JC_CONTACT; CREATE TABLE JC_CONTACT ( CONTACT_ID SERIAL, FIRST_NAME VARCHAR(50)NOTNULL, LAST_NAME VARCHAR(50)NOTNULL, PHONE VARCHAR(50)NOTNULL, EMAIL VARCHAR(50)NOTNULL, PRIMARY KEY(CONTACT_ID) ); INSERT INTO JC_CONTACT(FIRST_NAME,LAST_NAME,PHONE,EMAIL)VALUES(‘Peter’,’Belgy’,’+79112345678′,’peter@pisem.net’); INSERT INTO JC_CONTACT(FIRST_NAME,LAST_NAME,PHONE,EMAIL)VALUES(‘Helga’,’Forte’,’+79118765432′,’helga@pisem.net’); SELECT *from JC_CONTACT; |
Кому надо переходить на Postgres

И теперь, наверное, самое важное: кому точно надо переходить на Postgres?
-
Если у вас проходит новая инсталляция продуктовой системы. Если вы ставите новую систему, я бы рекомендовал перейти хотя бы на бесплатный Postgres. Рекомендую сразу это делать на Linux. Можно и на Windows, но тут проблема не столько в том, что Postgres плохой или Windows плохой – плохо работает их связка в части файловой системы. Опять же из-за наших структур баз данных, где у нас по 30 тыс. элементов в одной таблице (7 тыс. таблиц, 25 тыс. индексов). С таким количеством файлов винда работает плохо, а Postgres хранит каждый элемент системы в отдельном файле – более того, он эти файлы разбивает по 1 Гб, для каждого файла есть отдельные служебные файлы. И так на одну базу может получиться 100-300 тысяч файлов. Когда заходишь в папку, а там 300 тыс. файлов, можете оценить скорость этой работы. Linux же с этим работает прекрасно. Поэтому, если у вас новая инсталляция продукта, надо пробовать Postgres на Linux.
-
Разработчикам 1С. В идеале, на всех ваших ноутбуках и рабочих ПК должен стоять бесплатный Postgres. И вы в идеале должны разворачивать себе клиент-серверную систему 1С. Да, возникнут вопросы, что серверные ключи для 1С дорогие. Ну купите мини-сервер на пять пользователей за 15 тыс. рублей. Почему надо? Очень часто сталкиваемся с тем, что разрабатываете вы для клиент-серверной системы. а разработка идет в файловой системе. А потом начинается… Так что разрабатывать надо на такой же системе, в которой планируете работать.
-
Если вы делаете переход с файловой. До этого мы обсуждали, что переходить на бесплатный Express бессмысленно, поскольку у вас база не влезет. Если вы разрабатываете базу с объемом в 100 Гб, и вам нужны данные для разработки, то переход на Express бессмысленен. На Postgres переходите и работаете – в том числе и на бесплатный.
-
Если вы работаете под Минкомсвязью, вам нужно брать ПО только из реестра Минкомсвязи – вам переход на PostgreSQL, причем только платный Postgres Pro. Других вариантов нет.
-
Причина, по которой в свое время моя команда перешла на Postgres – потому что я был смелый и любознательный патриот. Мы решили попробовать, реально ли наши умеют писать СУБД. Оказалось, умеют и круто. Более того, работать с техподдержкой Postgres Pro – одно удовольствие. Все люди говорят на русском, работают круглосуточно, подключаются быстро. Я такой техподдержки до сих пор ни у кого не видел. Кто хоть раз писал на v8@1c.ru знают, какой может быть техподдержка на русском языке. А это прямо небо и земля.
Но обычно у тех, кому надо переходить на PostgreSQL, у тех и не особо болит после перехода. А кому на Postgres не надо, но они переходят – те потом начинают говорить, что ничего не работает. Ну да, если ты не готов, то, наверное, и не работает.
Резюме
Ну и резюмируем, все что мы имеем в последней версии postgres_exporter 0.8.0. В основном, все улучшения касаются работы мониторинга нескольких экземпляров и/или нескольких БД в экземпляре.
- Аргумент exclude-databases (появился в 0.6.0) позволяет исключать базы данных из списка БД по которым будет производится сбор метрик. Но нельзя исключить БД которая указана в URI-подключения, так как она является мастер-базой;
- Появилась возможность использовать пользовательские запросы к глобальным представления (pg_stat_activity, pg_stat_database и т.п.) вместе с аргументом auto-discover-databases. Для этого, было добавлено дополнительное поле master, указывающее на то, что запрос должен выполняться только в мастер-базе;
- Появилась возможность использовать метрики по-умолчанию совместно с аргументом auto-discover-databases;
- Для пользовательских запросов, было добавлено поле cache_seconds, позволяет задавать время (в секундах) на которое будет за кэширован ответ сервера на соответствующий запрос.
Типы данных
Один из основных моментов обоих баз данных это поддерживаемые типы данных, которые вы можете использовать. Поскольку оба решения пытаются соответствовать синтаксису SQL, то они имеют похожие наборы, но все же кое-чем отличаются.
MySQL
MySQL поддерживает такие типы данных:
- TINYINT: очень маленькое целое.;
- SMALLINT: маленькое целое;
- MEDIUMINT: целое среднего размера;
- INT: целое нормального размера;
- BIGINT: большое целое;
- FLOAT: знаковое число с плавающей запятой одинарной точности;
- DOUBLE, DOUBLE PRECISION, REAL: знаковое число с плавающей запятой двойной точности
- DECIMAL, NUMERIC: знаковое число с плавающей запятой;
- DATE: дата;DATETIME: комбинация даты и времени;
- TIMESTAMP: отметка времени;
- TIME: время;YEAR: год в формате YY или YYYY;
- CHAR: строка фиксированного размера, дополняемая справа пробелами до максимальной длины;
- VARCHAR: строка переменной длины;
- TINYBLOB, TINYTEXT: двоичные или текстовые данные максимальной длиной 255 символов;
- BLOB, TEXT: двоичные или текстовые данные максимальной длиной 65535 символов;
- MEDIUMBLOB, MEDIUMTEXT: текст или двоичные данные;
- LONGBLOB, LONGTEXT: текст или двоичные максимальной данные длиной 4294967295 символов;
- ENUM: перечисление;
- SET: множества.
Postgresql
Поддерживаемые типы полей в Postgresql достаточно сильно отличаются, но позволяют записывать точно те же данные:
- bigint: знаковое 8-байтовое целое;
- bigserial: автоматически увеличиваемое 8-байтовое целое;
- bit: двоичная строка фиксированной длины;
- bit varying: двоичная строка переменной длины;
- boolean: флаг;
- box: прямоугольник на плоскости;
- byte: бинарные данные;
- character varying: строка символов фиксированной длины;
- character: строка символов переменной длины;
- cidr: сетевой адрес IPv4 или IPv6;
- circle: круг на плоскости;
- date: дата в календаре;
- double precision: число с плавающей запятой двойной точности;
- inet: адрес интернет IPv4 или IPv6;
- integer: знаковое 4-байтное целое число;
- interval: временной промежуток;
- line: бесконечная прямая на плоскости;
- lseg: отрезок на плоскости;
- macaddr: MAC-адрес;
- money: денежная величина;
- path: геометрический путь на плоскости;
- point: геометрическая точка на плоскости;
- polygon: многоугольник на плоскости;
- real: число с плавающей точкой одинарной точности;
- smallint: двухбайтовое целое число;
- serial: автоматически увеличиваемое четырехбитное целое число;
- text: строка символов переменной длины;
- time: время суток;
- timestamp: дата и время;
- tsquery: запрос текстового поиска;
- tsvector: документ текстового поиска;
- uuid: уникальный идентификатор;
- xml: XML-данные.
Как видите, типов данных в Postgresql больше и они более разнообразны, есть свои типы полей для определенных видов данных, которых нет MySQL. Отличие MySQL от Postgresql очевидно.
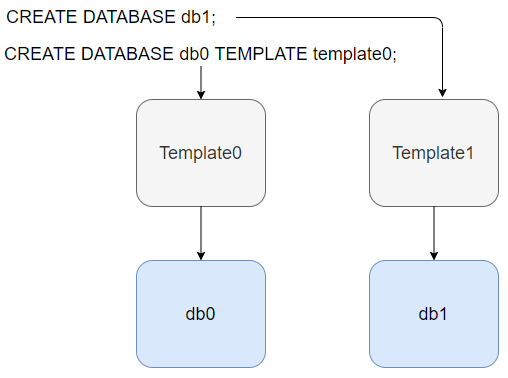
Базы данных и шаблоны
Когда мы создаём новые кластер командой у нас создается 3 одинаковые базы данных:
- postgres
- template0
- template1
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 |
template0 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
База postgres используется, чтобы по умолчанию к ней подключаться. Принципиально она не нужна, но есть приложения которым она может понадобится, поэтому лучше её не удалять.
Две дополнительные базы template0 и template1 – это шаблоны. Новая база всегда создается путём копирования из другой шаблонной базы. По умолчанию для шаблона используется база template1. Поэтому, если у вас есть расширения, которыми вы пользуетесь, можете их заранее создать в template1.
Основная задача базы template0 заключается в том, что бы она никогда не менялась. Она используется, например при загрузке базы из дампа. Вначале вы создаёте базу из template0, а затем туда заливаете сохранённый дамп. Также база template0 позволяет создавать базы с использованием категорий локалей не по умолчанию (LC_COLLATE, LC_CTYPE).
Принцип работы
Для нужно выбрать:
- имя;
- регион;
- версию СУБД;
- конфигурацию нод;
- количество реплик, если кластер отказоустойчивый;
- подсеть, в которой будет создан кластер.
После запуска процесса создания в интерфейсе отобразится новый кластер. Все возможности по управлению кластером находятся на его странице, которая станет доступна после перехода кластера в статус Active.
Пользователям для работы доступен только сам кластер — доступа к нодам кластера нет, так как они находятся на стороне Selectel.
Внутри кластера находится вся функциональность по управлению. На странице кластера можно создавать базы данных, пользователей, назначать права доступа и масштабировать кластер.
Адреса серверов и подсеть, к которой подключен кластер, менять нельзя.
После создания кластера нужно и . Затем необходимо назначить пользователям права доступа на базы данных. В кластере можно создать до 50 баз данных и до 50 пользователей, все имена должны быть уникальными.
При подключении к кластеру нужно указать имя базы данных, имя пользователя, пароль, а также порт и адреса кластера. Подробнее о подключении к кластеру.
У всех пользователей в кластере одинаковые права.
Базовая статистика
Базовая статистика уровня отношения хранится в системном каталоге в таблице . К ней относятся:
-
число строк в отношении ();
-
размер отношения в страницах ();
-
количество страниц, отмеченных в карте видимости ().
Значение используется в качестве оценки кардинальности, когда запрос не содержит никаких условий на таблицу:
Статистика собирается при анализе, ручном или автоматическом
Но, ввиду особой важности, базовая статистика рассчитывается также при выполнении некоторых операций ( и , и ), и уточняется при очистке
Для анализа случайно выбираются 300 × default_statistics_target строк (при значении параметра по умолчанию 100 получается 30000). Поскольку размер выборки, достаточной для построения статистики заданной точности, слабо зависит от объема анализируемых данных, размер таблицы не учитывается.
Строки выбираются из такого же количества (300 × default_statistics_target) случайных страниц. Конечно, для небольшой таблицы количество прочитанных страниц и выбранных для анализа строк может оказаться меньше.
Поскольку в достаточно больших таблицах статистика собирается не по всем строкам, оценки могут немного расходиться с реальностью. Это нормально: статистика в любом случае не может все время быть точной, если данные изменяются. Для выбора адекватного плана обычно достаточно попадания в порядок.
Создадим копию таблицы с отключенной автоочисткой, чтобы управлять временем выполнения анализа:
Для новой таблицы еще нет никакой статистики:
Значение = −1 (появившееся в версии PostgreSQL 14) позволяет отличить таблицу, для которой статистика ни разу не собиралась, от действительно пустой таблицы без строк.
Но с большой вероятностью в таблицу будут добавлены какие-то строки сразу после создания. Поэтому, находясь в неведении, планировщик считает, что таблица занимает 10 страниц:
Количество строк (rows) рассчитывается исходя из размера одной строки; он отображается в плане запроса как width. Обычно для оценки используется среднее значение, вычисляемое при анализе, но в данном случае, поскольку статистика отсутствует, размер строки вычисляется приблизительно с учетом типов данных столбцов.
Теперь скопируем данные из таблицы и выполним анализ:
Сейчас статистика совпадает с реальным количеством строк (размер таблицы таков, что статистика собирается по полным данным):
Значение обновляется при очистке:
Оно используется при оценке стоимости сканирования только индекса.
Теперь удвоим количество строк, не собирая статистику, и проверим оценку кардинальности в плане запроса:
Оценка оказалась точна, несмотря на устаревшие сведения в :
Дело в том, что планировщик повышает точность оценки, масштабируя значение reltuples в соответствии с отклонением реального размера файла данных от значения . Поскольку размер файла вырос в два раза по сравнению с , количество строк корректируется в предположении, что плотность данных не изменилась:
Конечно, такая корректировка работает не всегда (например, если удалить часть строк, то оценка не изменится), но в ряде случаев позволяет «продержаться» до прихода анализа при крупных изменениях.