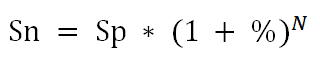Коэффициент корреляции: что нужно знать, формула, пример расчёта в excel
Содержание:
Коэффициент корреляции и ПАММ-счета
С расчётом корреляции я как студент экономического ВУЗа познакомился еще на втором курсе
Тем не менее, долгое время недооценивал важность расчёта корреляции именно для подбора ПАММ-портфеля. 2018 год очень четко показал, что ПАММ-счета с похожими стратегиями в случае кризиса могут вести себя очень похоже
Случилось так, что с середины года отказала не просто одна стратегия управляющего, а большинство торговых систем, завязанных на активные движения валютной пары EUR/USD:
Рынок был для каждого управляющего по-своему неблагоприятным, но присутствие их всех в портфеле привело к большой просадке. Совпадение? Не совсем, ведь это были ПАММ-счета с похожими элементами в торговых стратегиях. Без опыта торговли на рынке Форекс может быть сложно понять, как это работает, но по корреляционной таблице степень взаимосвязи видна и так:
Мы ранее рассматривали корреляцию вплоть до +1, но как видите на практике даже совпадение в районе 20-30% уже говорит о некоторой схожести ПАММ-счетов и, как следствие, результатов торговли.
Чтобы снизить шансы на повторение ситуации, как в 2018 году, я считаю в портфель стоит подбирать ПАММ-счета с низкой взаимной корреляцией. По сути, нам нужны уникальные стратегии с разными подходами и разными валютными парами для торговли. На практике, конечно, сложнее подобрать прибыльные счета с уникальными стратегиями, но если хорошо покопаться в рейтинге ПАММ-счетов, то все возможно. К тому же, низкая взаимная корреляция снижает требования для диверсификации, 5-6 счетов вполне хватит.
Пару слов о расчёте коэффициента корреляции для ПАММ-счетов. Достать сами данные относительно несложно, в Альпари прямо с сайта, для остальных площадок через сайт investflow.ru. Однако с ними нужно сделать небольшие преобразования.
Данные о прибыльности ПАММов изначально хранятся в формате накопленной доходности, нам это не подходит. Корреляция стандартных графиков доходности двух прибыльных ПАММ-счетов всегда будет очень высокой, просто потому что они все движутся в правый верхний угол:
У всех счетов положительная корреляция от 0.5 и выше за редким исключением, так мы ничего не поймем. Реальное сходство стратегий ПАММ-счетов можно увидеть только по дневным доходностям. Рассчитать их не особо сложно, если знаете нужные формулы доходности. Если прибыль или убыток двух ПАММ-счетов совпадают по дням и по процентам, высока вероятность что их стратегии имеют общие элементы — и коэффициент корреляции нам это покажет:
Как видите, некоторые корреляции стали нулевыми, а некоторые остались на высоком уровне. Мы теперь видим, какие ПАММ-счета действительно похожи между собой, а какие не имеют ничего общего.
Напоследок давайте разберёмся, что делать и как посчитать корреляцию, если у вас появилась в этом необходимость.
Как проводится корреляционный анализ в Excel
Суть данного анализа сводится к выявлению зависимостей между различными факторами, представленными в таблицах. Таким образом можно определить как повлияет уменьшение или увеличение определенных показателей на исследуемые данные.
Если была выявлена зависимость, то определяется уже коэффициент корреляции. Коэффициент будет варьироваться в значениях от -1 до +1. При положительной корреляции, увеличение одного показателя повлечет за собой увеличение другого. Соответственно при отрицательной будет уменьшение. Чем больше значение корреляции, тем сильнее оказываемое влияние.
Для примера возьмем таблицу, где представлена прямая зависимость одних показателей от других. Например, зарплата сотрудников и величина прибыли компании. Далее рассмотрим два способа реализации корреляционного анализа на примере этой таблицы.
Вариант 1: Вызов через Мастер функций
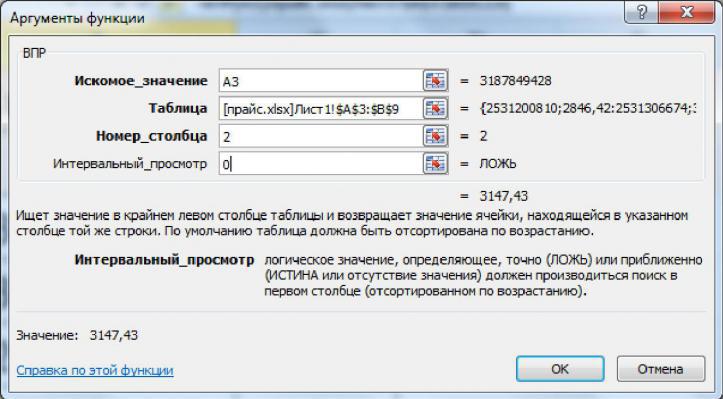
В отличии от некоторых других типов анализов, корреляционный анализ можно вызвать с помощью функций. За него отвечает функция КОРРЕЛ вида: КОРРЕЛ(массив1;массив2):
- Выделите ячейку в таблицу, куда хотите вставить полученный результат. В строке ввода формул воспользуйтесь значком функции.
Откроется окно мастера функций. В поле “Категория” нужно поставить значение “Полный алфавитный перечень”, чтобы отобразились все доступные для применения функции. Там отыщите пункт “КОРРЕЛ” нажмите по нему и затем на кнопку “Ок”.
Вам потребуется заполните в окошке настройки функции два поля, то есть указать два массива ячеек. В первый массив укажите номера ячеек, зависимость которых следует определить. Для рассматриваемой таблицы это будет массив столбца дохода компании. Номера можно вписать вручную или выделить их, кликнув по иконке таблицы в поле.
Во втором же массиве потребуется указать перечень ячеек, которые предположительно должны оказывать влияние на первый массив. В рассматриваемой таблице это величина зарплат сотрудников.
Закончив с заполнением нажмите кнопку “Ок”. Подсчет будет произведен автоматически и выведен в указанной ранее ячейке.
Если полученный коэффициент оказался больше +/-0.5, то это значит, что одна величина сильно зависима от другой.
Вариант 2: Применение пакета анализа
Вы можете использовать уже заданный шаблон корреляционного анализа, используя один из представленных пакетов анализа. По умолчанию пакеты анализа в Excel отключены, поэтому вам потребуется их включать отдельно.
- Перейдите во вкладку “Файл”, что расположена в верхней части окна.
В левой части переключитесь в раздел “Параметры”.
Откройте подраздел “Надстройки”, что находятся в левой части окна с параметрами.
У строки “Управление”, что расположена в нижней части открывшегося окна, установите значение “Надстройки Excel”. Нажмите “Перейти”, чтобы увидеть перечень доступных надстроек.
В открывшемся окне установите галочку у пункта “Пакет анализа” и нажмите “Ок”. После этого у вас должны появится дополнительные инструменты в верхней панели Excel.
Нужные нам инструменты расположена во вклакде “Данные”. Там должен будет появится дополнительный блок инструментов — “Анализ”. Воспользуйтесь в нем единственным инструментом — “Анализом данных”.
Открывается список с различными вариантами анализа данных. Укажите пункт “Корреляция”. Нажмите “Ок” для применения.
В открывшемся окошке настройки анализа уже потребуется заполнить только поле “Входной интервал”. Туда добавляется сразу два массива. В нашем случае это столбцы с зарплатой и доходом фирмы.
В блоке ниже можно указать, куда будет выводится результат. По умолчанию он выводит на новый рабочий лист, но вы можете настроить вывод в новую книгу или в определенных ячейках на текущем листе. Нажмите для применения и расчетов.
В итоге вы получите тот же результат, что и в первом способе. Единственное, в некоторых таблицах, при обработке большего количества данных значений может быть гораздо больше (в основном носят вспомогательный характер).
Первый рассмотренный нами способ подойдет для большинства таблиц, в то время как второй больше подходит для таблиц с большим перечнем данных, где еще желательно отследить логику проводимого анализа.
Корреляция и ковариация в MS EXCEL
Вычислим коэффициент корреляции и ковариацию для разных типов взаимосвязей случайных величин.
Коэффициент корреляции (критерий корреляции Пирсона, англ. Pearson Product Moment correlation coefficient) определяет степень линейной взаимосвязи между случайными величинами.
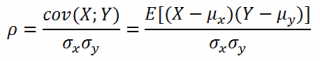
где Е – оператор математического ожидания, μ и σ – среднее случайной величины и ее стандартное отклонение.
Как следует из определения, для вычисления коэффициента корреляции требуется знать распределение случайных величин Х и Y. Если распределения неизвестны, то для оценки коэффициента корреляции используется выборочный коэффициент корреляции r (еще он обозначается как Rxy или rxy):
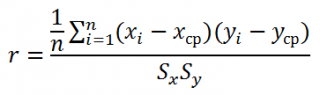
где Sx – стандартное отклонение выборки случайной величины х, вычисляемое по формуле:
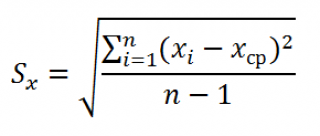
Как видно из формулы для расчета корреляции, знаменатель (произведение стандартных отклонений) просто нормирует числитель таким образом, что корреляция оказывается безразмерным числом от -1 до 1. Корреляция и ковариация предоставляют одну и туже информацию (если известны стандартные отклонения), но корреляцией удобнее пользоваться, т.к. она является безразмерной величиной.
Рассчитать коэффициент корреляции и ковариацию выборки в MS EXCEL не представляет труда, так как для этого имеются специальные функции КОРРЕЛ() и КОВАР() . Гораздо сложнее разобраться, как интерпретировать полученные значения, большая часть статьи посвящена именно этому.
Пример применения метода корреляционного анализа
В Великобритании было предпринято любопытное исследование. Оно посвящено связи курения с раком легких, и проводилось путем корреляционного анализа. Это наблюдение представлено ниже. Исходные данные для корреляционного анализа
| Профессиональная группа | курение | смертность |
| Фермеры, лесники и рыбаки | 77 | 84 |
| Шахтеры и работники карьеров | 137 | 116 |
| Производители газа, кокса и химических веществ | 117 | 123 |
| Изготовители стекла и керамики | 94 | 128 |
| Работники печей, кузнечных, литейных и прокатных станов | 116 | 155 |
| Работники электротехники и электроники | 102 | 101 |
| Инженерные и смежные профессии | 111 | 118 |
| Деревообрабатывающие производства | 93 | 113 |
| Кожевенники | 88 | 104 |
| Текстильные рабочие | 102 | 88 |
| Изготовители рабочей одежды | 91 | 104 |
| Работники пищевой, питьевой и табачной промышленности | 104 | 129 |
| Производители бумаги и печати | 107 | 86 |
| Производители других продуктов | 112 | 96 |
| Строители | 113 | 144 |
| Художники и декораторы | 110 | 139 |
| Водители стационарных двигателей, кранов и т. д. | 125 | 113 |
| Рабочие, не включенные в другие места | 133 | 146 |
| Работники транспорта и связи | 115 | 128 |
| Складские рабочие, кладовщики, упаковщики и работники разливочных машин | 105 | 115 |
| Канцелярские работники | 87 | 79 |
| Продавцы | 91 | 85 |
| Работники службы спорта и отдыха | 100 | 120 |
| Администраторы и менеджеры | 76 | 60 |
| Профессионалы, технические работники и художники | 66 | 51 |
Начинаем корреляционный анализ. Решение лучше начинать для наглядности с графического метода, для чего построим диаграмму рассеивания (разброса).
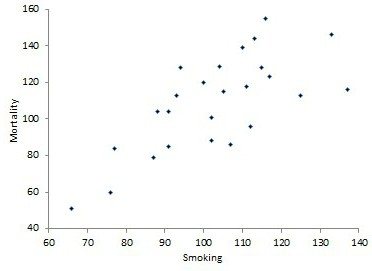
Она демонстрирует прямую связь. Однако на основании только графического метода сделать однозначный вывод сложно. Поэтому продолжим выполнять корреляционный анализ. Пример расчета коэффициента корреляции представлен ниже.
С помощью программных средств (на примере MS Excel будет описано далее) определяем коэффициент корреляции, который составляет 0,716, что означает сильную связь между исследуемыми параметрами. Определим статистическую достоверность полученного значения по соответствующей таблице, для чего нам нужно вычесть из 25 пар значений 2, в результате чего получим 23 и по этой строке в таблице найдем r критическое для p=0,01 (поскольку это медицинские данные, здесь используется более строгая зависимость, в остальных случаях достаточно p=0,05), которое составляет 0,51 для данного корреляционного анализа. Пример продемонстрировал, что r расчетное больше r критического, значение коэффициента корреляции считается статистически достоверным.
Выборочный r и популяционный ρ
Аналогично среднему значению и стандартному отклонению, коэффициент корреляции является сводной статистикой. Он описывает выборку; в данном случае, выборку спаренных значений: роста и веса. Коэффициент корреляции известной выборки обозначается буквой r, тогда как коэффициент корреляции неизвестной популяции обозначается греческой буквой ρ (рхо).
Как мы убедились в предыдущей серии постов о тестировании гипотез, мы не должны исходить из того, что результаты, полученные в ходе измерения нашей выборки, применимы к популяции в целом. К примеру, наша популяция может состоять из всех пловцов всех недавних Олимпийских игр. И будет совершенно недопустимо обобщать, например, на другие олимпийские виды спорта, такие как тяжелая атлетика или фитнес-плавание.
Даже в допустимой популяции — такой как пловцы, выступавшие на недавних Олимпийских играх, — наша выборка коэффициента корреляции является всего лишь одной из многих потенциально возможных. То, насколько мы можем доверять нашему r, как оценке параметра ρ, зависит от двух факторов:
-
Размера выборки
-
Величины r
Безусловно, чем больше выборка, тем больше мы ей доверяем в том, что она представляет всю совокупность в целом. Возможно, не совсем интуитивно очевидно, но величина тоже оказывает влияние на степень нашей уверенности в том, что выборка представляет параметр . Это вызвано тем, что большие коэффициенты вряд ли возникли случайным образом или вследствие случайной ошибки при отборе.
Проверка статистических гипотез
В предыдущей серии постов мы познакомились с проверкой статистических гипотез, как средством количественной оценки вероятности, что конкретная гипотеза (как, например, что две выборки взяты из одной и той же популяции) истинная. Чтобы количественно оценить вероятность, что корреляция существует в более широкой популяции, мы воспользуемся той же самой процедурой.
В первую очередь, мы должны сформулировать две гипотезы, нулевую гипотезу и альтернативную:
H — это гипотеза, что корреляция в популяции нулевая. Другими словами, наше консервативное представление состоит в том, что измеренная корреляция целиком вызвана случайной ошибкой при отборе.
H1 — это альтернативная возможность, что корреляция в популяции не нулевая. Отметим, что мы не определяем направление корреляции, а только что она существует. Это означает, что мы выполняем двустороннюю проверку.
Стандартная ошибка коэффициента корреляции r по выборке задается следующей формулой:
Эта формула точна, только когда r находится близко к нулю (напомним, что величина ρ влияет на нашу уверенность), но к счастью, это именно то, что мы допускаем согласно нашей нулевой гипотезы.
Мы можем снова воспользоваться t-распределением и вычислить t-статистику:
В приведенной формуле df — это степень свободы наших данных. Для проверки корреляции степень свободы равна n — 2, где n — это размер выборки. Подставив это значение в формулу, получим:
В итоге получим t-значение 102.21. В целях его преобразования в p-значение мы должны обратиться к t-распределению. Библиотека scipy предоставляет интегральную функцию распределения (ИФР) для t-распределения в виде функции , и комплементарной ей (1-cdf) функции выживания . Значение функции выживания соответствует p-значению для односторонней проверки. Мы умножаем его на 2, потому что выполняем двустороннюю проверку:
P-значение настолько мало, что в сущности равно 0, означая, что шанс, что нулевая гипотеза является истинной, фактически не существует. Мы вынуждены принять альтернативную гипотезу о существовании корреляции.
Как выполняется корреляция в Excel?
«Корреляция» в переводе с латинского обозначает «соотношение», «взаимосвязь». Количественная характеристика взаимосвязи может быть получена при вычислении коэффициента корреляции.
Этот популярный в статистических анализах коэффициент показывает, связаны ли какие-либо параметры друг с другом (например, рост и вес; уровень интеллекта и успеваемость; количество травм и продолжительность работы).
Использование корреляции
Вычисление корреляции особенно широко используется в экономике, социологических исследованиях, медицине и биометрии — везде, где можно получить два массива данных, между которыми может обнаружиться связь.
Рассчитать корреляцию можно вручную, выполняя несложные арифметические действия. Однако процесс вычисления оказывается очень трудоемким, если набор данных велик. Особенность метода в том, что он требует сбора большого количества исходных данных, чтобы наиболее точно отобразить, есть ли связь между признаками.
Поэтому серьезное использование корреляционного анализа невозможно без применения вычислительной техники. Одной из наиболее популярных и доступных программ для решения этой задачи является Microsoft Office Excel.
Как выполнить корреляцию в Excel?
Самым трудоемким этапом определения корреляции является набор массива данных. Сравниваемые данные располагаются обычно в двух колонках или строчках. Таблицу следует делать без пропусков в ячейках. Современные версии Excel (с 2007 и младше) не требуют установок дополнительных настроек для статистических расчетов; необходимые манипуляции можно сделать в разделе формул:
- Выбрать пустую ячейку, в которую будет выведен результат расчетов.
- Нажать в главном меню Excel пункт «Формулы».
- Среди кнопок, сгруппированных в «Библиотеку функций», выбрать «Другие функции».
- В выпадающих списках выбрать функцию расчета корреляции (Статистические — КОРРЕЛ).
- В Excel откроется панель «Аргументы функции». «Массив 1» и «Массив 2» — это диапазоны сравниваемых данных. Для автоматического заполнения этих полей можно просто выделить нужные ячейки таблицы.
- Нажать «ОК», закрыв окно аргументов функции. В ячейке появится подсчитанный коэффициент корреляции.
Корреляция может быть прямая (если коэффициент больше нуля) и обратная (от -1 до 0).
Первая означает, что при росте одного параметра растет и другой. Обратная (отрицательная) корреляция отражает факт, что при росте одной переменной другая уменьшается.
Корреляция может быть близка к нулю. Это обычно свидетельствует, что исследуемые параметры не связаны друг с другом. Но иногда нулевая корреляция возникает, если сделана неудачная выборка, которая не отразила связь, либо связь имеет сложный нелинейный характер.
Если коэффициент показывает среднюю или сильную взаимосвязь (от ±0,5 до ±0,99), следует помнить, что это лишь статистическая взаимосвязь, которая вовсе не гарантирует влияние одного параметра на другой. Также нельзя исключать ситуации, что оба параметра независимы друг от друга, но на них воздействует какой-нибудь третий неучтенный фактор.
Excel помогает моментально вычислить коэффициент корреляции, но обычно только количественных методов недостаточно для установления причинно-следственных связей в соотносимых выборках.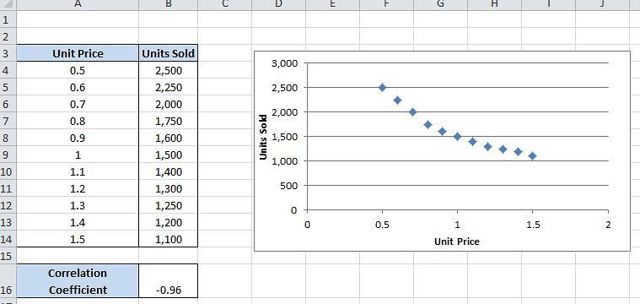
Как рассчитать коэффициент корреляции
Давайте продемонстрируем механизм получения коэффициента корреляции на реальном кейсе. Допустим, у нас есть таблица с информацией о суммах продаж и рекламу. Нам нужно понять, в какой степени количество продаж и количество денег, которые были использованы на продвижение, взаимосвязаны.
Способ 1. Определение корреляции с помощью Мастера Функций
Функция КОРРЕЛ – один из самых простых методов, как можно реализовать поставленную задачу. В своем общем виде этот оператор имеет следующий вид: КОРРЕЛ(массив1;массив2). Как же ее ввести? Для этого нужно осуществлять следующие действия:
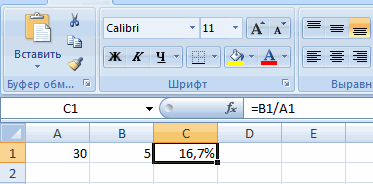
- С помощью левой кнопки мыши выделяем ту ячейку, в которой будет находиться получившийся коэффициент корреляции. После этого находим слева от строки формул кнопку fx, которая откроет инструмент ввода функций.
- Далее выбираем категорию «Полный алфавитный перечень», в котором ищем функцию КОРРЕЛ. Как видно из названия категории, все названия функций располагаются в алфавитном порядке.
- Далее открывается окно ввода параметров функции. У нас два основных аргумента, каждый из которых являет собой массив данных, которые сравниваются между собой. В поле «Массив 1» указываем координаты первого диапазона, а в поле «Массив 2» – адрес второго диапазона. Для ввода данных массива, используемого для расчета, достаточно выделить нажать левой кнопкой мыши по соответствующему полю и выделить правильный диапазон.
- После того, как мы введем данные в аргументы, нажимаем кнопку «ОК», чем подтверждаем совершенные действия.
После выполнения описанных выше шагов мы видим в ячейке, выбранной нами на первом этапе, коэффициент корреляции. В нашем примере он составляет 0,97, что указывает на очень сильно выраженную взаимосвязь между данными двух диапазонов.
Способ 2. Вычисление корреляции с помощью пакета анализа
Также довольно неплохой инструмент для определения корреляции между двумя диапазонами – пакет анализа. Но перед тем, как его использовать, нам надо его включить. Для этого выполняем следующие действия:
- Нажимаем на кнопку «Файл», которая находится в левом верхнем углу сразу возле вкладки «Главная».
- После этого открываем раздел с настройками.
- В меню слева переходим в предпоследний пункт, озаглавленный, как «Надстройки». Делаем левый клик по соответствующей надписи.
- Открывается окно управления надстройками. Нам нужно переключить поле ввода, находящееся внизу, на пункт «Надстройки Excel» и нажать на «Перейти». Если это поле уже находится в таком положении, то не выполняем никаких изменений.
- Затем включаем пакет анализа в настройках. Для этого ставим соответствующую галочку и нажимаем на кнопку «ОК».
Все, теперь наша надстройка включена. Теперь мы во вкладке «Данные» можем увидеть кнопку «Анализ данных». Если она появилась, то мы все сделали правильно. Нажимаем на нее.
Появляется перечень с выбором разных способов анализа информации. Нам следует выбрать пункт «Корреляция» и нажать на «ОК».
Затем нам нужно ввести настройки. Основное отличие этого метода от предыдущего заключается в том, что нам нужно вводить полностью диапазон, а не разрывать его на две части. В нашем случае, это информация, указанная в двух столбцах «Затраты на рекламу» и «Величина продаж».
Не вносим никаких изменений в параметр «Группирование». По умолчанию выставлен пункт «По столбцам», и он правильный. Эта настройка определяет, каким образом программа будет разбивать данные. Если же наши данные были бы представлены в двух рядах, то надо было бы изменить этот пункт на «По строкам».
В настройках вывода уже стоит пункт «Новый рабочий лист». То есть, информация о корреляции будет располагаться на отдельном листе. Пользователь может настроить место самостоятельно с помощью соответствующего переключателя – на текущий лист или в отдельный файл. Проверяем, все ли настройки были введены правильно. Если да, подтверждаем свои действия нажатием на клавишу «ОК».
Поскольку мы оставили поле с данными о том, куда будут выводиться результаты, таким, каким оно было, мы переходим на новый лист. На нем можно найти коэффициент корреляции. Конечно, он такой же самый, как был в предыдущем методе – 0,97. Причина этого в том, что вычисления производятся одинаковые, исходные данные мы также не меняли. Просто разными методами, но не более.
Таким образом, Эксель дает сразу два метода осуществления корреляционного анализа. Как вы уже понимаете, в результате вычислений итог получится таким же. Но каждый пользователь может выбрать тот метод расчета, который ему больше всего подходит.
Корреляционная функция
Для графического отображения полученных результатов применяют корреляционную функцию (КФ), являющуюся зависимостью коэффициента корреляции явления от временного сдвига (лага). Существует два вида КФ: классическая, или техническая, и интервальная (рис. 7 и рис. 8 соответственно). Классическая корреляционная функция для анализа ЭЭГ не подходит, т.к. при разных t анализу будут подлежать участки разной протяженности, а для сопоставимости коэффициентов корреляции это допустимо только в случае стационарности процессов, которые сохраняют свои свойства на всей протяженности.
Классическая корреляционная функция имеет недостатки:
- невозможность сопоставлять коэффициенты корреляции, которые были вычислены для фрагментов ЭЭГ с различной протяженностью, поскольку полученные коэффициенты будут иметь разные характеристики (т.к. ЭЭГ не является стационарным процессом)
- размер выборки может отличаться; величины на одном конце функции могут быть значимые, а на другом – нет.
Рисунок 7. Классическая, или техническая, корреляционная функция
При построении интервальной корреляционной функции на записи сигнала обращают внимание на корреляционный образец χ длиной Δt, от которого начинается эпоха анализа Т. Чтобы найти связь между явлениями χ при изменении t, необходим анализ равноразмерных участков γ, которые сдвинуты относительно χ на значение τ
(рис. 8)
Если сравнивать интервальную и классическую корреляционные функции, то можно заметить, что интервальная функция имеет несколько преимуществ:
- Используется чаще при выявлении задержек в ЭЭГ-сигнале;
- Повторение этапов высоких значений при сдвигах образца;
- Ее легко интерпретировать.
При исследовании интервальной корреляционной функции необходимо отметить, что высокие значения функции при автокорреляции – это возможное следствие возврата к исходному функциональному состоянию, а в случае кросскорреляционной функции – задержки передачи сигнала между отведениями.
Рисунок 8. Интервальная корреляционная функция
Наиболее чувствительный метод для поиска различий в ЭЭГ-сигналах – огибающая ЭЭГ, оценивающая меру синхронности или асинхронности изменений постсинаптических потенциалов в исследуемых отведениях (амплитуда сигнала повышается при одновременном изменении двух сигналов).