Регулярные выражения в php
Содержание:
- PHP regex dot metacharacter
- PHP regex exact word match
- PHP regex alternation
- 2 Практический раздел. Ссылки
- Операторы для работы с регулярными выражениями в Javascript
- Метасимволы
- PHP regex quantifiers
- Экранируем спецсимволы
- Основы основ
- Функции регулярных выражений
- Опережающие и ретроспективные проверки — (?=) and (?
- Заключение
- Основной синтаксис регулярных выражений в PHP
- Регулярные выражения в разных языках программирования
- Практические примеры сложных регулярных выражений
- PHP regex extracting matches
- Функции для работы с регулярными выражениями
PHP regex dot metacharacter
The (dot) metacharacter stands for any single character in the text.
single.php
<?php
$words = ;
$pattern = "/.even/";
foreach ($words as $word) {
if (preg_match($pattern, $word)) {
echo "$word matches the pattern\n";
} else {
echo "$word does not match the pattern\n";
}
}
In the array, we have five words.
$pattern = "/.even/";
Here we define the search pattern. The pattern is a string. The regular expression
is placed within delimiters. The delimiters are mandatory.
In our case, we use forward slashes as delimiters. Note that we
can use different delimiters if we want. The dot character stands for any single character.
if (preg_match($pattern, $word)) {
echo "$word matches the pattern\n";
} else {
echo "$word does not match the pattern\n";
}
We test all five words if they match with the pattern.
$ php single.php Seven matches the pattern even does not match the pattern Maven does not match the pattern Amen does not match the pattern Leven matches the pattern
The Seven and Leven words match our search pattern.
PHP regex exact word match
In the following examples we show how to look for exact word matches.
php> echo preg_match("/mother/", "mother");
1
php> echo preg_match("/mother/", "motherboard");
1
php> echo preg_match("/mother/", "motherland");
1
The pattern fits the words mother, motherboard and motherland.
Say, we want to look just for exact word matches. We will use the aforementioned
anchor and characters.
php> echo preg_match("/^mother$/", "motherland");
0
php> echo preg_match("/^mother$/", "Who is your mother?");
0
php> echo preg_match("/^mother$/", "mother");
1
Using the anchor characters, we get an exact word match for a pattern.
PHP regex alternation
The next example explains the alternation operator . This operator
enables to create a regular expression with several choices.
alternation.php
<?php
$names = ;
$pattern = "/Jane|Beky|Robert/";
foreach ($names as $name) {
if (preg_match($pattern, $name)) {
echo "$name is my friend\n";
} else {
echo "$name is not my friend\n";
}
}
We have eight names in the array.
$pattern = "/Jane|Beky|Robert/";
This is the search pattern. The pattern looks for ‘Jane’, ‘Beky’, or
‘Robert’ strings.
$ php alternation.php Jane is my friend Thomas is not my friend Robert is my friend Lucy is not my friend Beky is my friend John is not my friend Peter is not my friend Andy is not my friend
This is the output of the script.
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
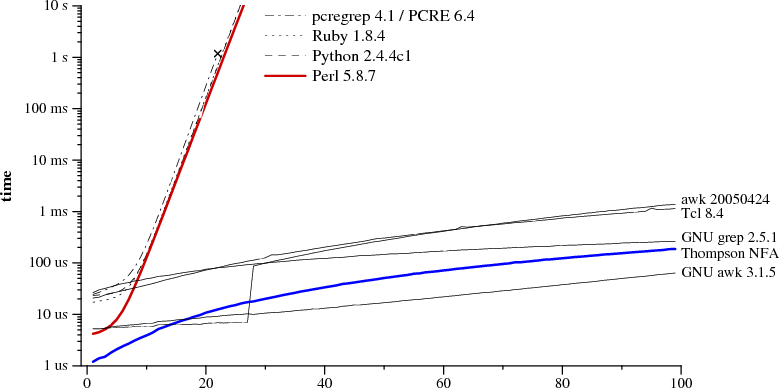
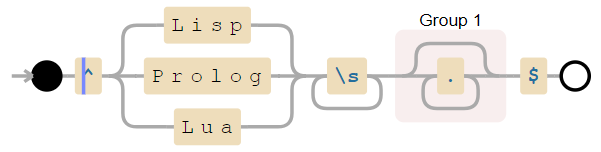
Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.
Операторы для работы с регулярными выражениями в Javascript
exec(regexp) — находит все совпадения (вхождения в шаблон «регулярки») в строке. Возвращает массив (при совпадении) и обновляет свойство regexp-а, или null — если ничего не найдено,.
С модификатором g — при каждом вызове этой функции, она будет возвращать следующее совпадение после предыдущего найденного — это реализовано с помощью ведения индекса смещения последнего поиска.
match(regexp) — найти часть строки по шаблону. Если указан модификатор g, то функция match() возвращает массив всех совпадений или null (а не пустой массив). Без модификатора g эта функция работает как exec();
test(regexp) — функция проверяет строку на соответствие шаблону. Возвращает true — если есть совпадение, и false — если совпадения нет.
replace(regexp, mix) — метод возвращает строку изменную в соответствии с шаблоном (регуляррным выражением). Первый параметр regexp также может содержать строку, а не регулярное выражение. Без модификатора g — метод в строке заменяет только первое вхождение; с модификатором g — происходит глобальная замена, т.е. меняются все вхождения в данной строке. mix — шаблон замены, может принитать значения строки, шаблона замены, функции (имя функции).
Стоит подробнее остановиться на методе replace(), его второй параметр mix нужно описать более детально.
Если второй параметр mix содержит строку, то мы можем использовать следующие спецсимволы:
- $$ — вставить $;
- $& — совпавшая подстрока;
- $` — часть строки перед совпавшей подстроки;
- $’ — часть строки после совпавшей подстроки;
- $n ($nn) — значение n-ой запоминающей скобки (если первый аргумент — объект RegExp);
Если второй параметр mix содержит функцию, то она будет вызванна при каждом совпадении. Значением для замены будет результат работы функции, т.е. return »;
Примеры таких функции:
Следующий вызов replace возвратит XXzzzz — XX , zzzz.
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра p1, p2.
Если бы были три скобки, то в функцию пришлось бы добавить параметр p3.
Следующая функция заменяет слова типа borderTop на border-top:
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Таким блоком кода я разбираю javascript вхождения в html:
Класс RegExp
Этот класс отвечает за обработку строк с помощью регелярных выражений. Его конструктор имеет следующий вид:
RegExp(Регулярное выражение, Флаги)
Он принимает только один обязательный пареметр — это «Регулярное выражение», которое заключается в кавычки.
Параметр «флаги» представляет собой дополнительные условия поиска и может принимать значения:
- g — задается глобальный поиск, если этот флаг установлен, то выражение возвратит все подходящие слова.
- i — игнорирование регистра символов
- m — многострочный поиск
Для работы с регулярными варажениями используются три метода класса String:
-
match — выполняет поиск в строке, используя регулярное выражение, переданное в качестве параметра
и возвращает массив с результатами поиска. Если ничего не найдено, возвращается null. - replace — выполняет поиск и замену в строке, используя регулярные выражения, и возвращает полученную строку.
-
search — выполняет поик в строке, используя регулярное выражение, переданное в качестве параметра,
и возвращает позицию первой подстроки, совпадающей с регулярным выражением.
Свойства
| Свойство | Описание |
| lastIndex | Задает позицию начала поиска в строке |
| sourse | Возвращает строку регулярного выражения (только чтение) |
| global | Определяет наличие флага g и возвращает соответсявенно true или false |
| ignoreCase | Определяет наличие флага i и возвращает соответсявенно true или false |
| multilane | Определяет наличие флага m и возвращает соответсявенно true или false |
Методы
| Метод | Описание |
| compile (Регулярное выражение g,i,m) | Компилирует регулярное выражение во внутренний формат для ускорения работы, может использоваться для изменения регулярного выражения |
| exec(строка) | Аналогичен методу match класса String, но строка, где нужно произвести поиск, передается в качестве параметра |
| test(строка) | Аналогичен методу search класса String, возвращает true или false в зависимости о результатов поиска |
Пример
Здесь этот участок скрипта производит поиск текста «www» в строке, которая была присвоена переменной «str» без учета регистра,
а метод match возвращает массив result, содержащий результаты поиска.
Метасимволы
В регулярных выражениях используются два типа символов: обычные символы и метасимволы. Обычные символы — это те символы, которые имеют «буквальное» значение, а метасимволы — это те символы, которые имеют «особое» значение в регулярном выражении.
Преимуществом регулярных выражений является возможность использовать условия и повторения в шаблоне. Выражения записываются при помощи метасимволов, которые специальным образом интерпретируются. Метасимвол отличается от любого другого символа тем, что имеет специальное значение.
Одним из основных метасимволов является обратный слэш (\), который меняет тип символа, следующего за ним, на противоположный. Таким образом обычный символ можно превратить в метасимвол, а если это был метасимвол, то он теряет свое специальное значение и становится обычным символом. Этот приём нужен для того, чтобы вставлять в текст специальные символы как обычные. Например, символ в обычном режиме не имеет никаких специальных значений, но — это уже метасимвол, который обозначает: «любая цифра». Символ точка в обычном режиме значит — «любой единичный символ», а экранированная точка (\.) означает просто точку.
| Метасимвол | Описание | пример |
|---|---|---|
| . | Соответствует любому одиночному символу, кроме новой строки. | /./ соответствует строке, состоящей из одного символа. |
| ^ | Соответствует началу строки. | /^cars/ соответствует любой строке, которая начинается с cars. |
| $ | Соответствует шаблону в конце строки. | /com$/ соответствует строке, заканчивающейся на com, например gmail.com |
| * | Соответствует 0 или более вхождений. | /com*/ соответствует commute, computer, compromise и т.д. |
| + | Соответствующий предыдущему символу появляется как минимум один раз. | Например, /z+oom/ соответствует zoom. |
| \ | Используется для удаления метасимволов в регулярном выражении. | /google\.com/ будет рассматривать точку как буквальное значение, а не как метасимвол. |
| a-z | Соответствует строчным буквам. | cars |
| A-Z | Соответствует буквам в верхнем регистре. | CARS |
| 0-9 | Соответствует любому числу от 0 до 9. | /0-5/ соответствует 0, 1, 2, 3, 4, 5 |
| Соответствует классу символов. | // соответствует pqr | |
| | | Разделяет перечисление альтернативных вариантов. | /(cat|dog|fish)/ соответствует cat или dog или fish |
| \d | Любая цифра. | /(\d)/ соответствует цифре |
| \s | Найти пробельный символ (в т.ч. табуляция). | /(\s)/ соответствует пробелу |
| \b | Граница слова (начало или конец). | /\bWORD/ найти совпадение в начале слова |
PHP regex quantifiers
A quantifier after a token or a group specifies how often that
preceding element is allowed to occur.
? - 0 or 1 match
* - 0 or more
+ - 1 or more
{n} - exactly n
{n,} - n or more
{,n} - n or less (??)
{n,m} - range n to m
The above is a list of common quantifiers.
The question mark indicates there is zero or one of
the preceding element.
zeroorone.php
<?php
$words = ;
$pattern = "/colou?r/";
foreach ($words as $word) {
if (preg_match($pattern, $word)) {
echo "$word matches the pattern\n";
} else {
echo "$word does not match the pattern\n";
}
}
We have four nine in the array.
$pattern = "/colou?r/";
Color is used in American English, colour in British English.
This pattern matches both cases.
$ php zeroorone.php color matches the pattern colour matches the pattern comic does not match the pattern colourful matches the pattern colored matches the pattern cosmos does not match the pattern coloseum does not match the pattern coloured matches the pattern colourful matches the pattern
This is the output of the script.
The metacharacter matches the preceding element
zero or more times.
zeroormore.php
<?php
$words = ;
$pattern = "/.*even/";
foreach ($words as $word) {
if (preg_match($pattern, $word)) {
echo "$word matches the pattern\n";
} else {
echo "$word does not match the pattern\n";
}
}
In the above script, we have added the metacharacter.
The combination means, zero, one or more single characters.
$ php zeroormore.php Seven matches the pattern even matches the pattern Maven does not match the pattern Amen does not match the pattern Leven matches the pattern
Now the pattern matches three words: Seven, even and Leven.
php> print_r(preg_grep("#o{2}#", ));
Array
(
=> gool
=> root
=> foot
)
The pattern matches strings that contain exactly
two ‘o’ characters.
php> print_r(preg_grep("#^\d{2,4}$#", ));
Array
(
=> 12
=> 123
=> 1234
)
We have this pattern. The is a character
set; it stands for digits. The pattern matches numbers that have 2, 3, or 4 digits.
Экранируем спецсимволы
Иногда надо сделать так, чтобы спецсимвол обозначал себя сам. К примеру, чтобы найти по следующему шаблону: ‘a’, потом плюс ‘+’, потом ‘x’. Код ниже будет функционировать не совсем так, как хочется:
<?php
echo preg_replace('#a+x#', '!', 'a+x ax aax aaax'); //выведет 'a+x ! ! !''
?>
Тут разработчик планировал, чтобы шаблон поиска выглядел следующим образом: буква ‘a’, потом плюс ‘+’, потом ‘x’. На деле он выглядит иначе: буква ‘a’ один либо больше раз, потом ‘x’. Именно поэтому подстрока ‘a+x’ не подпала под шаблон (так как мешает ‘+’), а все остальные подпали.
Здесь важно запомнить следующее: чтобы спецсимвол обозначал себя сам, его надо экранировать посредством обратного слеша. Вот, каким образом это можно реализовать:
Теперь наш шаблон поиска выглядит нужным образом: буква ‘a’, потом плюс ‘+’, потом ‘x’.
В примере выше шаблон выглядит следующим образом: ‘a’, далее точка ‘.’, далее ‘x’. Сравним с примером ниже (тут забыт обратный слэш):
В результате все подстроки попали под шаблон, ведь неэкранированная точка обозначает, по сути, любой символ.
Следует обратить внимание вот на что: если забудете обратный слэш для точки (в случае, когда она должна сама себя обозначать), это можно даже и не заметить:
Да, визуально все работает правильно, но т. к. точка обозначает любой символ, включая обычную точку ‘.’. Однако если строку, где происходят замены, поменять, ошибка станет заметна:
Вывод прост: следует быть предельно внимательным!
Основы основ
Для начала нужно понять что в Regex есть специальные символы (например символ начала строки — ), если вы хотите просто найти данный символ, то нужно ввести обратный слеш перед символом для того, чтобы символ не работал как команда.
Для того чтобы найти текст, нужно собственно просто ввести этот текст:
Якори
— символ который обозначает начало строки
— символ который обозначает конец строки
Найдем строки которые начинаются с The Beginning:
Найдем строки, которые заканчиваются на The End:
Найдем строки, которые начинаются и заканчиваются на The Beginning and The End:
Найдем пустые строки:
Квантификаторы
— символ, который указывает на то, что выражение до него должно встретиться 0 или 1 раз
— символ, который указывает на то, что выражение до него должно встретиться один или больше раз
— символ, который указывает на то, что выражение до него должно встретиться 0 или неопределённое количество раз
— скобки с одним аргументом указывают сколько раз выражение до них должно встретиться
— скобки с двумя аргументами указывают на то, от скольки до скольки раз выражение до них должно встретиться
— скобки объединяют какое-то предложение в выражение. Обычно используется в связке с квантификаторами
Давайте попробуем найти текст, в котором будут искаться все слова, содержащие ext или ex:
Давайте попробуем найти текст, в котором слова будут содержать ext или e:
Найти все размеры одежды (XL, XXL, XXXL):
Найти все слова, у которых есть неограниченное число символов c, после которых идёт haracter:
Найти выражение, в котором слово word повторяется от одного до неограниченного количества раз:
Найти выражение, в котором выражение ch повторяется от 3 до неограниченного количества раз:
Выражение «или»
— символ, который обозначает оператор «или»
— выражение в квадратных скобках ставит или между каждым подвыражением
Найти все слова, в которых есть буквы a,e,c,h,p:
Найти все выражения в которых есть ch или pa:
Escape-последовательности
— отмечает один символ, который является цифрой (digit)\
— отмечает символ, который не является цифрой
— отмечает любой символ (число или букву (или подчёркивание)) (word)
— отмечает любой пробельный символ (space character)
— отмечает любой символ (один)
Выражения в квадратных скобках
Кроме того, что квадратные скобки служат оператором «или» между каждым символом, который в них заключён, они также могут служить и для некоторых перечислений:
— один символ от 0 до 9
— любой символ от a до z
— любой символ от A до Z
— любой символ кроме a — z
Найти все выражения, в которых есть английские буквы в нижнем регистре или цифры:
Флаги
Флаги — символы (набор символов), которые отвечают за то, каким именно образом будет происходить поиск.
Форма условия поиска в Regex выглядит вот так:
— флаг, который будет отмечать все выражения, которые соответствуют условиям поиска (по умолчанию поиск возвращает только первое выражение, которое подходит по условию) (global)
— флаг, который заставляет искать выражения вне зависимости от региста (case insensitive)
Функции регулярных выражений
PHP предоставляет программистам множество полезных функций, позволяющих использовать регулярные выражения. Рассмотрим некоторые функции, которые являются одними из наиболее часто используемых:
| Функция | Определение |
|---|---|
| preg_match() | Эта функция ищет конкретный образец в некоторой строке. Он возвращает 1 (true), если шаблон существует, и 0 (false) в противном случае. |
| preg_match_all() | Эта функция ищет все вхождения шаблона в строке. Она возвращает количество найденных совпадений с шаблоном в строке, или 0 — если вхождений нет. Функция удобна для поиска и замены. |
| ereg_replace() | Эта функция ищет определенный шаблон строки и возвращает новую строку, в которой совпадающие шаблоны были заменены другой строкой. |
| eregi_replace() | Функция ведет себя как ereg_replace() при условии, что поиск шаблона не чувствителен к регистру. |
| preg_replace() | Эта функция ведет себя как функция ereg_replace() при условии, что регулярные выражения могут использоваться как в шаблоне так и в строках замены. |
| preg_split() | Функция ведет себя как функция PHP split(). Он разбивает строку на регулярные выражения в качестве параметров. |
| preg_grep() | Эта функция ищет все элементы, которые соответствуют шаблону регулярного выражения, и возвращает выходной массив. |
| preg_quote() | Эта функция принимает строку и кавычки перед каждым символом, который соответствует регулярному выражению. |
| ereg() | Эта функция ищет строку, заданную шаблоном, и возвращает TRUE, если она найдена, иначе возвращает FALSE. |
| eregi() | Эта функция ведет себя как функция ereg() при условии, что поиск не чувствителен к регистру. |
Примечание:
- По умолчанию регулярные выражения чувствительны к регистру.
- В PHP есть разница между строками внутри одинарных кавычек и строками внутри двойных кавычек. Первые обрабатываются буквально, тогда как для строк внутри двойных кавычек печатается содержимое переменных, а не просто выводятся их имена.
Функция preg_match()
Функция выполняет проверку на соответствие регулярному выражению.
Пример. Поиск подстроки «php» в строке без учета регистра:
Попробуй сам
Результат выполнения кода:
Вхождение найдено.
В примере выше символ «i» после закрывающего ограничителя шаблона означает регистронезависимый поиск, поэтому вхождение будет найдено.
Примечание: Не используйте функцию preg_match(), если необходимо проверить наличие подстроки в заданной строке. Для этого используйте strpos() или strstr(), т.к. они выполнят эту задачу гораздо быстрее.
Функция preg_match_all()
Функция выполняет глобальный поиск шаблона в строке.
В примере регулярное выражение используется для подсчета числа вхождений «ain» в строку без учета регистра:
Попробуй сам
Результат выполнения кода:
3
Функция preg_replace()
Функция выполняет поиск и замену по регулярному выражению.
В следующем функция выполняет поиск в строке совпадений с шаблоном pattern и заменяет их на replacement:
Опережающие и ретроспективные проверки — (?=) and (?
d(?=r) соответствует d, только если после этого следует r, но r не будет входить в соответствие выражения -> тест(?<=r)d соответствует d, только если перед этим есть r, но r не будет входить в соответствие выражения -> тест
Вы можете использовать оператор отрицания !
d(?!r) соответствует d, только если после этого нет r, но r не будет входить в соответствие выражения -> тест(?<!r)d соответствует d, только если перед этим нет r, но r не будет входить в соответствие выражения -> тест
Заключение
Как вы могли убедиться, области применения регулярных выражений разнообразны. Я уверен, что вы сталкивались с похожими задачами в своей работе (хотя бы с одной из них), например такими:
- Валидация данных (например, правильно ли заполнена строка time)
- Сбор данных (особенно веб-скрапинг, поиск страниц, содержащих определённый набор слов в определённом порядке)
- Обработка данных (преобразование сырых данных в нужный формат)
- Парсинг (например, достать все GET параметры из URL или текст внутри скобок)
- Замена строк (даже во время написания кода в IDE, можно, например преобразовать Java или C# класс в соответствующий JSON объект, заменить “;” на “,”, изменить размер букв, избегать объявление типа и т.д.)
- Подсветка синтаксиса, переименование файла, анализ пакетов и многие другие задачи, где нужно работать со строками (где данные не должны быть текстовыми).
Перевод статьи Jonny Fox: Regex tutorial — A quick cheatsheet by examples
Основной синтаксис регулярных выражений в PHP
Чтобы использовать регулярные выражения, сначала вам нужно изучить синтаксис шаблонов. Мы можем сгруппировать символы внутри шаблона следующим образом:
- Обычные символы, которые следуют один за другим, например,
- Индикаторы начала и окончания строки в виде и
- Индикаторы подсчета, такие как , ,
- Логические операторы, такие как
- Группирующие операторы, такие как , ,
Пример шаблона регулярного выражения для проверки правильности адреса электронного ящика выглядит следующим образом:
^+@+\.{2,5}$
Код PHP для проверки электронной почты с использованием Perl-совместимого регулярного выражения выглядит следующим образом:
<?php
$pattern = "/^+@+\.{2,5}$/";
$email = "some-email@test.com";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Теперь давайте посмотрим на подробный разбор синтаксиса шаблона при регулярном выражении:
| Регулярное выражение (шаблон) | Проходит проверку (объект) | Не проходит проверку (объект) | Комментарий |
| Hello world | Hello Ivan | Проходит, если шаблон присутствует где-либо в объекте | |
| world class | Hello world | Проходит, если шаблон присутствует в начале объекта | |
| Hello world | world class | Проходит, если шаблон присутствует в конце объекта | |
| This WoRLd | Hello Ivan | Выполняет поиск в нечувствительном к регистру режиме | |
| world | Hello world | Строка содержит только «world» | |
| worl, world, worlddd | wor | Присутствует 0 или больше «d» после «worl» | |
| world, worlddd | worl | Присутствует по крайней мере одна «d» после «worl» | |
| worl, world, worly | wor, wory | Присутствует 0 или 1 «d» после «worl» | |
| world | worly | Присутствует одна «d» после «worl» | |
| world, worlddd | worly | Присутствует одна или больше «d» после «worl» | |
| worldd, worlddd | world | Присутствует 2 или 3 «d» после «worl» | |
| wo, world, worldold | wa | Присутствует 0 или больше «rld» после «wo» | |
| earth, world | sun | Строка содержит «earth» или «world» | |
| world, wwrld | wrld | Содержит любой символ вместо точки | |
| world, earth | sun | Строка содержит ровно 5 символов | |
| abc, bbaccc | sun | В строке есть «a», или «b» или «c» | |
| world | WORLD | В строке есть любые строчные буквы | |
| world, WORLD, Worl12 | 123 | В строке есть любые строчные или прописные буквы | |
| earth | w, W | Фактический символ не может быть «w» или «W» |
Теперь перейдем к более сложному регулярному выражению с подробным объяснением.
Регулярные выражения в разных языках программирования
Здесь я приведу примеры использования регулярных выражений в различных языках программирования
Заранее говорю, я не буду заострять внимание на синтаксисе языка программирования, так как это уже не касается данной темы. C#
C#
Здесь мы создаем строку с текстом, который хотим проверить, создаем объект класса Regex и в конструктор пишем нашу регулярку (как я и говорил, я не буду заострять внимание на том, что такое объект класса и конструктор). Потом создаем объект класса MatchCollection и от объекта regex вызываем метод Matches и в параметры передаем нашу строку
В результате все сопоставления будут добавляться в коллекцию matches.
Java
Здесь похожая ситуация. Создаем объект класса Pattern и записываем нашу строку. CASE_INSENSITIVE означает, что он не привязан к регистру (то есть нет разницы между заглавными и строчными символами). Создаем объект класса Matcher и пишем туда регулярку.
JavaScript
Здесь тоже все просто. Вы создаете объект regex и пишете туда регулярку. И затем просто создаете объект matches, который будет являться коллекцией и вызываете метод exec и в параметры передаете строку.
Практические примеры сложных регулярных выражений
Теперь, когда вы знаете теорию и основной синтаксис регулярных выражений в PHP, пришло время создать и проанализировать некоторые более сложные примеры.
1) Проверка имени пользователя с помощью регулярного выражения
Начнем с проверки имени пользователя. Если у вас есть форма регистрации, вам понадобится проверять на правильность имена пользователей. Предположим, вы не хотите, чтобы в имени были какие-либо специальные символы, кроме «» и, конечно, имя должно содержать буквы и возможно цифры. Кроме того, вам может понадобиться контролировать длину имени пользователя, например от 4 до 20 символов.
Сначала нам нужно определить доступные символы. Это можно реализовать с помощью следующего кода:
После этого нам нужно ограничить количество символов следующим кодом:
{4,20}
Теперь собираем это регулярное выражение вместе:
^{4,20}$
В случае Perl-совместимого регулярного выражения заключите его символами ‘‘. Итоговый PHP-код выглядит так:
<?php
$pattern = '/^{4,20}$/';
$username = "demo_user-123";
if (preg_match($pattern, $username)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
2) Проверка шестнадцатеричного кода цвета регулярным выражением
Шестнадцатеричный код цвета выглядит так: , также допустимо использование краткой формы, например . В обоих случаях код цвета начинается с и затем идут ровно 3 или 6 цифр или букв от a до f.
Итак, проверяем начало кода:
^#
Затем проверяем диапазон допустимых символов:
После этого проверяем допустимую длину кода (она может быть либо 3, либо 6). Полный код регулярного выражения выйдет следующим:
^#(({3}$)|({6}$))
Здесь мы используем логический оператор, чтобы сначала проверить код вида , а затем код вида . Итоговый PHP-код проверки регулярным выражением выглядит так:
<?php
$pattern = '/^#(({3}$)|({6}$))/';
$color = "#1AA";
if (preg_match($pattern, $color)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
3) Проверка электронной почты клиента с использованием регулярного выражения
Теперь давайте посмотрим, как мы можем проверить адрес электронной почты с помощью регулярных выражений. Сначала внимательно рассмотрите следующие примеры адресов почты:
john.doe@test.com john@demo.ua john_123.doe@test.info
Как мы можем видеть, символ является обязательным элементом в адресе электронной почты. Помимо этого должен быть какой-то набор символов до и после этого элемента. Точнее, после него должно идти допустимое доменное имя.
Таким образом, первая часть должна быть строкой с буквами, цифрами или некоторыми специальными символами, такими как . В шаблоне мы можем написать это следующим образом:
^+
Доменное имя всегда имеет, скажем, имя и tld (top-level domain) – т.е, доменную зону. Доменная зона – это , , и тому подобное. Это означает, что шаблон регулярного выражения для домена будет выглядеть так:
+\.{2,5}$
Теперь, если мы соберем все в кучу, то получим полный шаблон регулярного выражения для проверки адреса электронной почты:
^+@+\.{2,5}$
В коде PHP эта проверка будет выглядеть следующим образом:
<?php
$pattern = '/^+@+\.{2,5}$/';
$email = "john_123.doe@test.info";
if (preg_match($pattern, $email)) {
echo "Проверка пройдена успешно!";
} else {
echo "Проверка не пройдена!";
}
?>
Надеемся, что сегодняшняя статья помогла вам при знакомстве с регулярными выражениями в PHP, а практические примеры пригодятся вам при использовании регулярных выражений в собственных PHP скриптах.
-
3563
-
35
-
Опубликовано 16/04/2019
-
PHP, Уроки программирования
PHP regex extracting matches
The takes an optional third parameter.
If it is provided, it is filled with the results of the search.
The variable is an array whose first element contains the text that
matched the full pattern, the second element contains
the first captured parenthesized subpattern, and so on.
extract_matches.php
<?php
$times = ;
$pattern = "/(\d\d):(\d\d):(\d\d)/";
foreach ($times as $time) {
$r = preg_match($pattern, $time, $match);
if ($r) {
echo "The $match is split into:\n";
echo "Hour: $match\n";
echo "Minute: $match\n";
echo "Second: $match\n";
}
}
In the example, we extract parts of a time string.
$times = ;
We have three time strings in English locale.
$pattern = "/(\d\d):(\d\d):(\d\d)/";
The pattern is divided into three subpatterns using square
brackets. We want to refer specifically to exactly to
each of these parts.
$r = preg_match($pattern, $time, $match);
We pass a third parameter to the
function. In case of a match, it contains text parts of
the matched string.
if ($r) {
echo "The $match is split into:\n";
echo "Hour: $match\n";
echo "Minute: $match\n";
echo "Second: $match\n";
}
The contains the text that matched the full
pattern, contains text that matched the first
subpattern, the second, and
the third.
$ php extract_matches.php The 10:10:22 is split into: Hour: 10 Minute: 10 Second: 22 The 23:23:11 is split into: Hour: 23 Minute: 23 Second: 11 The 09:06:56 is split into: Hour: 09 Minute: 06 Second: 56
This is the output of the example.
Функции для работы с регулярными выражениями
В PHP есть поддержка 2 типов записи РВ — POSIX и Perl. POSIX (Portable Operating System Interface) представляет собой интерфейс переносной операционной системы и стандарт для интерфейсов приложений. Сейчас мы рассмотрим РВ POSIX и Perl-совместимые РВ.
Скорость выполнения функций для работы с РВ ниже строковых функций, которые обладают аналогичными возможностями. По этой причине лучше использовать строковые функции — если, конечно, ущерба эффективности не наносится.
ereg()
bool ereg(string pattern, string string )
Эта функция осуществляет поиск соответствия РВ в строке string, который задан в шаблоне pattern. В случае наличия соответствий шаблона с подвыражениями их сохранят в массиве соответствий regs. В $regs имеется копия строки string, а в $regs находится подстрока, которая начинается с первой левой скобки. Подстрока со второй левой скобки хранится в $regs и т. д.
Рассмотрим код, который из формата YYYY-MM-DD преобразовывает формат даты в DD.MM.YYYY.
<? $date = "2015-03-21";
if (ereg ("({4})-({1,2})-({1,2})", $date, $regs)){
echo "$regs.$regs.$regs";
}
else{
echo "Неверный формат даты: $date";
}
?>
ereg_replace()
string ereg_replace(string pattern, string replacement, string string)
Данная функция меняет шаблон pattern, который был обнаружен в строке string, на строку replacement. При наличии соответствия происходит осуществление модифицированной строки.
Будьте внимательны: указание числа как типа, который отличен от строкового, является ошибкой — число должно всегда указываться как строка.
<?
$number = "1952";
$str = "Он родился в пятьдесят втором.";
echo("до замены:$str");
$str = ereg_replace("пятьдесят втором", $number, $str);
echo("<br> после замены: $str");
?>
Результат:
до замены: Он родился в пятьдесят втором.после замены: Он родился в 1952.
eregi()
bool eregi (string pattern, string string)
Данная функция аналогична ereg. Отличие состоит в том, что регистр игнорируется.
eregi_replace()
string eregi_replace (string pattern, string replacement, string string)
Отличие данной функции от ereg_replace состоит в том, что она не является чувствительной к регистру.
split()
array split (string pattern, string string )
Данная функция проводит возвращение массива строк из подстрок строк string, которые были образованы в соответствии с РВ pattern в ходе разделения строки string на подстроки. При указании параметра limit (он не является обязательным) возвращаемый массив будет иметь до limit элементов, причем в последнем имеется неразделенная часть строки.
Данная функция окажет пользу при разделении доменных имен, дат и проч. Например:
<?
$url = "www.softtime.ru";
$array = split ("\.", $url);
foreach($array as $index => $val) {
echo("$index -> $val <br />");
}?>
В результате будет следующее:
0 -> www 1 -> softtime 2 -> ru
Это же можно осуществить и с датой:
<?
$date = "10-12-2003"
$array = split ("-", $date);
foreach($array as $index => $val){
echo("$index -> $val <br />");
}
?>
В результате мы получим:
0 -> 10 1 -> 12 2 -> 2015
spliti()
array spliti (string pattern, string string )