Зачем нужны базы данных
Содержание:
- Сравниваем три модели баз данных
- Требования к проектированию БД
- Отношения между таблицами
- 5 последних уроков рубрики «Разное»
- SQL и NoSQL
- Виды баз данных
- Как хранится информация в БД
- Другие модели баз данных (ООСУБД)
- 1 Анализ предметной области
- Достоинства документных баз
- Особенности реляционных баз
- Ключ-значение
- Нормализация базы данных
Сравниваем три модели баз данных
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
«Один к одному»
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
«Один ко многим»
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
«Многие ко многим»
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
Требования к проектированию БД
О видах и особенностях реляционных БД мы уже поговорили. Теперь давайте подробнее обсудим сложности их проектирования. В данном случае этот процесс начинается с постановки задач, исходя из нужных требований, особенностей использования, недостатков либо достоинств той либо иной системы управления. В случае с СУБД MySQL необходимо правильно составить общую структуру.
Требования обычно следующие:1. База данных должна быть относительно простой в плане обработки информации.2. Она должна быть максимально компактной и неизбыточной настолько, насколько это возможно без ущерба для функциональности.
Возможны и другие требования, причём нередко они противоречат друг другу
Именно поэтому важно найти оптимальный баланс с точки зрения архитектуры, учитывая назначение конечного продукта
Так как проектирование — важнейший процесс, им занимается проектировщик. Обычно к работе привлекают профессиональных администраторов серверов либо архитекторов БД, имеющих большой практический опыт. Нужно четко понимать, что проектируется и какие результаты должны получиться на выходе. Это бывает непросто, так как, если речь идёт о серьёзных проектах, готовая структура может включать в себя десятки и сотни таблиц, которые бывают связаны друг с другом как простыми, так и замысловатыми способами.
Результат проектирования — диаграмма или схема. Это подробное схематическое описание, в котором указываются, какие данные будут храниться, сколько столбцов в таблице, тип столбцов в таблице, как связаны таблицы между собой и многое другое. При правильном и грамотном проектировании система будет работать стабильно и без сбоев. В обратном случае ожидайте проблем, так как нет ничего хуже, чем ошибиться на этапе построения архитектуры проекта.
Если вы хотите овладеть базами данных на высоком профессиональном уровне, записывайтесь на соответствующий курс в OTUS. Практикующие эксперты научат вас особенностям управления БД и тому, как эффективно взаимодействовать с любой реляционной СУБД, используя для этого язык структурированных запросов SQL.
Отношения между таблицами
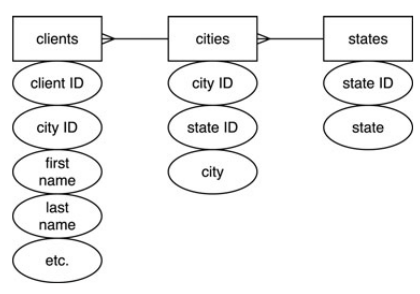
Чтобы база данных стала реляционной, одних данных мало. Между ними нужны еще и связи (те самые relations, от которых и пошло слово «реляционный»).
Для связи между таблицами служит так называемый внешний ключ (foreign key). Название довольно точно выражает его суть. Если в таблице A есть столбец для хранения первичного ключа таблицы B, то такой столбец и называется внешним ключом. Первичные и внешние ключи устанавливают связи между таблицами, превращая набор таблиц в цельную конструкцию — реляционную базу данных.
Приведу пример. Допустим, мы создали еще одну простую таблицу — справочник товаров. Назовем ее GOODS.
| Товарный справочник GOODS | ||||
| ID | NAME | PRICE | UNIT | COUNTRY |
| 1 | Яблоки | 50.00 | кг | Россия |
| 2 | Груши | 60.40 | кг | Франция |
| 3 | Апельсины | 40.00 | кг | Марокко |
| 4 | Макароны | 21.00 | шт | Франция |
| 5 | Кефир | 25.30 | шт | Россия |
| 6 | Молоко | 30.50 | шт | Россия |
Ее колонки: ID — первичный ключ, NAME — название товара, PRICE — его цена, UNIT — краткое название единицы измерения, COUNTRY — название страны-производителя.
Хорошо ли построена такая таблица? Вроде бы всем упоминавшимся выше принципам она удовлетворяет: уникальные имена столбцов с однородными данными, строки с уникальным первичным ключом. Казалось бы, все на месте. Тем не менее построена она непрофессионально. Здесь мы подходим к принципам, о которых я еще не упоминал, — к понятию о нормализации таблиц. Суть в том, чтобы всюду, где только можно, избегать избыточности в хранении данных путем выделения их в отдельные таблицы.
Посмотрим на нашу таблицу GOODS. Чем она плоха? Представьте себе, что завтра придется изменить название какой-нибудь страны. Такое случается часто. Бирма когда-то меняла свое название на Мьянму, Польша — на Польскую Республику. Хочется ли вам менять огромное количество строк во всех таблицах, где эти страны упоминаются? Представьте также, что вас попросят отобрать запросом весь штучный товар. Можете ли вы быть уверены в том, что оператор всюду набил эту аббревиатуру правильно и одинаково? Скорее всего, окажется, что в таблице встречаются все мыслимые вариации: «шт», «Шт», «шт.», «штук» и «штуки».
Думаю, проблема понятна. Выходом из этой ситуации будет выделение из нее двух других таблиц: справочника стран (COUNTRIES) и справочника единиц измерений (UNITS).
| Справочник единиц измерения UNITS | ||
| ID | NAME | SHORT_NAME |
| 1 | Штуки | шт |
| 2 | Килограммы | кг |
Сам справочник товаров GOODS будет теперь выглядеть совершенно по-другому (см. таблицу).
| Товарный справочник GOODS после нормализации | ||||
| ID | NAME | PRICE | UNIT_ID | COUNTRY_ID |
| 1 | Яблоки | 50.00 | 2 | 1 |
| 2 | Груши | 60.40 | 2 | 2 |
| 3 | Апельсины | 40.00 | 2 | 3 |
| 4 | Макароны | 21.00 | 1 | 2 |
| 5 | Кефир | 25.30 | 1 | 1 |
| 6 | Молоко | 30.50 | 1 | 1 |
Что изменилось? Вместо столбцов с названиями единиц измерения и стран появились столбцы UNIT_ID и COUNTRY_ID с кодами, отсылающими нас к другим таблицам. Это и есть внешние ключи. Что означает значение 2 в столбце UNIT_ID? Оно означает, что интересующая нас информация по единице измерения находится той строке таблицы UNITS, где ID = 2. Достаточно заглянуть в этот справочник, чтобы убедиться, что называется эта единица полностью «штуки», а кратко — «шт».
Объяснение всех видов и принципов нормализации выходит далеко за рамки данной статьи. Главное — почувствовать общие принципы. Единожды научившись строить базы данных правильно, вы уже не сможете иначе. Для этого не обязательно знать теорию в полном объеме — зачастую здравого смысла и интуиции бывает достаточно.
Вернемся к нашей маленькой базе данных. Ну хорошо, нормализовали мы таблицу. Сможем теперь менять названия стран, не исправляя всю таблицу. Замечательно. Но как теперь увидеть эти названия? Ведь в справочнике товаров появились коды, и таблица сразу потеряла свою наглядность.
Вот тут-то мы и подходим к понятию уже не раз упоминавшихся запросов, которые, используя связи, извлекают из них нужную информацию и выдают нам опять же в виде так называемой отчетной таблицы.
5 последних уроков рубрики «Разное»
-
Выбрать хороший хостинг для своего сайта достаточно сложная задача. Особенно сейчас, когда на рынке услуг хостинга действует несколько сотен игроков с очень привлекательными предложениями. Хорошим вариантом является лидер рейтинга Хостинг Ниндзя — Макхост.
-
Как разместить свой сайт на хостинге? Правильно выбранный хороший хостинг — это будущее Ваших сайтов
Проект готов, Все проверено на локальном сервере OpenServer и можно переносить сайт на хостинг. Вот только какую компанию выбрать? Предлагаю рассмотреть хостинг fornex.com. Отличное место для твоего проекта с перспективами бурного роста.
-
Создание вебсайта — процесс трудоёмкий, требующий слаженного взаимодействия между заказчиком и исполнителем, а также между всеми членами коллектива, вовлечёнными в проект. И в этом очень хорошее подспорье окажет онлайн платформа Wrike.
-
Подборка из нескольких десятков ресурсов для создания мокапов и прототипов.
SQL и NoSQL
abДва варианта представления данных
уплотнения
Масштабируемость
Тип хранилища данных
Сценарий использования
Пример
Рекомендации
Хранилище типа ключ-значение
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту.
Интерактивное обновление домашней страницы пользователя в Facebook.
Рекомендовано знакомство с технологией memcached.
Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы.
Хранилище, ориентированное на документы
Подходит для хранения объектов различных типов.
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет.
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости.
Система хранения данных с расширяемыми записями
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы.
Приложения, похожие на eBay
Вертикальное и горизонтальное разделение данных для хранения информации клиентов.
Для упрощения разделения данных используются HBase или Hypertable.
Масштабируемая RDBMS
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии.
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов.
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование.
этом
Виды баз данных
- Фактографическая – содержит краткую информацию об объектах некоторой системы в строго фиксированном формате;
- Документальная – содержит документы самого разного типа: текстовые, графические, звуковые, мультимедийные;
- Распределённая – база данных, разные части которой хранятся на различных компьютерах, объединённых в сеть;
- Централизованная – база данных, хранящихся на одном компьютере;
- Реляционная – база данных с табличной организацией данных;
- Неструктурированная (NoSQL) — база данных, в которой делается попытка решить проблемы масштабируемости и доступности за счёт атомарности (англ. atomicity) и согласованности данных, но не имеющих четкой (реляционной) структуры.
Одно из основных свойств БД – независимость данных от программы, использующих эти данные. Работа с базой данных требует решения различных задач, основные из них следующие:
- создание базы;
- запись данных в базу;
- корректировка данных;
- выборка данных из базы по запросам пользователя.
Задачи этого списка называются стандартными.
Следующее понятие, связанное с базой данных: программа для работы с базой данных – это программа, которая обеспечивает решение требуемого комплекса задач. Любая подобная программа должна уметь решать все задачи стандартного набора.
База данных в разных системах имеет различную структуру.
В ПВЭМ обычно используются реляционные БД – в таких базах файл является по структуре таблицей. В ней столбцы называются полями, строки – записями.
В БД содержатся банные некоторого множества объктов. Каждая запись содержит данные одного объекта. Каждая такая БД определяется именем файла, списком полей, шириной полей. Например, БД Школа (Ученик, Класс, Адрес).
Примером БД может служить расписание движения поездов или автобусов. Здесь каждая строчка – запись отражает данные строго одного объекта. База включает поля: номер рейса, маршрута следования, время отправления и т.д.
Классическим примером БД является и телефонный справочник. Запрос к базе данных – это предписание, указывающее, какие данные пользователь желает получить из базы.
Некоторые запросы могут представлять собой серьёзную задачу, для решения которой потребляется составлять сложную программу. Например, запрос к базе – автобусному расписанию: определить разницу в среднем интервале отправления автобусов из Ростова в Таганрог и из Ростова в Шахты.
Объекты для работы с базами данных
Для создания приложения, позволяющего просматривать и редактировать базы данных, нам потребуется три звена:
- набор данных
- источник данных
- визуальные элементы управления
В нашем случае эта триада реализуется в виде:
- Table
- DataSource
- DBGrid
Table подключается непосредственно к таблице в базе данных. Для этого нужно установить псевдоним базы в свойстве DataBaseName и имя таблицы в свойстве TableName, а затем активизировать связь: свойство .
Однако, поскольку Table является невизуальным компонентом, хотя связь с базой и установлена, пользователь не в состоянии увидеть какие – либо данные. Поэтому необходимо добавить визуальные компоненты, отображающие эти данные. В нашем случае это сетка DBGrid. Сетка сама по себе «не знает», какие данные ей нужно отображать, её нужно подключить к Table, что и делается через компонент – посредник .
А зачем нужен компонент – посредник? Почему бы сразу не подключаться к Table?
Допустим, несколько визуальных компонентов – таблица, поля ввода и т.п. подключены к таблице. А нам нужно быстро переключить их все на другую подобную таблицу. С DataSource это сделать несложно — достаточно просто поменять свойство t, а вот без пришлось бы менять указатели у каждого компонента.
Приложения баз данных – нить, связывающая БД и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table(таблица, навигационный доступ)
- Query(запрос, реляционный доступ)
Визуальные компоненты:
- Сетки DBGrid, DBCtrlGrid
- Навигатор DBNavigator
- Всяческие аналоги Lable, Editи т.д.
- Компоненты подстановки
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели. Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц. Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц). Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога. Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов. Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel). Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация. В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы. Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно. Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение. А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой. Что это за связи? Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации. В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными. Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов. В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот! Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Это интересно: Трудовая книжка
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Пожалуйста, оставляйте ваши отзывы по текущей теме статьи. За комментарии, отклики, дизлайки, лайки, подписки низкий вам поклон!
1 Анализ предметной области
Зачастую, кинотеатр состоит из нескольких залов разной конфигурации, а посетителю предоставляется возможность выбора билета, для этого ему отображается текущее состояние зала. Выбранные места посетитель сообщает кассиру, который вводит их в систему и места помечаются как «проданные». Это «основной» сценарий использования информационной системы, однако надо учесть следующее:
- репертуар и расписание проката кинотеатра должен кто-то вносить в систему — соответствующую роль назовем «Менеджер»;
- посетитель и кассир должны иметь возможность просматривать расписание, при этом интересно расписание, начиная с некоторого момента времени (например, текущего времени). Составлять оно может по-разному:
- расписание показа всех фильмов, упорядоченное по времени;
- расписание прокатов в отдельных залах кинотеатра;
- расписание проката определенного фильма.
Из этого описания понятны основные функции системы, изображенные на рисунке с помощью нотации диаграммы прецедентов UML. На диаграмме не отображена роль администратора базы данных, так как администратор обычно взаимодействует с системой не через интерфейс, а через выполнение SQL-запросов.
Несмотря на то, что мы не будет разрабатывать интерфейс информационной системы и текстовые описания прецедентов, дальше нас будут интересовать данные, необходимые для выполнения того или иного прецедента, а для этого надо выделить и описать сущности. Иначе, невозможно определить «какие данные должен вводить менеджер при добавлении фильма». Основные сущности, данные которых потребуются во время работы, показаны на рисунке, при этом используется нотация диаграммы классов UML. Каждый прямоугольник соответствует одной сущности, внутри записаны поля и типы данных.
Каждая сущность, кроме hall_row содержит поле id, которое идентифицирует объект. У сущности hall_row поле id не нужно, так как в одном и том же зале кинотеатра (id_hall) не могут повторяться номера рядов (number).
Когда пользователь выберет зал и прокат — система должна отобразить заполненность зала, при этом надо отобразить конфигурацию зала с пометкой занятых и свободных мест. Под конфигурацией зала тут имеется ввиду, что разные залы имеют разный размер, а ряды зала могут иметь различное количество мест. Поэтому в базе данных зал (hall) составляется из рядов (hall_row), одним из параметров которых является вместимость (capacity).
Достоинства документных баз
- Позволяют хранить объекты с разной структурой.
- Могут отображать почти все структуры данных, включая объекты на основе ООП, списки и словари, используя старый добрый JSON.
- Несмотря на то, что NoSQL не схематичны по своей природе, они часто поддерживают проверку схемы. Это значит, что вы можете сделать коллекцию со схемой. Эта схема не будет простой, как таблица: это будет JSON схема со специфическими полями.
- Запросы к NoSQL очень быстрые — каждая запись независима и, следовательно, время запроса не зависит от размера базы. По той же причине эта БД поддерживает параллельность.
- В NoSQL масштабирование БД осуществляется добавлением компьютеров и распределением данных между ними, этот метод называется горизонтальное масштабирование. Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
Особенности реляционных баз
Основные особенности реляционных баз можно сформулировать так:
- Все данные представлены в виде набора простых таблиц (двумерных массивов), разбитых на строки и столбцы, на пересечении которых расположены данные.
- У каждого столбца есть имя, уникальное в пределах таблицы, причем все значения в одном столбце — однородны, т.е. имеют один тип.
- Каждая строка имеет одно или несколько полей, набор значений в которых уникален в пределах таблицы. Этот набор называется первичным ключом (primary key) и служит для идентификации строки. Этот принцип не допускает, в частности, хранение в таблице совершенно одинаковых строк.
- Имя таблицы, имя столбца и первичный ключ однозначно определяют хранимый элемент данных.
- Строки в реляционной базе данных не упорядочены. Упорядочивание производится в момент формирования ответа на запрос.
- Запросы к базе данных возвращают результат в виде таблиц, которые также могут выступать как объект для новых запросов.
Чтобы такое изложение не воспринималось скучным и сложным, приведу поясняющий пример. Вот простая таблица — справочник стран. Назовем ее COUNTRIES.
| Справочник стран COUNTRIES | |
| ID | NAME |
| 1 | Россия |
| 2 | Франция |
| 3 | Марокко |
| 4 | Япония |
В таблице COUNTRIES всего два столбца:
- ID — код страны;
- NAME — ее название.
Столбец ID служит первичным ключом таблицы, а столбец NAME содержит ту полезную информацию, которую мы и будем стремиться извлекать запросами. Все данные столбца ID — целочисленны, столбца NAME — содержат текстовую информацию.
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных. Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
- Redis
- Memcached
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:
Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:
Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:
В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например: