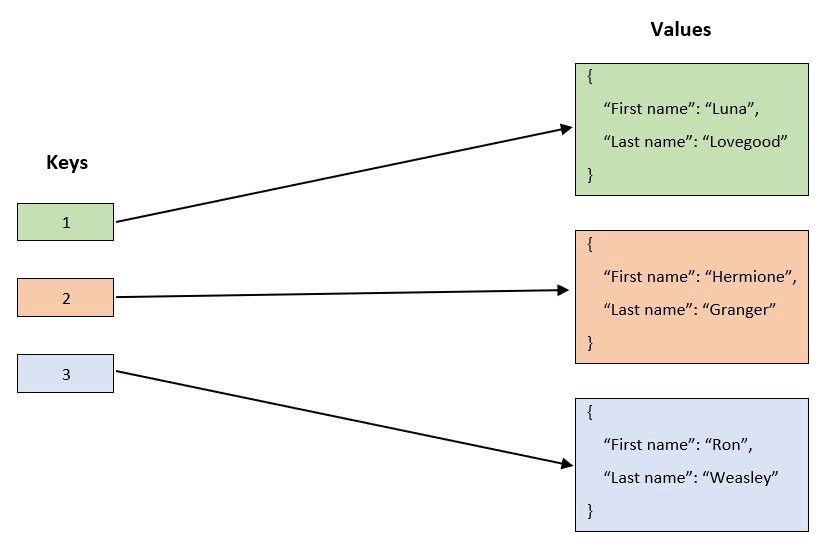
Шестая нормальная форма (6nf) базы данных
Содержание:
- Пример приведения таблицы ко второй нормальной форме (первичный ключ составной)
- Лекция № 10. Нормальные формы
- Чтобы привести базу к третьей нормальной форме, надо:
- Пятая нормальная форма
- Демормализация в базе данных: «звезда» и «снежинка»
- Цель нормализации
- Логическое (даталогическое) проектирование
- Атомарность атрибутов
- Взаимодействие с клиентами при выполнении проектов
- Нормализация и стандартизация — методы шкалирования данных
- Нормализация данных: методы и формулы
- Нормализация НСИ Контрагенты
- Многозначные зависимости
- Normalizer: применение нормализации к строкам
- Заключение
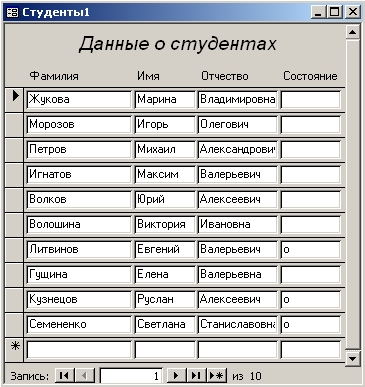
Пример приведения таблицы ко второй нормальной форме (первичный ключ составной)
А теперь давайте рассмотрим другую ситуацию, в которой первичный ключ у нас будет составным.
Представим, что наша организация выполняет несколько проектов, в которых может быть задействовано несколько участников, и нам необходимо хранить информацию об этих проектах. В частности мы хотим знать, кто участвует в каждом из проектов, продолжительность этого проекта, ну и возможно какие-то другие сведения. При этом мы понимаем, что отдельно взятый сотрудник может участвовать в нескольких проектах.
Для хранения таких данных мы создали следующую таблицу.
Таблица проектов организации в первой нормальной форме.
| Название проекта | Участник | Должность | Срок проекта (мес.) |
| Внедрение приложения | Иванов И.И. | Программист | 8 |
| Внедрение приложения | Сергеев С.С. | Бухгалтер | 8 |
| Внедрение приложения | John Smith | Менеджер | 8 |
| Открытие нового магазина | Сергеев С.С. | Бухгалтер | 12 |
| Открытие нового магазина | John Smith | Менеджер | 12 |
Как видим, она в первой нормальной форме, значит, мы можем пытаться приводить ее ко второй нормальной форме.
Как Вы помните, чтобы привести таблицу ко второй нормальной форме, необходимо определить для нее первичный ключ.
Посмотрев на эту таблицу, мы понимаем, что четко идентифицировать каждую строку мы можем только с помощью комбинации столбцов, например, «Название проекта» + «Участник», иными словами, зная «Название проекта» и «Участника», мы можем четко определить конкретную запись в таблице, т.е. каждое сочетание значений этих столбцов является уникальным.
Таким образом, мы определили первичный ключ и он у нас составной, т.е. состоящий их двух столбцов.
Таблица проектов организации. Внедрен составной первичный ключ.
| Название проекта | Участник | Должность | Срок проекта (мес.) |
| Внедрение приложения | Иванов И.И. | Программист | 8 |
| Внедрение приложения | Сергеев С.С. | Бухгалтер | 8 |
| Внедрение приложения | John Smith | Менеджер | 8 |
| Открытие нового магазина | Сергеев С.С. | Бухгалтер | 12 |
| Открытие нового магазина | John Smith | Менеджер | 12 |
Так как первичный ключ составной, нам необходимо проверить еще и второе требование, которое гласит, что «Все неключевые столбцы таблицы должны зависеть от полного ключа».
Другими словами, остальные столбцы, которые не входят в первичный ключ, должны зависеть от всего первичного ключа, т.е. от всех столбцов, а не от какого-то одного.
Чтобы это проверить, мы можем задать себе несколько вопросов.
Можем ли мы определить «Должность», зная только название проекта? Нет. Для этого нам необходимо знать и участника. Значит, пока все хорошо, по этой части ключа мы не можем четко определить значение неключевого столбца. Идем дальше и проверяем другую часть ключа.
Можем ли мы определить «Должность» зная только участника? Да, можем. Значит наш первичный ключ плохой, и требование второй нормальной формы не выполняется.
Что делать в этом случае?
В этом случае мы будем выполнять действие, которое выполняется, наверное, в 99% случаев на протяжении всего процесса нормализации базы данных – это декомпозиция.
Чтобы декомпозировать нашу таблицу и привести базу данных к нормализованной форме, мы должны создать следующие таблицы.
Проекты.
| Идентификатор проекта | Название проекта | Срок проекта (мес.) |
| 1 | Внедрение приложения | 8 |
| 2 | Открытие нового магазина | 12 |
Участники.
| Идентификатор участника | Участник | Должность |
| 1 | Иванов И.И. | Программист |
| 2 | Сергеев С.С. | Бухгалтер |
| 3 | John Smith | Менеджер |
Связь проектов и участников этих проектов.
| Идентификатор проекта | Идентификатор участника |
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 2 |
| 2 | 3 |
Мы создали 3 таблицы:
- Проекты, в нее мы добавили искусственный первичный ключ
- Участники, в нее мы также добавили искусственный первичный ключ
- Связь между проектами и участниками, она нужна для реализации связи «Многие ко многим», так как между этими таблицами связь именно такая
После того как мы привели таблицы базы данных ко второй нормальной форме, мы можем переходить к приведению таблиц до третьей нормальной формы (3NF). Описание, требования и пример приведения таблиц до третьей нормальной формы мы рассмотрим в следующем материале.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Нравится85Не нравится
Лекция № 10. Нормальные формы
(Причем каждый из атрибутов А и В может состоять из одного или нескольких атрибутов.)
Функциональная зависимость является смысловым (или семантическим) свойством атрибутов отношения. Семантика отношения указывает, как его атрибуты могут быть связаны друг с другом, а также определяет функциональные зависимости между атрибутами в виде ограничений, наложенных на некоторые атрибуты.
Зависимость между атрибутами А и В можно схематически представить в виде диаграммы, показанной на рисунке 5.
Детерминант — детерминантом функциональной зависимости называется атрибут или группа атрибутов, расположенная на диаграмме функциональной зависимости слева от символа стрелки.
|
А |
Атрибут В функционально зависит от атрибута А |
В |
Рисунок 5 — Диаграмма функциональной зависимости
При наличии функциональной зависимости атрибут или группа атрибутов, расположенная на ее диаграмме слева от символа стрелки, называется детерминантом (determinant). Например, на рис. 6.1 атрибут А является детерминантом атрибута В.
Чтобы привести базу к третьей нормальной форме, надо:
1. Определить, в каких полях каких таблиц имеется взаимозависимость. Как только что говорилось, поля, которые зависят больше друг от друга (как город от штата), чем от ряда в целом. В базе форума такой проблемы нет. Взглянув на таблицу сообщений, увидите, что каждый заголовок, каждое тело сообщения относится к своему message ID.
2. Создайте соответствующие таблицы. Если есть проблемный столбец в шаге 1, создавайте раздельные таблицы для него. Как города и штаты, в примере с клиентами.
3. Создайте или выделите первичные ключи. Каждая таблица должна иметь первичный ключ. Для примера с клиентами это будут city ID и state ID.
4. Создайте необходимые внешние ключи, которые образуют любое из отношений. В нашем примере нужно добавить state ID в таблицу городов и city ID в таблицу клиентов. Это свяжет каждого клиента с городом и штатом, где они живут.
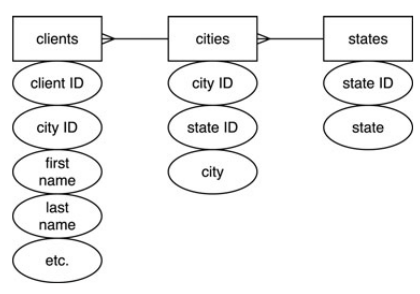
Рассмотренная в качестве примера база данных с записями о клиентах, созданы две новых таблицы для хранения информации о городах и штатах.
Подсказки:
Вообще, можно было бы и не нормализовывать базу с клиентами до такой степени. Если оставить города и штаты в таблице клиентов, самое страшное, что могло бы случиться — если бы город изменил название, нужно было бы менять его во всех записях о клиентах, которые живут в этом городе. Но города редко меняют свои имена.
Несмотря на то, что имеются правила как нормализовывать базы данных, разные люди сделают это разными способами. Проектирование баз данных допускает личные предпочтения и интерпретации
Важно, чтобы в базе не было явных нарушений нормальных форм, которые могут привести в дальнейшем к проблемам
Пятая нормальная форма
Таблицу, находящуюся в четвертой нормальной форме и, казалось бы, уже нормализованную до предела, в некоторых случаях еще можно бывает разбить на три или более (но не на две!) таблиц, соединив которые, мы получим исходную таблицу. Получившиеся в результате такой, как правило, весьма искусственной, декомпозиции таблицы и называют находящимися в пятой нормальная форме. Формальное определение пятой нормальной формы таково: это форма, в которой устранены зависимости соединения. В большинстве случаев практической пользы от нормализации таблиц до пятой нормальной формы не наблюдается.
Такая вот теория… Разработаны специальные формальные математические методы нормализации таблиц реляционных баз данных. На практике же толковый проектировщик баз данных, детально познакомившись с предметной областью, как правило, достаточно быстро набросает структуру, в которой большинство таблиц находятся в четвертой нормальной форме:).
Демормализация в базе данных: «звезда» и «снежинка»
Как можно понять из вышеприведённых примеров, основными целями нормализации являются:
- устранение избыточности при хранении данных, приводящей к увеличению размера БД;
- исключение необходимости модификации данных в связных таблицах для минимизации времени и операций, проводящихся в одной транзакции. Или, как выражаются специалисты, уменьшить толщину транзакции, потому что толстые транзакции мешают при многопользовательской работе взаимными блокировками и увеличением времени отклика системы. Речь об этом пойдёт в отдельной главе.
Но список заявленных целей касается приложений транзакционных.
В приложениях интерактивной аналитической обработки приоритет меняется: на первый план выходит время отклика системы, в ущерб которому данные могут быть избыточны.
Цель нормализации
Нормализация — метод создания набора отношений с заданными свойствами на основе требований к данным, установленным в некоторой организации.
Нормализация часто выполняется в виде последовательности тестов для некоторого отношения с целью проверки его соответствия (или несоответствия) требованиям заданной нормальной формы.
Процесс нормализации является формальным методом, который позволяет идентифицировать отношения на основе их первичных ключей (или потенциальных ключей, как в случае НФБК) и функциональных зависимостей, существующих между их атрибутов. Проектировщики баз данных могут использовать нормализацию в виде наборов тестов, применяемых к отдельным отношениям с целью нормализации реляционной схемы до заданной конкретной формы, что позволит предотвратить возможное возникновение аномалий обновления.
Основная цель проектирования реляционной базы данных заключается в группировании атрибутов и отношения так, чтобы минимизировать избыточность данных и таким образом сократить объем памяти, необходимый для физического хранения отношений, представленных в виде таблиц.
Логическое (даталогическое) проектирование
- Логическое проектирование
- создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Переход от ER-диаграмм к ФЗ
ER-диаграммы вполне естественным образом могут быть преобразованы к ФЗ.
Каждая сущность подразумевает ФЗ неключевых атрибутов от ключевых, поскольку значения ключевых атрибутов однозначно определяют значения остальных – иначе, значения неключевых атрибутов есть (вообще говоря, дискретная) функция от значений ключевых атрибутов.
Связи двух сущностей типа один-к-одному устанавливают взаимно-однозначное соответствие между сущностями, то есть взаимные ФЗ между ключами сущностей. Атрибуты самой связи функционально зависят от всех ключей входящих в связь сущностей.
Связи двух сущностей типа один-ко-многим и многие-к-одному естественным образом моделируют функциональную зависимость между ключевыми атрибутами соответствующих сущностей: в левой части ФЗ находятся ключевые атрибуты сущности, входящей в связь многократно, а в правой – ключевые атрибуты сущности, входящей в связь однократно, а так же атрибуты самой связи (если есть). Можно сказать, что ФЗ моделирует связь типа многие-к-одному.
Это же рассуждение естественным образом обобщается на многозначные связи: каждая из однократно входящих в связь сущностей (точнее, ее ключи) функционально зависят от всех многократно входящих в связь сущностей. То же самое можно сказать об атрибутах самой связи.
Наконец, связь типа многие-ко-многим можно рассматривать как частный случай многозначной связи: все атрибуты связи функционально зависят от всех ключевых атрибутов связанных сущностей.
Таким образом:
- Каждая сущность \(E\) преобразуется к ФЗ вида \ где \(K_E\) – множество ключевых (идентифицирующих) атрибутов сущности \(E\), а \(A_E\) – множество всех атрибутов сущности \(E\).
- Каждая связь \(R\) между сущностями \(E_1,\ldots,E_n\), входящими в связь многократно и \(S_1,\ldots,S_m\), входящими в связь однократно, преобразуется к ФЗ вида \ где \(K_i\) – ключи соответствующих сущностей, \(A_R\) – атрибуты связи, и ФЗ вида \.
Следует сделать одно важное замечание: если связь многие-ко-многим (возможно многозначная) не имеет атрибутов, то она даст исключительно тривиальные функциональные зависимости. Это, как правило, нежелательно, поскольку при формальном анализе в итоге приведет к потере этой связи
Это связано с тем, что связь многие-ко-многим является нефункциональной зависимостью. Решением этой проблемы может быть ввод фиктивного атрибута с пустым доменом, скажем, \(\theta\), уникального для данной связи. Это позволит формально анализировать функциональные зависимости для – фактически – неопределенной функции.
Диаграммы атрибутов
Кроме непосредственной записи ФЗ в столбик, существует более наглядный способ представления ФЗ отношений. Он так же может использоваться для нормализации отношения по крайней мере до 3НФ.
Диаграммы атрибутов строятся следующим образом. В овалах записываются все атрибуты данной предметной области, и между ними рисуются стрелки, соответствующие ФЗ, присутствующим в системе. В случае наличия составных левых частей ФЗ, вводятся промежуточные узлы, обозначаемые точкой.
Например, построим диаграмму атрибутов для нашего примера с теннисными кортами.
Использование диаграмм атрибутов позволяет достаточно просто обнаруживать транзитивные зависимости и выделять отдельные отношения методом простой группировки связанных узлов (атрибутов).
В качестве примера, выделим на этой диаграмме отношения. Сначала выделим все возможные ключевые атрибуты по следующему признаку: если какой-либо атрибут функционально зависит от данного, то данный атрибут является ключевым.
Теперь для каждого ключевого атрибута выделим его и все атрибуты, непосредственно зависящие от него, в отдельную группу.
Это позволит нам выделить группы атрибутов, не имеющие транзитивных зависимостей, в которых все неключевые атрибуты зависят от потенциального ключа.
Двойной линией обозначены внешние ключи.
Несложно заметить, что каждая из выделенных групп является отношением в 3НФ.
Атомарность атрибутов
Вопрос об атомарности атрибутов решается на основе семантики данных, то есть их смыслового значения. Атрибут атомарен, если его значение теряет смысл прилюбом разбиении на части или переупорядочивании. Следовательно, если какой-либо способ разбиения на части не лишает атрибут смысла, то атрибут неатомарен.
Одно и то же значение может быть атомарным или неатомарным в зависимости от смысла этого значения. Например, значение «4286» является
атомарным, если его смысл — «пин-код кредитной карты» (при разбиении на части или переупорядочивании смысл теряется)
неатомарным, если его смысл — «набор цифр» (при разбиении на части или переупорядочивании смысл не теряется)
Хорошим способом принятия решения о необходимости разбиения атрибута на части является вопрос: «будут ли части атрибута использоваться по отдельности?». Если да, то атрибут следует разделить (но так, чтобы сохранились осмысленные части атрибута). Далее необходимо снова задаться тем же вопросом для новой структуры и так до тех пор, пока не останется атрибутов, допускающих разбиение.
Примеры неатомарного атрибута, часто встречающиеся на практике: составные поля в виде строки идентификаторов, разделенных, скажем, запятыми: 100, 32, 168, 1045.
Взаимодействие с клиентами при выполнении проектов
Мы открыты в выполнении проектов перед нашими клиентами и стараемся придерживатьcя передовых подходов в том числе и при взаимодействии с клиентами при выполнении проектов.
Нашим клиентам по проектам Нормализации мы предоставляем доступ к личному кабинету через WEB-интерфейс. В личном кабинете сотрудники клиента в режиме реального времени видят текущее состояние выполнения работ. Также этот инструмент используется для выполнения согласования клиентом результатов работ по нормализации.
Если же в силу каких-то причин использование WEB-интерфейсов нежелательно, то при выполнении проектов взаимодействие может вестись с применением табличных файлов Excel и электронной почты.
В отдельных случаях возможно выполнение проектов строго на территории исполнителя. Это актуально при выполнении работ с Оборонными и другими предприятиями специальных режимов.
Нормализация и стандартизация — методы шкалирования данных
Нормализация (normalization) и стандартизация (standardization) являются методами изменения диапазонов значений – шкалирования. Шкалирование особенно полезно в машинном обучении (Machine Learning), поскольку разные атрибуты могут измеряться в разных диапазонах, или значения одного атрибута варьируются слишком сильно. Например, один атрибут имеет диапазон от 0 до 1, а второй — от 1 до 1000. Для задачи регрессии второй атрибут оказывал бы большое влияние на обучение, хотя не факт, что он является более важным, чем первый. Нормализация и стандартизация отличаются своими подходами:
-
Нормализация подразумевает изменение диапазонов в данных без изменения формы распределения,
-
Стандартизация изменяет форму распределения данных (приводится к нормальному распределению).
Обычно достаточно нормализовать данные. Например, в глубоком обучении (Deep Learning) требуется перевести цвета изображений RGB из диапазона 0-255 к диапазону 0-1. А вот стандартизацию стоит применять при использование алгоритмов, которые основываются на измерении расстояний, например, k ближайших соседей или метод опорных векторов (SVM).
Нормализация данных: методы и формулы
Существует множество способов нормализации значений признаков, чтобы масштабировать их к единому диапазону и использовать в различных моделях машинного обучения. В зависимости от используемой функции, их можно разделить на 2 большие группы: линейные и нелинейные. При нелинейной нормализации в расчетных соотношениях используются функции логистической сигмоиды или гиперболического тангенса. В линейной нормализации изменение переменных осуществляется пропорционально, по линейному закону.
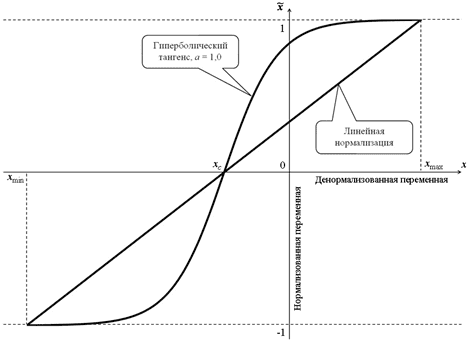
Графическая интерпретация линейной и нелинейной нормализации
На практике наиболее распространены следующие методы нормализации признаков :
- Минимакс – линейное преобразование данных в диапазоне , где минимальное и максимальное масштабируемые значения соответствуют 0 и 1 соответственно;
- Z-масштабирование данных на основе среднего значения и стандартного отклонения: деление разницы между переменной и средним значением на стандартное отклонение;
- десятичное масштабирование путем удаления десятичного разделителя значения переменной.

Формулы нормализации данных по методам минимакс и Z-масштабирование
На практике минимакс и Z-масштабирование имеют похожие области применимости и часто взаимозаменяемы. Однако, при вычислении расстояний между точками или векторами в большинстве случае используется Z-масштабирование. А минимакс полезен для визуализации, например, чтобы перенести признаки, кодирующие цвет пикселя, в диапазон .
Нормализация НСИ Контрагенты
В результате проведения работ по нормализации данных Контрагенты (Клиенты, Сотрудники, Поставщики, Пациенты, Кредиторы, Дебиторы и пр.) наши клиенты получают данные, соответствующие следующим критериям:
1. Все карточки Контрагентов заполнены полно и без ошибок в реквизитах
При выполнении работ по нормализации данных наши специалисты проверяют все карточки контрагентов, вносят исправления при необходимости и заполняют недостающие данные. При этом они используют как экспертные знания и специализированные методики, так и различные автоматизированные сервисы по проверке и нормализации данных.
В результате этого блока работ клиент получает выверенные, полностью заполненные данные контрагентов, которые можно использовать во всех сферах деятельности компании. Например, при оформлении договоров и построении отчетов, использующих информацию о контрагентах.
Рис. 5. Карточка контрагента до и после проведения нормализации.
2. Проведена дедубликация в карточках контрагентов
При выполнении нормализации всей НСИ Контрагенты путем применения специализированных алгоритмов находятся все дубли. Это избавляет домен данных от проблем с ведением всей деятельности по контрагентам в несколько параллельных веток с невозможностью получить точный срез взаимодействия с контрагентами, по которым присутствуют дубли в записях.
В результатах проекта клиенту предоставляются все позиции НСИ, которые являются дублями.
Эффекты от нормализации домена данных Контрагенты
Наши клиенты отмечают следующие позитивные эффекты:
- возможность ведения централизованной истории взаимодействия по каждому контрагенту без потерь информации;
- безошибочное построение любых отчетов, использующих информацию о контрагентах;
- избежание негативных ситуаций и попадания в «черные списки», например, при работе (e-mail рассылка, обзвон) с существующей клиентской базой, в которой один и тот же клиент, ввиду ошибок, присутствует n-ое количество раз.
Многозначные зависимости
Если заголовки столбцов в таблице реляционной базы данных разделены на три непересекающиеся группы X , Y и Z , то в контексте конкретной строки мы можем ссылаться на данные под каждой группой заголовков как x , y и z. соответственно. Многозначное зависимость X Y означает , что если мы выберем любое х на самом деле происходит в таблице (этот выбор х с ), а также составить список всех х с уг комбинации , которые происходят в таблице, мы обнаружим , что х с связано с одинаковыми записями y независимо от z . Таким образом, по сути, наличие z не дает никакой полезной информации для ограничения возможных значений y .
↠{\ displaystyle \ twoheadrightarrow}
Тривиальная многозначная зависимость Х Y является одним где либо Y представляет собой подмножество X , или Х и Y вместе образуют весь набор атрибутов отношения.
↠{\ displaystyle \ twoheadrightarrow}
Функциональная зависимость является частным случаем многозначной зависимости. В функциональной зависимости X → Y каждый x определяет ровно один y , а не более одного.
Normalizer: применение нормализации к строкам
Normalizer в PySpark необходим для нормализации не атрибутов (столбцов), а записей (строк) путем деления на p-норму . Общая формула выглядит так:
p_norm = sum(X**p) ** (1/p) X = X / p_norm
Единственным параметром в этом виде нормализации является , причём
-
если p=1, то p-норма равна сумме значений каждой строки;
-
если p=∞, то p-норма равна максимальному значению в каждой строке.
Следующий код на Python демонстрирует результат при p=1:
from pyspark.ml.feature import Normalizer
from pyspark.ml.linalg import Vectors
dataFrame = spark.createDataFrame(),),
(1, Vectors.dense(),),
(2, Vectors.dense(),)
], )
normalizer = Normalizer(inputCol="features", outputCol="normFeatures", p=1.0)
l1NormData = normalizer.transform(dataFrame)
print("Normalized using L^1 norm")
l1NormData.show()
#
Normalized using L^1 norm
+---+--------------+------------------+
| id| features| normFeatures|
+---+--------------+------------------+
| 0|| |
| 1| | |
| 2|||
+---+--------------+------------------+
В случае же p=∞ нормализация в PySpark приводит к другим результатам:
lInfNormData = normalizer.transform(dataFrame, {normalizer.p: float("inf")})
print("Normalized using L^inf norm")
lInfNormData.show()
#
Normalized using L^inf norm
+---+--------------+--------------+
| id| features| normFeatures|
+---+--------------+--------------+
| 0|||
| 1| | |
| 2|| |
+---+--------------+--------------+
Normalizer можно применять после атрибутивного шкалирования, о которых пойдёт речь дальше.
Заключение
Продолжать заниматься нормализацией можно и дальше: существуют 4NF, 5NF и DKNF (Domain Key Normal Form). Использование четырех уровней нормализации, рассмотренных в этой статье, является вполне достаточным в большинстве случаев проектирования баз данных. Таблицы могут быть нормализованы и до более высоких типов, но на практике это бывает не всегда возможно. Недостатком при стремлении к более высоким уровням нормализации является то, что таблицы могут быть разложены на более меньшие, чтобы отразить все возможные зависимости.
В результате получается, что даже для простого поиска по базе данных, требуется делать множество операций объединения таблиц. Это является слишком «дорогостоящей» процедурой и приводит к снижению производительности. Тем не менее, использовать четыре уровня нормализации баз данных, описанные в этой статье, не только желательно, но и необходимо в большинстве случаев.
Источник статьи — Источник статьи — http://www.developer.com/db/understanding-database-normalization.html